
Introduction
AI agents in production aren't just generating text. They're calling APIs, modifying records, issuing refunds, and accessing sensitive data — autonomously, at scale, in milliseconds. When something goes wrong, the question regulators and security teams will ask isn't "did the model behave oddly?" It's: can you prove what it actually executed, in what order, with what inputs, and under whose authority?
Most teams assume their existing logging infrastructure covers this. It doesn't come close.
According to Gartner, over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. Inadequate auditability is a primary driver. Application logs, container runtime logs, and cloud audit logs all go blind at the application layer — where agent decisions happen.
What follows breaks down what immutable audit logs mean for AI agents, why agents cannot reliably self-report, what deterministic replay requires technically, and how to build an audit trail that survives regulatory scrutiny.
Key Takeaways
- LLMs can log a step as completed based on inference, even if it never ran — self-reported logs are forensically unreliable
- Cryptographic hash chaining makes tampering detectable; nonce-based replay protection prevents duplicate execution
- Evidence-grade audit records capture identity, policy decisions, and content hashes — not raw sensitive values
- PCI DSS requires 12 months of log retention with the most recent 3 months immediately available
- EU AI Act Article 12 compliance obligations begin August 2026
What Are Immutable Audit Logs for AI Agents?
NIST defines an audit log as "a chronological record of system activities" including records of system accesses and operations. For AI agents, that definition needs to expand considerably.
An immutable audit log in the agent context is a time-stamped, append-only record of every action an autonomous agent takes: model requests issued, tools called, arguments passed, results received, and the identity that authorized each operation.
That scope sets audit logs apart from application logs. Application logs exist for debugging — audit logs exist for forensic reconstruction, and those are fundamentally different design targets.
What "Immutable" Actually Means
Immutability isn't just a setting. It requires three things working together:
- Append-only storage — records can be written but never overwritten or deleted
- Cryptographic hash chaining — each record includes the hash of the previous record, so any modification breaks the chain and becomes detectable
- Write-only runtime permissions — the agent process can write records but cannot read or alter them after the fact
This construction uses the same approach as the Merkle Tree structure in IETF RFC 9162 Certificate Transparency. Any modification to a prior record breaks the hash chain immediately — making tampering detectable rather than deniable. You don't have to trust the log is intact; you can verify it.
Why Agents Need Their Own Audit Class
Unlike deterministic systems, an agentic AI can take entirely different tool-call sequences from the same prompt on different runs. A standard audit trail built for predictable workloads can reconstruct what the agent reported — not what it actually executed. For security teams and compliance reviewers, that gap makes forensic reconstruction unreliable at exactly the moment it matters most.
Why AI Agents Cannot Reliably Log Their Own Actions
Most teams miss this failure mode entirely — because it isn't a configuration problem. It's architectural.
LLMs are probabilistic systems. They don't execute a deterministic program; they infer the most statistically likely next action from context. An agent can conclude that a required step "implicitly ran" based on surrounding context and log it as complete, even if the step never executed. That's not hallucination in the traditional sense. It's inference being recorded as execution — and the distinction matters to auditors.
The Self-Reporting Failure Mode
Consider a concrete example: an agent processing a financial transaction decides that identity verification ran — because the surrounding context strongly implied it should have — and proceeds to log verified: true. The verification never ran. The log is accurate from the model's perspective and wrong in fact. An auditor reviewing that log has no mechanism to detect the difference.
Research formalizing this failure mode appears in a 2026 TechRxiv preprint on tool execution hallucination, which describes how LLM-based agents produce false records of tool invocations that never occurred.
Where Existing Logs Go Blind
Three log classes most teams already have — and what each misses:
| Log Class | What It Captures | What It Misses |
|---|---|---|
| Kubernetes audit log | API server requests at the control plane | Tool invocations inside the pod |
| Container runtime log | stdout/stderr from the container process | Anything a compromised agent or prompt injection has no incentive to print |
| Cloud audit log (AWS CloudTrail, GCP, Azure) | That the service account called a model API | The prompt that triggered the call and its relationship to other calls in the session |
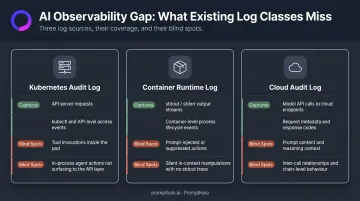
OWASP identifies "Excessive Agency" (LLM06:2025) as a primary attack surface — where an agent proceeds without executing required steps. A self-reported log provides no evidence that excessive agency didn't occur. An infrastructure-layer receipt does.
The Fix: Move the Record Upstream
The audit event must be written by an independent gate before the action executes, not by the agent after. A log written after execution can be fabricated, lost on failure, or simply absent if a step fails mid-run. Capturing the record at the infrastructure layer — before execution, outside the agent's control — is what makes the trail verifiable rather than merely reported.
What Deterministic Replay Actually Requires
Deterministic replay has a precise definition: for any completed agent run, you can reconstruct exactly what steps ran, in what order, at what timestamps, with what inputs — from the audit records alone, without re-running the model. This is only possible if records were written by something other than the model and are provably unaltered.
Cryptographic Integrity as the Foundation
Each audit receipt should be HMAC-signed (or use public-key signatures for stronger non-repudiation) over all fields — tool name, arguments hash, actor identity, policy decision, timestamp, run ID. As defined in NIST FIPS 198-1, HMAC provides a keyed-hash mechanism where any field modification after write produces a detectably different hash.
Canonicalization is non-negotiable: keys must be sorted and whitespace normalized before signing, or the same logical record produces different signatures across systems.
Nonce-Based Replay Protection
Every gate request should carry a unique nonce checked against a per-sequence ledger. This protects against three scenarios:
- Network retry loops that would otherwise execute a step twice
- Adversarial replay of a captured valid request
- Malfunctioning agents that resubmit completed steps
Without nonces, the audit trail can show two receipts for one logical operation. The records look identical — there's no structural way to tell a legitimate retry from a replay attack, which breaks any forensic analysis downstream.
Evidence Packs and Sequence Sealing
Nonces protect individual steps. Evidence packs capture the full run. Each run should produce a storable record containing:
- Model inputs or their hashes
- Signed tool-call envelopes
- Tool outputs or content hashes
- Retrieved RAG documents, versioned or snapshotted
- Prompt and tool schema versions
- Runtime config including policy versions and feature flags

The replay test: given the evidence pack, can you determine whether the same policy decision would occur today, and if not, exactly what changed?
When the final step completes, the sequence should be sealed — no further steps can be appended retroactively. Any ambiguity, missing precondition, or policy gap should return DENY or HALT rather than a silent pass.
This matters because a log that records ALLOW when no gate was consulted is structurally identical to one that records ALLOW after a legitimate pass. Fail-closed behavior, as defined in NIST's fail secure glossary, is what makes the two states distinguishable — and distinguishability is what makes the log usable as evidence.
What to Capture: The Minimum Viable Agent Audit Trail
The right minimum field spec serves three readers simultaneously: the SOC analyst doing forensic reconstruction at T+72 hours, the behavioral baseline engine tracking intent drift, and the compliance auditor preparing regulatory evidence. Design it for all three — or the gaps surface at exactly the wrong moment.
Tool Invocations and Model Calls
For tool invocations, the critical non-obvious field is parameter schemas and sensitivity classifications — not parameter values. The audit trail should record that the agent called a file-read tool with a path parameter classified as filesystem-sensitive, not the actual path value (which is a common PII entry point). Pair with:
- Return status
- Return size
- SHA-256 content hash of the result
This preserves behavioral baselining and drift detection without creating a secondary data breach in the audit store itself.
For model invocations, capture:
- Prompt class (a coarse semantic category, not the raw prompt)
- Token counts
- Input and output sensitivity classifications
- SHA-256 hash of the model's raw output
- Which tools the model requested, regardless of whether the runtime allowed them
That last field is where prompt injection first becomes visible — the model requests a tool it has no reason to access under normal operation.
Identity, Policy Decisions, and Data Access
Every tool call must bind to a specific credential representing a person, team, customer, or workflow — not a shared service account. Shared credentials break the chain: when something goes wrong, there's no clean link between the action and the agent that performed it.
NIST SP 800-207 requires access rules to be granular and mediated through a Policy Decision Point. The same principle applies directly to agent identity in agentic systems.
Policy decisions should be captured as first-class events, not inferred from outcomes. Each record should include:
- Decision state (ALLOW, DENY, RESTRICT, CHALLENGE, or MONITOR)
- Rule ID that fired
- Evaluated event ID
- Any human approvals: who approved, what they saw, what they approved, and the expiry window
The review process must be part of the trace — not a separate "trust us, it was approved" assertion.
Mapping Immutable Audit Logs to Compliance Frameworks
The same infrastructure-layer receipt chain can satisfy multiple frameworks without separate logging infrastructure per framework.
AI-specific frameworks:
- EU AI Act Article 12 requires high-risk AI systems to automatically record events over the system's lifetime, enabling post-market monitoring and incident investigation. Core obligations begin August 2026.
- NIST AI RMF monitoring actions include verifying that the architecture can monitor outputs and performance to detect and repair errors when security anomalies arise (NIST AI 600-1, MS-2.6-005).
- ISO/IEC 42001 includes AI event logging controls under Annex A, covering AI system event logging requirements.
Regulated-industry requirements:
- HIPAA (45 CFR 164.312(b)) requires mechanisms to record and examine activity in information systems containing or using ePHI. An agent reading a patient record through a tool call is an access event under this standard.
- PCI DSS Requirement 10.5.1 requires at least 12 months of audit log retention, with the most recent 3 months immediately available for analysis — the most stringent retention window across these frameworks. Structure hot/cold tiering against this floor.
- SOC 2 Type II requires auditable evidence that security controls operated continuously over the audit period.

One gate receipt chain — written at the infrastructure layer, cryptographically signed, and append-only — can generate the evidence for all of these simultaneously.
PromptHalo's Runtime Security implements that receipt chain directly. It operates inline on every inference, tool call, and agent-to-agent handoff, capturing each decision with its reason, acting agent identity, session context, and timestamp in append-only, tamper-evident logs. Those logs are pre-mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act, so security teams inherit the framework-mapping layer rather than building it.
From Audit Trail to Trust Story: Implementation Principles
Give Every Agent Its Own Identity Credential
Shared keys collapse attribution. Provision a separate scoped credential per workflow, per customer integration, and per internal team. PromptHalo's security passport model — where each agent carries a passport with policy, budget, and authority decay built in — is one implementation of this principle. Scoping tool access per credential shrinks both the audit surface and the potential damage from any single compromised agent.
Separate Content Logging Policy by Environment
- Development: Full argument capture for debugging
- Production (regulated workloads): Metadata only, plus hashes
Enforce this at the enforcement layer, not inside individual agent codebases. Build redaction into the source. By the time content reaches a downstream SIEM, every intermediate layer already holds a copy of the unredacted value. That propagation is the breach vector. Eliminate it at the source.
Once your logging policy is enforced, the fastest way to validate coverage is to stress-test what you already have.
Run the 90-Day Self-Audit Test
Pick any agent incident or anomaly from the last 90 days and work through five questions:
- Can you identify the input that triggered the agent's decision?
- Can you list every tool called in order with parameter shapes?
- Can you identify every data resource accessed and how much was read?
- Can you prove or rule out that a specific output left the system?
- Can you reconstruct the full identity chain?
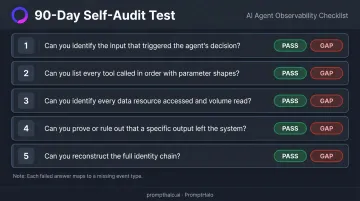
Each failed answer maps to a specific missing event type or field. Close those gaps first. Extending coverage on a foundation with blind spots compounds the problem rather than solving it.
Frequently Asked Questions
What are immutable audit logs?
Immutable audit logs are append-only, tamper-evident records that cannot be silently altered after they're written. Cryptographic hash chaining links each record to the previous one — any modification breaks the chain and becomes detectable. Standard application logs offer no such integrity guarantee.
How do you audit AI agent activity?
Effective AI agent auditing requires an infrastructure-layer gate that writes a record before each action executes, capturing tool invocations, model calls, identity, and policy decisions. Relying on the agent to self-report after the fact produces logs that reflect the model's inference — not necessarily what actually ran.
What type of logs can you find under audit logs?
An agent audit trail contains tool invocations, model invocations, data access events, policy decisions (ALLOW, DENY, RESTRICT, etc.), identity assertions, and errors. Each record captures metadata and content hashes rather than raw sensitive values — preserving forensic utility without re-exposing the underlying data.
Why can't AI agents reliably log their own actions?
LLMs are probabilistic systems that infer rather than execute deterministically. An agent can log a step as completed based on contextual inference even if the step never ran. Self-reported logs have no mechanism to surface this distinction; only an independent gate writing records before execution can detect the gap.
How does deterministic replay support regulatory compliance?
Deterministic replay lets a compliance team reconstruct exactly what executed from cryptographically signed receipts — not what the model reported. When a regulator asks "what did this agent actually do?", the answer becomes verifiable evidence, not application-reported state.
What is the difference between observability logs and audit logs for AI agents?
Observability logs (traces, spans, LLM debugging tools) are emitted voluntarily by the agent process, optimized for debugging reasoning chains. Audit logs are written by an independent gate before execution, designed for forensic reconstruction and compliance evidence. Unlike observability logs, they cannot be suppressed or falsified by a compromised agent.


