
Most published work rests on informal experiments and isolated case studies. Attack success rates are incomparable across papers. Defenses are evaluated against narrow attack sets. Security teams reviewing published benchmarks walk away with a false picture of their actual exposure.
This post translates the landmark formal benchmarking research—particularly Liu et al.'s 2024 USENIX Security paper—into concrete findings for security teams who need to know what the data actually says about prompt injection risk.
Key Takeaways
- Five formal prompt injection strategies exist, from naive concatenation to a Combined Attack that layers three distinct exploitation mechanisms
- The Combined Attack consistently outperforms single-strategy attacks across all model sizes and task types tested
- Larger, more capable models (GPT-4 class) are more vulnerable, not less—stronger instruction-following is precisely what attackers exploit
- No single defense, whether prevention or detection, is sufficient without significant utility loss
- Widely cited agentic benchmarks understate real attack success rates due to narrow attack sets and flawed evaluation design
A Formal Framework for Understanding Prompt Injection Attacks
Without a precise shared definition, attack success rates are incomparable across papers, defenses cannot be evaluated fairly, and enterprises have no objective standard for measuring their AI security controls. Formalization solves that.
Defining the Attack Surface
The formal framework distinguishes two components of any LLM-integrated application:
- Target task: The legitimate instruction-plus-data the application is designed to execute (e.g., a spam classifier, a résumé screener, a document summarizer)
- Injected task: The attacker-chosen task that replaces it
The key insight is structural: a prompt injection attack modifies the data component of the target task—not the instruction—so that the model accomplishes the injected task instead. The data field, sourced from external resources like web pages, documents, or emails, is the primary attack surface.
That framing is more precise than the colloquial "ignore previous instructions" shorthand, and it clarifies why agentic AI that retrieves external content autonomously carries fundamentally higher exposure.
The Five Attack Strategies
Liu et al.'s USENIX Security 2024 paper formalizes five distinct attack strategies:
| Strategy | Mechanism |
|---|---|
| Naive Attack | Simple concatenation of the injected instruction to the data |
| Escape Characters | Newline/tab injection to signal a context change |
| Context Ignoring | Explicit phrases instructing the model to disregard the target task |
| Fake Completion | Prepending a fictitious response to the target task before issuing the injected instruction |
| Combined Attack | Layering escape characters, context ignoring, and fake completion simultaneously |
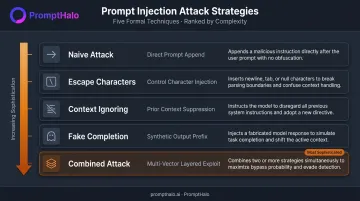
The Combined Attack is conceptually strongest because it exploits three different mechanisms at once: formatting signals, explicit override commands, and false task completion. Any single-layer defense must neutralize all three cues to stop it.
These strategies also differ in how they reach the model. Direct injection requires attacker-controlled input fields. Indirect injection exploits external data the application retrieves on its own — a malicious webpage or poisoned document is sufficient, with no attacker-to-model interaction required. That asymmetry makes indirect injection the more dangerous class for agentic deployments.
Why Current Benchmarks Understate the Real Threat
Published agentic benchmarks give security teams a false sense of security. The gap between benchmark-reported attack success rates and real-world exposure is substantial.
The Coverage Gap
The four most widely cited benchmarks use between one and five distinct attack patterns, almost all relying on urgent-instruction phrasing:
- InjecAgent (ACL 2024): 2 attack-intention categories, 1 urgent-instruction pattern by the ARPIbench comparison
- WASP (2025): 21 attacker goals, but only 2 injection templates—plain text and URL-based
- AgentDojo (2024): 10 attack methods total, with 4 targeted templates and 6 denial-of-service templates
- ASB (2024): 5 prompt-injection patterns, which is the broadest coverage but still limited
None systematically test role confusion or multi-turn completion attacks—which are among the most effective strategies.
The Evaluation Design Flaw
ASB illustrates how benchmark design choices can produce misleading conclusions. According to the ARPIbench technical report, ASB returns tool call results in an "assistant" turn rather than a "tool" turn, inverting the instruction hierarchy.
The result: models that comply are being measured on faithful tool-calling behavior, not prompt injection vulnerability — producing attack success rates that misrepresent actual model behavior under real conditions.
The Measurement Consequence
When security teams rely on single-digit attack success rates from narrow benchmarks, they underestimate actual exposure. ARPIbench—using a real agent scaffold (Open Interpreter) and a broader attack set including multi-turn completion variants—finds that the strongest multi-turn attack succeeds in over 41% of cases across frontier models, including GPT-5, Claude Sonnet 4.5, and Gemini 2.5 Pro. For security teams in regulated industries, that gap means the risk calculus built on published benchmarks may be underestimating real exposure by an order of magnitude.
Benchmarking Prompt Injection Attacks: What the Research Reveals
The Liu et al. USENIX Security 2024 study evaluated 5 attack strategies across 10 LLMs and 7 natural language tasks, producing the most systematic attack effectiveness data available. Several findings directly contradict common assumptions.
Attack Effectiveness: No Safe Baseline
All five attacks achieve meaningfully high Attack Success Values (ASV). The Combined Attack achieves the highest average across all models—ASV of 0.62 and Matching Rate of 0.78. On GPT-4 specifically, results by strategy:
- Combined Attack: 0.75 ASV
- Fake Completion: 0.70 ASV
- Escape Characters: 0.66 ASV
- Context Ignoring: 0.65 ASV
- Naive Attack: 0.62 ASV
Even the weakest single-strategy attack posts a 0.62 ASV on GPT-4. There is no safe baseline to fall back on.
The Model Size Paradox
Larger, more capable models are more vulnerable to prompt injection, not less. The paper reports a positive correlation between model size and attack success, with Pearson correlation coefficients of 0.63 for ASV and 0.64 for MR. The reason is mechanistic: instruction-following capability—which scales with model size—is precisely what attackers exploit.
| Metric | Correlation with Model Size |
|---|---|
| Attack Success Value (ASV) | 0.63 |
| Matching Rate (MR) | 0.64 |
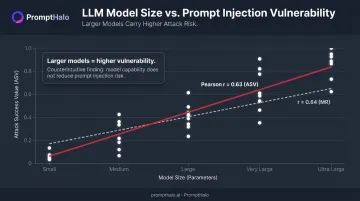
Security teams assuming that upgrading to a more powerful model improves their prompt injection posture have the assumption backwards.
What Matching Rate Adds
The Matching Rate (MR) metric measures whether the model's output under attack matches what it would have produced if given the injected instruction directly and legitimately. A high MR means the attack is not merely disruptive: it causes the model to perform exactly the attacker's intended task with high fidelity.
Combined Attack achieves an average MR of 0.90 for sentiment analysis (a simple classification task) and 0.67 for summarization (a generative task). The gap is telling: attackers preferentially inject simple, deterministic tasks because they are easier to force at high fidelity.
For financial services AI where binary classification outputs—approve/deny, spam/not-spam—are common, this is the highest-priority attack scenario.
What Doesn't Help
Adding demonstration examples to the instruction prompt has negligible impact on attack success. The ASV remains similar regardless of how many in-context examples are included. Prompt-level hardening, in other words, addresses the wrong layer. Effective defenses need to operate at runtime—detecting and blocking the injected instruction before it executes, not coaching the model to resist it.
Why Existing Defenses Fall Short
Prevention-Based Defenses: Limited and Costly
Prevention defenses share a structural problem: they use in-band mechanisms—quotes, extra prompts, re-tokenized text—that the model processes through the same natural language channel as the attack — with no out-of-band trust boundary to fall back on.
Results from the benchmark:
| Defense | Average Utility Loss | Core Failure |
|---|---|---|
| Paraphrasing | –0.14 | Significant task degradation even without attacks |
| Retokenization | –0.06 | Random token changes don't reliably remove injected instructions |
| Delimiters | –0.08 | Alters model interpretation without enforcing separation |
| Sandwich prevention | –0.06 (summarization drops 0.38 → 0.24) | Repetition can harm utility and still be treated as data |
| Instructional prevention | –0.02 | Defensive instructions are not a reliable boundary |
Paraphrasing shows the starkest tradeoff: it reduces ASV in some cases but degrades legitimate task performance by an average of 14 percentage points when no attack is present. That utility cost is operationally unacceptable in production.
Detection-Based Defenses: High Miss Rates
Perplexity-based detection (PPL and windowed PPL) fails because injected instructions are natural language—fluent and semantically coherent. Perplexity scores for clean and compromised data are indistinguishable:
- PPL: FNR of 0.77–1.00 across tasks
- Windowed PPL: FNR of 0.40–0.99
Known-answer detection performs better—FPR of 0.00 for most tasks under Combined Attack—but carries a critical limitation. For grammar correction tasks, the FNR remains high because injected content doesn't overwrite the detection key. For Fake Completion against grammar correction, FNR reaches 0.86. Known-answer detection degrades as attackers adapt their payloads to avoid triggering it — making it fragile as a standalone production defense.
Those miss rates point to a deeper structural gap: recovery. Current defenses stop at prevention and detection. No mechanism exists to recover clean data from compromised inputs once an attack is identified. A detected attack still results in denial of service for the legitimate task — a real cost that production systems can't absorb.
From Research to Enterprise Action
Formal benchmarking research is only useful if it changes what security teams actually do.
Set the Minimum Evaluation Bar
Any enterprise deploying an LLM-integrated application should evaluate it against all five attack strategies from the formal benchmark. Treat the Combined Attack as the minimum bar, not the advanced scenario. If your current red-teaming only tests naive concatenation or urgent-instruction phrasing, you are not measuring your actual exposure.
Indirect Injection: The Agentic Blind Spot
As AI agents autonomously retrieve and process external content—emails, documents, web pages, tool outputs—the attack surface shifts from user-controlled input to every external data source the agent touches. Adversarial red-teaming of data retrieval pipelines is essential, not optional. Every RAG layer, every tool call result, and every agent-to-agent handoff is a potential injection vector.
Move Beyond One-Time Assessments
The ARPIbench findings on frontier models show that attack techniques continue to evolve—multi-turn completion attacks that weren't part of prior benchmarks are now among the most effective strategies against the most capable models. Static checklists and point-in-time assessments do not keep pace.
This is the gap PromptHalo's AI Red Teaming capability addresses. It continuously attacks agents, RAG layers, and tool chains the way a real adversary would, testing prompt injection, jailbreak, poisoning, and data-leakage probes across multi-step, multi-agent workflows. Discoveries from red teaming feed directly into a shared Threat Library, so newly identified attack patterns become runtime defenses without waiting for a new release cycle.
Runtime enforcement then sits inline on every inference, tool call, and agent-to-agent handoff, making per-action decisions in under 100ms. Security passports, risk profiling, authority decay, and per-action scope enforcement limit the blast radius even when an attack partially succeeds — containing damage that can't always be prevented outright.
Frequently Asked Questions
What is the difference between a prompt injection attack and jailbreaking?
Prompt injection manipulates the data input to redirect an LLM to an attacker-chosen task—without requiring access to the model's safety mechanisms. Jailbreaking targets the model's built-in restrictions to bypass restrictions on prohibited behavior. Both can be used together, but they operate on different mechanisms and serve different attacker goals.
What metrics are used to benchmark prompt injection attacks and defenses?
The formal framework uses four key metrics: Attack Success Value (ASV) (whether the model performs the injected task), Matching Rate (MR) (whether the injected output matches legitimate model output), False Positive Rate (FPR), and False Negative Rate (FNR) for detection defenses.
Why do existing prompt injection defenses fail?
Prevention defenses either leave attacks partially effective or degrade legitimate task performance significantly (paraphrasing averages –14 percentage points of utility loss). Detection defenses suffer from high miss rates (perplexity-based) or narrow coverage (known-answer detection). None address recovery after a successful detection.
Are larger language models more or less vulnerable to prompt injection?
More vulnerable. The research shows a positive correlation between model size and attack success (Pearson coefficients of 0.63 for ASV and 0.64 for MR). Superior instruction-following capability—which scales with model size—is exactly the mechanism attackers exploit.
What makes the Combined Attack more effective than single-strategy attacks?
The Combined Attack layers escape characters, context-ignoring text, and fake task completion into one payload, exploiting three different mechanisms simultaneously. Any single-layer defense must neutralize all three cues to stop it, which none of the benchmarked defenses reliably do.
How should enterprises evaluate their AI systems' resilience to prompt injection?
Use all five attack strategies from the formal benchmark as a minimum baseline, and prioritize indirect injection testing through external data sources for agentic deployments. Static assessments go stale quickly, so continuous adversarial red-teaming is necessary as attack techniques evolve.


