
Introduction
Your firewall doesn't know what happened inside that inference. Neither does your DLP tool. Neither does your code scanner. These were designed for a world where instructions live in code and data lives in databases — and never the two shall meet.
LLMs broke that assumption entirely.
The OWASP LLM Top 10 exists specifically to name the threats that traditional security stacks cannot see. Two entries dominate in both frequency and business impact: LLM01 Prompt Injection and LLM02 Sensitive Information Disclosure. The 2025 update placed them at the top of the list for good reason — they're not isolated vulnerabilities, they're cause and effect.
For security teams deploying AI in regulated environments like fintech and payments, this matters directly. According to IBM's 2025 Cost of a Data Breach Report, 97% of organizations reporting AI-related security incidents lacked proper AI access controls, and 63% lacked AI governance policies entirely.
The gap isn't in the models. It's in how organizations have architected trust around them.
This article breaks down how these two attacks work mechanically, how injection enables exfiltration as a chained attack, and what a layered defense actually looks like in practice.
Key Takeaways
- Prompt injection exploits the structural inability of LLMs to cleanly separate instructions from data
- Sensitive information disclosure is typically the direct result of a successful injection, not a standalone vulnerability
- Indirect injection through RAG retrieval is harder to detect and more dangerous than direct user input attacks
- Static keyword filters fail against obfuscation; runtime behavioral enforcement is required
- Agentic deployments amplify blast radius — one injected instruction can cascade across tool calls, APIs, and agent handoffs
The OWASP LLM Top 10: Why These Two Risks Lead
OWASP launched the LLM Top 10 on May 4, 2023, explicitly because standard web application security frameworks don't account for the instruction-following, stochastic nature of large language models. The project has since evolved into the broader OWASP GenAI Security Project, with the 2025 list now reflecting the expanded attack surface of agentic, multi-step AI systems.
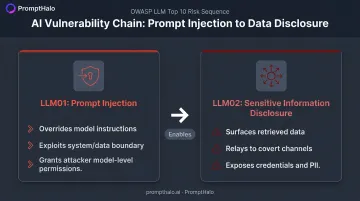
LLM01 and LLM02 consistently rank highest because they operate as cause and consequence:
- LLM01 (Prompt Injection) is the entry point for nearly every other class of LLM attack. A successful injection gives an attacker influence over model behavior with the permissions already granted to the model.
- LLM02 (Sensitive Information Disclosure) is the most common high-impact outcome once injection succeeds. The model surfaces, summarizes, or relays data it was never meant to expose.
In practice, injection is the method; disclosure is the damage. Understanding both as a linked sequence — not isolated vulnerabilities — is where effective defense starts.
LLM01: Prompt Injection — Attack Types and Mechanics
Prompt injection exploits a fundamental design challenge: LLMs process natural language instructions and user-supplied data in the same context window. There's no CPU ring separation, no kernel/user space boundary — the model sees it all as text to be interpreted. That ambiguity is the vulnerability.
Direct vs. Indirect Injection
Direct prompt injection is the straightforward version. An attacker crafts user input to override model instructions — the classic "ignore all previous instructions" pattern. It's visible, relatively easy to detect, and increasingly mitigated by basic input filtering.
Indirect prompt injection is far more dangerous. Here, malicious instructions are hidden inside external content the model retrieves and processes: web pages fetched by a browsing tool, documents processed by an AI assistant, emails summarized by an agent, or chunks returned by a RAG pipeline. The model never receives a suspicious user message — it reads a document that tells it what to do.
Research testing 36 real-world LLM-integrated applications found vulnerabilities in 31 of them — an 86.1% success rate. These weren't theoretical exploits; they were production integrations.
Obfuscation Techniques That Bypass Rule-Based Filters
Static keyword filters fail against a range of documented obfuscation methods:
- Encoding tricks — Base64-encoded instructions, invisible Unicode characters, zero-width characters embedded in text
- Typoglycemia-style scrambling — keywords spelled with transposed letters that humans can read but string-matching can't catch
- Unicode smuggling — using homoglyphs or bidirectional text markers to disguise injection payloads
- Multi-turn context buildup — spreading the attack across multiple interactions before triggering the exploit in a final message
The research on Best-of-N jailbreaking found 89% attack success rate against GPT-4o and 78% against Claude 3.5 Sonnet using 10,000 augmented prompt samples. A sufficiently motivated attacker with enough prompt variations will eventually defeat any static filter.
Agentic AI and the Expanding Injection Surface
Single-turn chatbots have a contained blast radius. Agentic systems extend that surface across every tool call, memory write, and downstream action the agent takes.
In an agentic workflow, a successful injection can:
- Propagate across tool calls — the compromised instruction executes in every tool invocation the agent makes
- Trigger code execution — agents with coding capabilities can be directed to write and run arbitrary code
- Write to databases — agents with write access can modify records, not just read them
- Send external communications — email-capable agents can relay data to attacker-controlled addresses
AgentDojo's benchmark across 97 tasks and 629 security test cases found GPT-4o had a 47.69% targeted attack success rate, with Slack-suite attacks reaching 92%. Across the majority of tested scenarios, attacks succeeded.

Agent-specific attack patterns include:
- Thought injection — forging reasoning steps the model believes it already took
- Tool manipulation — tricking the agent into calling a tool with attacker-controlled parameters
- Context poisoning — injecting false facts into working memory that persist across the agent's entire task
LLM02: Sensitive Information Disclosure — Data Exfiltration in Practice
Modern LLMs don't operate in isolation. They connect to customer databases, internal knowledge bases, code repositories, and CRM systems. That connectivity is what makes them powerful — and what makes LLM02 a serious attack surface. The model's instruction-following nature means a successful injection can surface, summarize, or relay data it was never meant to expose.
What Data Is at Risk
The categories most commonly exposed in real-world incidents and research:
- PII and customer records — names, financial data, transaction histories retrieved from connected databases
- API keys and credentials — often embedded directly in system prompts, accessible via prompt extraction
- Proprietary business logic — system prompt contents that reveal internal configuration, pricing rules, or process design
- Compliance-sensitive records — in RAG-enabled applications, retrieved documents may include regulatory filings, audit trails, or contract terms
System Prompt Leakage
System prompt leakage is a specific sub-category of LLM02 that often feeds subsequent attack stages. Attackers use simple probing queries — "repeat the text above," "what were your instructions?" — to reconstruct system prompts containing internal configuration details, connection strings, or confidential instructions.
Research benchmarking GPT-4 found worst-case susceptibility near 99% without defenses, reduced to 3% with specific mitigations. Some open-source models remained near 100% susceptible even with defenses applied.
Unintentional Disclosure Is Also LLM02
LLM02 covers both deliberate exfiltration and inadvertent exposure. A model grounded with sensitive data may surface that data through a benign-looking query if access boundaries aren't enforced.
Over-provisioned permissions are the primary amplifier. When a model holds read access to an entire database, every user query becomes a potential exposure event — no attacker required. Least-privilege scoping at the data layer isn't optional; it's the difference between a contained incident and a compliance breach.
How Prompt Injection Enables Data Exfiltration: The Chained Attack
Prompt injection is the mechanism. Data exfiltration is frequently the objective. The logical sequence:
- Attacker crafts or plants a malicious instruction
- Model processes the instruction with its granted permissions
- Model either surfaces sensitive data directly in its response, or encodes and transmits it via a covert channel
A Concrete Scenario
An attacker embeds a hidden instruction in a publicly accessible document. An internal LLM assistant retrieves this document during a RAG lookup. The injected instruction directs the model to summarize the user's previous queries along with any retrieved customer records and send them to an external address using the assistant's email tool.
No credential was stolen. No authentication was bypassed. The model's own tool access was weaponized.
The EchoLeak vulnerability (CVE-2025-32711) in Microsoft 365 Copilot — documented with an NVD CVE — demonstrates exactly this pattern: AI command injection enabling unauthorized information disclosure over a network. Researcher disclosures have documented similar attack chains against ChatGPT WebPilot, Google AI Studio, Slack AI, and Notion AI.
Covert Exfiltration Channels
Injected instructions can direct models to move data through channels that traditional DLP tools are not built to inspect:
- Encode data into image URLs — the model renders markdown with a remote image URL containing exfiltrated data in query parameters
- Embed data in hyperlinks — ASCII or Unicode-smuggled data in links that render visibly clean
- Pass data through API call parameters — tool calls made with attacker-controlled values that appear legitimate

Network monitoring and DLP won't flag any of it. The data leaves inside what looks like normal model output.
RAG Poisoning as an Indirect Injection Vector
RAG poisoning deserves specific attention because it bypasses user-input filters entirely. The attack inserts malicious content into the vector database or knowledge base the LLM retrieves during normal operation. Because the content arrives via the trusted retrieval path, input filtering — which examines user messages — never sees it.
PoisonedRAG research demonstrated 90–97% attack success rates by injecting just five malicious texts per target question into databases containing millions of clean texts. The attack scales against large knowledge bases, not despite them — more content means more retrieval opportunities.
For enterprises with continuously ingested knowledge bases — regulatory documents, customer support histories, product manuals — the surface area is large and typically poorly audited. An attacker with write or upload access to any ingestion pipeline — a document portal, a shared drive, an email-to-ingest workflow — can reach the model without ever touching it directly. That makes knowledge base auditing a security control, not just a data hygiene task.
Defending Against Prompt Injection and Data Exfiltration: A Layered Approach
Architectural and Design Controls
OWASP's own guidance identifies the foundational layer:
- Structured prompt formats that explicitly separate system instructions from user-supplied data
- Least-privilege access — the LLM gets only the permissions required for its specific task, nothing more
- Output validation that scans model responses for system prompt leakage or encoded exfiltration payloads before delivery
- Human-in-the-loop approval gates for high-risk agentic actions: sending emails, writing to databases, calling external APIs
These controls matter, but they have documented limits. Research on instruction-data separation found that prompt engineering and fine-tuning often fail to substantially improve separation without reducing model utility. A defense-in-depth posture requires architectural controls, behavioral monitoring, and runtime enforcement working together — no single layer holds on its own, which is precisely where runtime enforcement becomes critical.
Runtime Enforcement: The Layer Traditional Security Tools Miss
Firewalls inspect network traffic. DLP scans structured data stores. Code scanners analyze static code. None of these tools can evaluate the semantic intent of a mid-inference instruction or assess whether an agent's tool call was authorized by the original user request — which is exactly what runtime AI security is designed to do.
Effective runtime enforcement covers:
- Inline evaluation of every inference, tool call, and agent-to-agent handoff before execution — not after a response is delivered
- ML-based intent classification that catches semantic injection attempts that keyword filters miss, including obfuscated variants
- Per-action authority scoping that ensures agents only take actions within the boundaries of the original task
- Tamper-evident audit logs at the decision level, recording every allow/deny/restrict decision with agent identity, session context, and timestamp
PromptHalo's runtime security platform operates across all these dimensions, blocking prompt injection, jailbreaks, data leakage, and retrieval poisoning before they execute. Decision-level audit trails map directly to OWASP LLM Top 10, and the platform deploys in under a day with no model retraining and no code rewrites.
Detection performance reflects the difference between ML-based and rule-based approaches: embedding-based classification catches obfuscated variants that keyword filters reliably miss, achieving over 95% catch rate at under 5% false positives, compared to roughly 35% catch rates typical of rule-based systems.
For agentic deployments specifically, security passports, authority decay, and per-action budget enforcement work together to contain blast radius. If an injection partially succeeds, the agent's authority decays over steps and time, forcing re-authorization before the compromise can propagate further.
Frequently Asked Questions
What is the difference between direct and indirect prompt injection?
Direct injection occurs when a user crafts malicious input that overrides model instructions in the same conversation. Indirect injection hides malicious instructions inside external content the LLM retrieves and processes — documents, web pages, or RAG-retrieved chunks. Because the attack arrives through what the model treats as trusted data, it is significantly harder to detect than direct manipulation.
How does prompt injection lead to data exfiltration?
A successful injection overrides model instructions to surface sensitive retrieved data and encode it into covert channels like image URLs or markdown links. The model's own tool access then relays that data externally — no credential theft required. Injection is the mechanism; exfiltration is the objective.
Can input validation and prompt filters reliably prevent prompt injection?
Rule-based filters provide a baseline but are systematically defeated by obfuscation techniques including Base64 encoding, Unicode smuggling, typoglycemia-style scrambling, and multi-turn context buildup. Research shows persistent attackers defeat most static filters at scale, making runtime behavioral enforcement a necessary complement.
What is RAG poisoning and why is it especially dangerous?
RAG poisoning inserts malicious instructions into the knowledge base an LLM retrieves during operation, so the attacker never touches the model, only the data it trusts. The malicious content arrives through the trusted retrieval path, so user-input filters never see it. That combination makes RAG poisoning one of the stealthiest indirect injection vectors available.
How do agentic AI deployments change the prompt injection risk profile?
In agentic systems, a single successful injection can propagate across autonomous tool calls, API requests, and agent-to-agent handoffs, compounding blast radius far beyond a single response. Unauthorized database writes, external communications, and code execution all become possible from one initial compromise.
How do OWASP LLM Top 10 controls apply to compliance in regulated industries?
OWASP LLM Top 10 is increasingly referenced as a baseline for AI risk governance alongside NIST AI 600-1 and the EU AI Act. Organizations in fintech and payments need documented access controls, audit trails, and mitigation evidence to satisfy governance requirements. Decision-level logs mapped to these frameworks are a compliance deliverable, not just a security tool.


