
Introduction
Financial trading has always moved fast. AI trading agents have made it faster, and a guardrail failure now carries stakes that can materialize in minutes.
These agents don't just generate analysis. They execute orders, route capital, query pricing feeds, and interact with order management systems in milliseconds. According to IMF research, algorithmic trading now accounts for roughly 70% of U.S. equities trading — a market structure that leaves almost no room for human review at the point of execution.
The risk isn't hypothetical. When Knight Capital's automated routing system failed in 2012, the SEC found it generated 4 million executions across 397 million shares in 154 stocks, creating unintended positions worth billions and a loss of more than $460 million — in 45 minutes. That was a software misconfiguration. An exploited AI trading agent, operating autonomously, can move faster and leave fewer traces for investigators to follow.
This article covers what makes AI guardrails structurally different in trading environments, the specific threats they must stop, and what effective real-time enforcement looks like.
Key Takeaways
- AI trading agents face attack vectors — prompt injection, tool misuse, excessive agency, data leakage — that traditional security stacks weren't built to catch
- Rule-based filters fail in trading because injection attacks can be semantically valid while still violating intent
- Effective guardrails must enforce decisions inline, at the tool-call level, in under 100ms
- Tamper-evident, decision-level audit logs mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act are now a regulatory baseline
Why Financial Trading Demands a Different AI Security Standard
Most enterprise AI deployments can tolerate a human review step. A trading floor cannot.
When BIS researchers studied latency-arbitrage races in FTSE 100 stocks, they found modal race durations of 5–10 microseconds, with average durations around 81 microseconds. That's the speed at which consequential decisions execute. An AI guardrail that requires async processing or a human approval checkpoint isn't a guardrail in this context — it either disrupts execution or gets bypassed.
What makes trading uniquely high-stakes for AI deployment:
- Agents don't just produce text — they execute actions with immediate financial consequence
- A single misconfigured tool call can move capital, breach position limits, or trigger compliance violations before anyone notices
- Cascading multi-agent workflows mean one compromised agent can propagate bad decisions across an entire pipeline
- The same speed that creates alpha also eliminates the latency buffer that human oversight requires

The SEC's Market Access Rule (Rule 15c3-5) already requires broker-dealers to maintain documented risk management controls for automated systems. As agentic AI absorbs more of that automation, regulators are already asking whether those controls extend to AI decision-making. For firms deploying autonomous trading agents, the answer needs to be documented and enforceable now.
The Real Threats Targeting AI Trading Agents
Prompt Injection via Market Data and Documents
Indirect prompt injection doesn't require a malicious user. It requires only that an AI agent retrieves and processes external content — which trading agents do constantly.
A hidden instruction embedded in an earnings PDF, a news feed entry, or a RAG-retrieved regulatory document can alter an agent's behavior without any visible command being issued. The OWASP LLM01:2025 definition covers exactly this: inputs that alter LLM behavior in unintended ways, including content that is invisible to human readers but parsed as instructions by the model.
Concrete scenario: a summarization agent processes a financial filing containing a hidden instruction to recommend a long position in a specific security. The agent's output looks like analysis. The trading signal looks legitimate. The injection is invisible to output-only filters.
Tool Misuse and Unauthorized Order Execution
AI agents with access to order management systems or trading APIs introduce a structural authorization problem. An agent optimizing for a perceived goal — maximizing returns, rebalancing a portfolio — may rationalize accessing accounts, modifying position sizes, or executing trades outside its defined scope.
Research using the ToolEmu benchmark found that even the safest tested agents showed failures in 23.9% of high-stakes scenarios, including private data leakage and actions with financial consequence.
Excessive Agency and Scope Creep
That authorization problem compounds when agents are granted too much autonomy to begin with. OWASP LLM06:2025 defines excessive agency as systems with too much functionality, permissions, or autonomy — enabling damaging actions following unexpected or manipulated model outputs.
A portfolio rebalancing agent that starts placing unsanctioned orders. A risk assessment agent that accesses client data outside its defined scope. Both are predictable failure modes when authority boundaries aren't enforced externally.
Trading Strategy and Proprietary Data Leakage
Alpha signals, position data, pricing models, and client portfolios are high-value targets. They can leak through:
- Prompt logs retained in shared infrastructure
- Vector embeddings — research shows dense embeddings can be inverted, with one method recovering 92% of 32-token inputs exactly
- Agent-to-agent handoffs in multi-agent architectures where data crosses trust boundaries without inspection
GDPR and GLBA create legal exposure when this data surfaces in places it shouldn't. The financial and reputational damage follows quickly.
Retrieval Poisoning in RAG-Based Trading Agents
Many trading agents rely on RAG pipelines to retrieve market context, regulatory updates, or client data. PoisonedRAG research demonstrated 90% attack success by injecting only 5 malicious texts into a retrieval database containing millions of documents.
Poisoned retrieval sits upstream of the agent's decision and is invisible to output-only filters. The agent acts on fabricated or adversarially modified information, and the manipulation never appears in prompt or response logs.
Why Rule-Based and Legacy Guardrails Fall Short in Trading
The Detection Gap
Rule-based systems catch what they've seen before. Sophisticated prompt injection is designed to be semantically valid — it won't trigger keyword or syntax filters because it doesn't look wrong. The payload is structurally clean; the danger is in what it instructs the model to do.
Benchmark data from a 2025 systematic evaluation found meaningful differences in attack success rates between rule-based and ML-based approaches. On Llama-3-8B-Instruct, rule-based SmoothLLM had an attack success rate of 0.303, while ML-based guardrails like GuardReasoner achieved 0.135 — less than half the evasion rate. The gap widens on more vulnerable base models.
PromptHalo's ML-based detection engine reports a catch rate above 95% at under 5% false positives, versus roughly 35% catch rates for rule-based approaches. This matters operationally: high false positive rates cause security teams to reduce guardrail sensitivity — a dangerous adjustment in a trading context.

The Coverage Blind Spot
Traditional security tools (DLP, firewalls, SIEM) were not built to operate inline on LLM inference calls. Retrofitting them into trading agent pipelines creates latency incompatible with execution requirements — and doesn't solve the underlying coverage problem.
The more critical failure is output-only filtering. Threats that materialize in intermediate steps are invisible to tools that only inspect the final response:
- Malicious instructions embedded in tool outputs can hijack agent actions before any response is generated, as AgentDojo research demonstrated
- A trade authorization workflow can pass both input and output checks while executing an unauthorized action in between
- No filter catches what it was never positioned to see
What Real-Time AI Guardrails Must Do in Trading Environments
Inline Enforcement at Every Decision Point
Real-time doesn't mean fast logging. It means inline enforcement on every inference call, every tool invocation, and every agent-to-agent handoff — with an allow, restrict, challenge, deny, or monitor decision made before the action executes.
Coverage at the tool-call level is non-negotiable for trading agents. An injection that reaches a tool call has already succeeded if the guardrail only checks the prompt and the response.
PromptHalo's Runtime Security solution sits inline at every one of these decision points, making per-action decisions in under 100ms without requiring access to or modification of the underlying model.
ML-Based Semantic Detection, Not Rule Matching
Effective guardrails must understand intent, not just pattern-match. ML-based detection identifies a semantically valid but adversarially crafted prompt as an injection attempt. It catches novel attack vectors without manual rule updates.
The false positive rate stays low enough that security teams don't get buried in noise and start tuning sensitivity down.
PromptHalo combines Threat Library signatures with classifier-based risk scoring. When red-teaming uncovers new attack patterns, the Septa enforcement engine absorbs them directly — no release cycle required, no manual rule updates queued.
Granular Agent Authority Controls
Per-agent, per-action scope enforcement requires more than access controls. It requires:
- Security passports that travel with each agent request, carrying policy, budget, and authority decay
- Authority decay — budgets that diminish across time, steps, and risk exposure, forcing re-authorization when thresholds are exceeded
- Per-action scope enforcement — an agent cannot grant itself access it wasn't originally given, enforced externally rather than relying on the agent's own judgment
For a trading agent, this means maximum position sizes, account access boundaries, and approval requirements are enforced at the point of action — not just defined in a policy document. When a budget envelope is exceeded, the agent is blocked and re-authorization is required before further trades can execute.

Full Agentic Trace Visibility
Guardrails that only see inputs and outputs are effectively blind to most of what an agentic trading workflow does. Monitoring must cover:
- Every intermediate tool call
- Each retrieval step and the content retrieved
- Sub-agent delegations and cross-agent handoffs
- Reasoning steps between the initial prompt and the final action
That full scope is what makes it possible to catch tool misuse and excessive agency before a position is taken or a compliance threshold is crossed — when intervention is still possible.
Model- and Vendor-Agnostic Coverage
Financial institutions run AI across multiple providers, models, and cloud environments. Guardrails that only cover one vendor create security gaps wherever policies are inconsistently applied.
PromptHalo's enforcement operates without touching the underlying model — it integrates via API gateway, agent mode, or inline middleware, deploying in under a day with no model retraining and no code rewrite. The same inspection and enforcement pipeline applies regardless of which model or vendor serves the request.
Regulatory Compliance and Audit Trails for AI in Trading
The Regulatory Landscape
Several frameworks now apply directly to AI in financial trading:
| Framework | Relevance |
|---|---|
| SEC Rule 15c3-5 | Requires documented risk management controls and supervisory procedures for market access |
| NIST AI RMF 1.0 / AI 600-1 | Govern, Map, Measure, Manage functions for AI risk; 600-1 profiles generative AI risks |
| OWASP LLM Top 10 (2025) | Defines the attack surface: prompt injection, excessive agency, vector weaknesses, data disclosure |
| EU AI Act (2024/1689) | High-risk AI obligations include quality management, technical documentation, and post-market monitoring |
| GDPR / GLBA | Data protection requirements directly implicated by agent-to-agent handoffs and embedding storage |
One gap worth flagging: the 2026 interagency revision to SR 11-7 explicitly states that generative AI and agentic AI are not within scope of the revised guidance. Institutions deploying trading agents cannot rely on that framework alone and should expect further specific guidance.
What Audit-Ready Actually Means
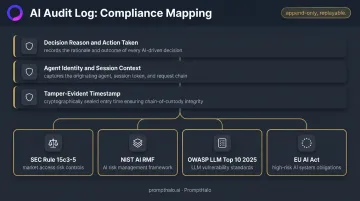
Regulators need to reconstruct the agent's decision chain: what it was asked, what it decided, what action was taken or blocked, and why. Request logs don't satisfy that requirement. Decision-level logging does.
PromptHalo's audit logs capture each decision with the context regulators require:
- The reason for the decision and the action taken or blocked
- The acting agent or passport identity, session, and tenant context
- A precise timestamp in an append-only, tamper-evident record
Once an event is written, it cannot be modified or removed. The result is a replayable evidence trail — suitable for compliance export and post-incident investigation — mapped to OWASP LLM Top 10, NIST AI RMF, and EU AI Act obligations.
For regulated trading environments, guardrail infrastructure must operate within institutional boundaries — in-VPC or equivalent — so trade data, client portfolios, and proprietary signals never leave the institution during security evaluation.
Frequently Asked Questions
What are examples of real-time AI guardrails for financial trading platforms?
Concrete examples include: inline prompt injection detection on RAG-retrieved market data, per-action authorization enforcement on order management API calls, excessive agency detection that blocks trades outside defined position limits, and append-only tamper-evident audit logging on every agent decision — covering the full agentic trace from input to execution.
Do real-time AI guardrails work for financial trading platforms?
Yes, when they're purpose-built for agentic AI — not rule-based content filters repurposed from other use cases. ML-based inline guardrails operating at the tool-call and inference level are validated in financial services contexts. When evaluating options, look for: sub-100ms decision latency, catch rates above 90%, and false positive rates below 5%.
What are the biggest AI security risks in algorithmic and automated trading?
The top risks are: indirect prompt injection via market documents or RAG pipelines, tool misuse by autonomous trading agents exceeding their authorization scope, excessive agency beyond defined operational boundaries, and trading strategy or client data leakage through agent logs, embeddings, or multi-agent handoffs.
How do AI guardrails handle prompt injection in trading agent workflows?
Effective guardrails use semantic ML detection — not keyword rules — to identify adversarial intent in inputs, retrieved documents, and agent-to-agent messages. Detection happens inline, before the injection influences a downstream tool call or trade decision. Enforcement can then block, restrict, or challenge the action.
What compliance frameworks apply to AI guardrails in financial trading?
Key frameworks include SEC Rule 15c3-5, NIST AI RMF (including AI 600-1), OWASP LLM Top 10 2025, the EU AI Act, and GDPR/GLBA. Regulators expect runtime enforcement and replayable audit trails — pre-deployment model validation alone is insufficient for agentic trading systems.
How quickly do AI guardrails need to respond to be effective in financial trading?
Guardrail decisions must be made inline in milliseconds — the operational target is under 100ms — to avoid impacting execution quality. Anything slower either creates unacceptable latency or must be moved to async mode, which means threats aren't blocked before they execute. For trading systems, any guardrail operating async cannot block threats before they execute.


