
Introduction
LLMs are no longer experimental. They're embedded in production — processing financial transactions, powering internal knowledge workflows, and triggering real downstream actions. Gartner projects that by 2028, 25% of enterprise GenAI applications will experience at least five minor security incidents per year — and most teams aren't ready.
The core problem: LLMs interpret natural language dynamically, pull context from multiple sources at runtime, and increasingly execute real-world actions autonomously. That makes them a different attack surface than anything your existing security stack was designed to protect.
This guide breaks down what LLM security actually requires — the threat categories that matter, how layered defenses are architected, and what separates purpose-built solutions from security tools retrofitted for AI.
Key Takeaways
- LLM security spans models, APIs, and connected systems — covering prompt injection, data leakage, retrieval poisoning, and infrastructure abuse
- LLMs are probabilistic — their dynamic behavior makes WAFs, DLP tools, and perimeter defenses insufficient on their own
- Agentic AI (autonomous tool calls, RAG retrieval, multi-agent handoffs) is the fastest-expanding and least-protected attack surface in enterprise security
- Effective protection requires layered architecture: input controls, runtime enforcement, output validation, and continuous adversarial testing
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act set the baseline — but governance only works when paired with runtime enforcement
What Is LLM Security?
LLM security is the set of technologies, policies, and architectural controls designed to protect large language models and their surrounding ecosystems — including inference endpoints, retrieval layers, connected APIs, and agentic workflows — from misuse, compromise, and data exposure.
Unlike web application or API security, LLM security addresses an attack surface that is contextual and probabilistic. LLMs generate responses by weighting context across system prompts, user inputs, retrieval layers, memory state, and external data connections. That means there's no CVE to patch and no exploit signature to block.
That distinction shapes what LLM security actually covers:
- Prompt injection and instruction override
- Sensitive data leakage through model outputs
- Unauthorized API execution via connected tools
- Retrieval system manipulation and RAG poisoning
- Inference endpoint abuse and token exhaustion
- Agentic system exploitation across multi-agent workflows
Why LLMs Create a Fundamentally Different Security Challenge
Natural Language Becomes an Execution Vector
Traditional attacks exploit code flaws — SQL injection, buffer overflows, authentication bypass. Prompt injection exploits interpretation. Carefully crafted text can override system directives, extract hidden context, or manipulate downstream API calls without triggering a single code-level vulnerability.
OWASP confirms that prompt injections can be imperceptible to humans and still alter model behavior. There's no malformed packet to inspect. The attack is semantically valid text.
Outputs Can Trigger Real-World Actions
Modern enterprise LLMs connect to APIs, databases, workflow engines, and automation tools. A compromised interaction can write to a CRM, trigger emails, execute transactions, or modify files. The damage extends well beyond the chat interface.
Context Blending Increases Exposure
RAG systems combine models with vector databases containing internal documents, proprietary knowledge, and regulated data. Weak isolation boundaries allow adversarial prompts to retrieve and surface sensitive content that was never meant to appear in outputs. OWASP's LLM02:2025 covers this sensitive information disclosure risk explicitly.
Probabilistic Output Breaks Static Detection
Traditional security tools rely on pattern matching and deterministic rule enforcement. LLM outputs vary across sessions — the same input can produce different responses. Effective LLM threat detection requires analysis of behavioral signals and interaction patterns across sessions, not static keyword matching.
Agentic AI Compounds Every Risk
Gartner predicts that at least 15% of day-to-day work decisions will be made autonomously through agentic AI by 2028, up from essentially zero today. Autonomous agents operating with elevated permissions across multiple systems represent compounding risk — tool calls, memory reads, and cross-agent handoffs each introduce attack vectors that legacy defenses were never designed to inspect. That gap is exactly what purpose-built AI security needs to close.
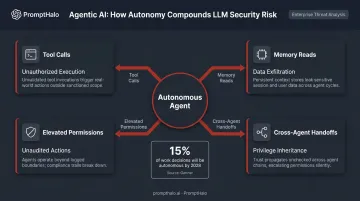
The Core LLM Threat Landscape
Prompt Injection and Jailbreaks
Prompt injection is the leading LLM threat. Attackers embed malicious directives in inputs to override system instructions, request hidden context, or manipulate downstream API calls.
OWASP distinguishes two variants:
- Direct injection — malicious instructions embedded in user-supplied prompts
- Indirect injection — adversarial content hidden in external sources the model processes: retrieved documents, emails, calendar invites, web pages
Indirect injection is harder to catch because it bypasses input-level controls entirely — the attack arrives through trusted retrieval paths, not user input fields. EchoLeak (CVE-2025-32711) is among the first documented zero-click prompt-injection exploits in a production LLM system — proof this is no longer theoretical.
Jailbreaks are a related but distinct threat: inputs crafted to bypass safety filters, impersonate alternate personas, or make models ignore guardrails. These evolve continuously as attackers adapt to static rule-based defenses.
Sensitive Data Leakage
Enterprise LLMs connected to internal knowledge bases, proprietary documents, or regulated datasets can surface sensitive information unintentionally. OWASP identifies the risk categories:
- PII and customer records
- Financial data and security credentials
- Health records and legal documents
- Proprietary source code
In financial services and healthcare, weak output validation doesn't just create a security incident — it creates a compliance one.
Data and Model Poisoning
The same data infrastructure that makes LLMs useful — retrieval pipelines, vector indexes, fine-tuned weights — is also an attack surface.
Retrieval poisoning targets the RAG layer. Attackers manipulate vector indexes or inject malicious content into retrieval sources, causing the model to treat adversarial instructions as trusted internal knowledge. Research on PoisonedRAG demonstrated that injecting just five malicious texts per target query into a large knowledge base can produce high attack success rates — a viable technique, not a theoretical one.
Training and fine-tuning poisoning operates earlier in the lifecycle. Tampered training data can implant backdoors or bias model behavior in ways that are difficult to detect after deployment. Even small amounts of poisoned data can introduce harmful behavior that persists invisibly through production.

Excessive Agency and Unsafe Tool Use
OWASP LLM06:2025 (Excessive Agency) defines this risk: over-privileged agents or plugins executing unnecessary or unsafe actions across connected systems — file systems, CRM tools, email accounts, databases — particularly when least-privilege access is not enforced and tool calls are not audited.
When an agent can do more than it should, an attacker who influences its behavior inherits those permissions.
Inference Endpoint Abuse
Infrastructure-level threats include attacks targeting computationally expensive inference endpoints:
- Credential abuse and unauthorized access
- Token exhaustion and flooding attacks
- Cost amplification through repeated expensive queries
For organizations running inference at scale, availability and financial exposure are as significant as data protection.
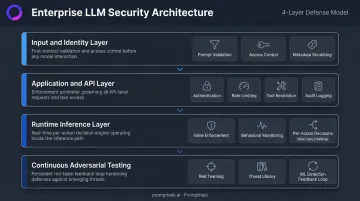
How to Build Enterprise LLM Security Architecture
Securing an LLM application requires managing trust across a dynamic system — inputs, outputs, retrieval sources, connected tools, and agent permissions — all of which shift with each interaction. No single control is sufficient.
Input and Identity Layer
Before requests reach the model:
- Enforce prompt validation and input scoping
- Apply identity-aware access controls
- Filter for injection patterns in user inputs
- Scrub metadata from embedded content (HTML, documents, calendar fields)
- Allowlist retrieval sources and plugin inputs
Application and API Layer
Between the user and connected services:
- Enforce authentication, authorization, and rate limiting
- Restrict tool capabilities to only what each agent actually needs
- Require user confirmation for sensitive or irreversible actions
- Log every tool invocation with full identity attribution
Runtime Inference Layer
Traditional tools stop at the API boundary. An LLM-aware enforcement mechanism must evaluate prompts before execution, detect injection attempts, enforce policy boundaries, and inspect outputs before they reach users or downstream systems.
Behavioral monitoring at this layer detects anomalous interaction patterns that static controls cannot catch. PromptHalo's runtime security solution operates here, sitting inline on every inference, tool call, and agent-to-agent handoff. It makes per-action decisions — allow, restrict, challenge, deny, or monitor — in under 100ms, without touching the underlying model.
Continuous Adversarial Testing
Red teaming is an operational discipline, not a one-time event. Regular adversarial simulation identifies exploitable attack paths before attackers do. The most defensible programs close the loop: discovered vulnerabilities feed directly into runtime enforcement so protection compounds over time.
PromptHalo's red teaming solution covers:
- Continuous attacks against agents, RAG layers, and tool chains
- Findings encoded into a shared threat library
- Automatic training of the ML detection engine from each discovered vulnerability
That same threat intelligence feeds directly into the audit trail — giving security teams evidence-grade documentation of what was found, what was blocked, and what changed.
Compliance and Audit Layer
LLM interactions require tamper-evident, decision-level audit trails mapped to recognized frameworks:
- OWASP LLM Top 10 — covers prompt injection, sensitive data disclosure, excessive agency, supply chain risks, and more
- NIST AI RMF — voluntary framework organized around Govern, Map, Measure, and Manage functions
- EU AI Act (Regulation 2024/1689) — high-risk AI systems require activity logging, human oversight, and serious-incident reporting
In financial services, audit-grade logs aren't optional — they're what regulators ask for.
How to Evaluate LLM Security Solutions
What Disqualifies Legacy Tools
WAFs, DLP tools, and API gateways remain useful perimeter controls, but they weren't built for this threat surface. They inspect structured inputs for known signatures — a method that breaks down entirely when the attack vector is natural language intent, RAG retrieval chain manipulation, or autonomous agent behavior. They have no visibility into the interpretive layer where LLM attacks actually occur.
Evaluation Criteria for Purpose-Built Platforms
Ask these questions when assessing any LLM security solution:
| Criteria | What to Verify |
|---|---|
| Prompt and output inspection | Does it evaluate both, in real time, before execution? |
| Agentic coverage | Does it inspect tool calls, RAG retrieval, and multi-agent handoffs? |
| Granular policy enforcement | Per-action decisions, not binary allow/block? |
| Model agnosticism | Works across any vendor or AI application? |
| Deployment friction | No model retraining or code rewrite required? |
| Detection accuracy | ML-based with documented catch rate and false positive data? |

PromptHalo's platform meets each of these criteria — deployable in under a day across any AI application from any vendor, with ML-based detection running above a 95% catch rate at under 5% false positives.
Compliance and Audit Requirements
Detection performance is only part of the picture. For regulated industries, auditability is equally non-negotiable.
The solution must generate replayable, evidence-grade audit logs mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act. Those logs need to be:
- Append-only and tamper-evident
- Tied to specific agent identity and session context
- Timestamped at the decision level, with the reason recorded
- Capturing individual decisions, not just aggregate event summaries
Frequently Asked Questions
What is the difference between LLM security and traditional application security?
Traditional security protects deterministic code paths using structured input inspection and known exploit signatures. LLM security must address probabilistic interpretation engines where attacks exploit natural language context rather than software vulnerabilities. Traditional tools have no visibility into this interpretive attack surface — AI-aware enforcement mechanisms are required.
What is prompt injection and why is it considered the top LLM threat?
Prompt injection occurs when attackers embed malicious instructions in user inputs or retrieved content to override system directives, alter model behavior, or trigger unauthorized downstream actions. It requires no software exploit — the attack is valid text — making it uniquely difficult to defend against with legacy security tools.
How do you secure agentic AI systems?
Securing agentic AI requires least-privilege scoping, real-time inspection of every tool call and agent-to-agent handoff, identity attribution for agent actions, and continuous adversarial testing across the full workflow. Authority should decay over time and steps, triggering re-authorization whenever the agent's operational scope is exceeded.
What is the OWASP LLM Top 10 and why does it matter?
The OWASP LLM Top 10 is the primary industry framework mapping critical vulnerabilities in large language model applications — including prompt injection, excessive agency, and supply chain risks. It provides a practical baseline for auditing and governing LLM deployments.
Can existing security tools like WAFs and DLP protect LLM applications?
WAFs, DLP, and API gateways remain useful perimeter controls but were not designed to inspect prompts, evaluate model outputs, or monitor autonomous agent actions. LLM-specific enforcement is required to address the interpretive attack surface these tools cannot see.
How does LLM security address compliance requirements like NIST AI RMF or the EU AI Act?
Purpose-built LLM security platforms generate tamper-evident, decision-level audit logs mapped to these frameworks — enabling regulated organizations to demonstrate control, trace incidents, and meet reporting obligations for AI systems handling sensitive transactions or customer data.


