
Introduction
Security teams are caught in a familiar bind: AI products are moving to production fast, and every request for a security review feels like pulling the emergency brake. The pressure is real—but the framing is wrong.
That bind rests on a flawed assumption. It breaks down once you look at where the actual friction lives. Post-incident remediation, failed compliance reviews, and shadow AI incidents don't just delay launches—they cancel them. Gartner predicts over 40% of agentic AI projects will be canceled by end-2027 due to escalating costs and inadequate risk controls. Risk controls aren't an obstacle to shipping—they're increasingly the reason AI programs survive long enough to scale.
The deeper problem is that traditional security tools weren't designed for agentic AI. Firewalls inspect packets, not semantic intent. DLP tools match known data patterns, not emergent model behavior. Neither can see the attack surface that matters now: autonomous tool calls, RAG retrieval chains, and agent-to-agent handoffs.
That gap is why enforcement needs a different approach. This article breaks down what effective AI guardrails actually look like, why they reduce rather than add friction, and how to implement them without sacrificing velocity.
Key Takeaways
- AI guardrails are runtime enforcement controls that evaluate inputs, model behavior, and outputs in real time—not static filters
- The agentic attack surface (tool calls, RAG retrieval, multi-agent handoffs) is invisible to conventional security stacks
- ML-based guardrails catch significantly more semantically varied attacks than rule-based approaches, at comparable latency
- Pre-approved guardrail frameworks eliminate per-project security reviews, compressing AI shipping cycles without added compliance friction
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act all require the same thing: documented, auditable controls at the point of AI decision-making
What AI Guardrails Are and Why Traditional Controls Fall Short
AI guardrails are enforcement controls embedded directly in the inference lifecycle—inspecting inputs, reasoning chains, tool calls, and outputs at the moment model behavior actually happens. Unlike perimeter controls, they don't sit at the network edge waiting for known threat signatures. They operate inside the interaction flow, where the actual risk lives.
Traditional security tools operate on fundamentally different assumptions:
- Firewalls inspect network packets for known threat signatures—they have no concept of whether a natural-language instruction embedded in a retrieved document is directing an agent to exfiltrate data
- DLP tools scan for recognized data patterns like credit card numbers or SSNs—they can't detect when a model is being manipulated into surfacing protected information it wasn't supposed to retrieve
- Code scanners assess static code—they don't evaluate runtime decisions made by autonomous agents acting on retrieved context
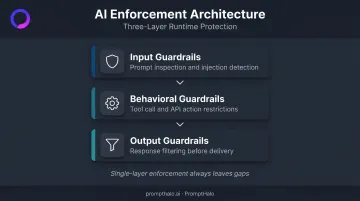
The Three Layers That Matter
Effective enterprise guardrail deployments require coverage across all three enforcement layers:
- Input guardrails — prompt inspection and injection detection before the model processes the request
- Behavioral guardrails — restricting what actions an agent can take, including tool calls and API interactions
- Output guardrails — filtering responses before they reach users or downstream systems
Most point solutions cover one layer. Attacks move between all three—and purpose-built guardrail frameworks are designed with that reality in mind.
NVIDIA NeMo's guardrails architecture, for example, describes programmable controls for input, output, retrieval, and execution rails around tool calls. The design treats guardrails as runtime controls woven through the full LLM interaction flow, not content filters bolted onto the output after the fact. That multi-layer framing matters because single-layer enforcement always leaves gaps an attacker can route around.
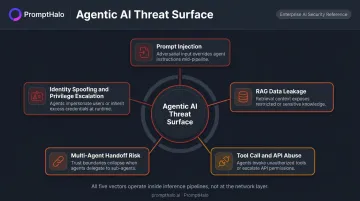
The Agentic AI Threat Surface
The threats that matter in agentic AI don't look like traditional cyberattacks. They occur inside inference pipelines, not at the network layer, which is why conventional security stacks miss them entirely.
Prompt Injection and Jailbreaks
Attackers embed adversarial instructions in user inputs or in retrieved documents. The model reads these as legitimate instructions and acts accordingly, bypassing safety filters, exfiltrating data, or steering workflows in unintended directions. OWASP's 2025 LLM Top 10 lists prompt injection as its number-one risk, covering both direct prompts and indirect instructions hidden in external content like files or web pages.
Data Leakage Through RAG Retrieval
Retrieval-augmented generation pipelines are a primary source of enterprise data exposure. Improperly scoped retrieval surfaces confidential documents, PII, or proprietary data in model responses.
PoisonedRAG research describes attacks where malicious text is injected directly into the knowledge base, turning the enterprise's own document store into the attack vector. The ConfusedPilot vulnerability shows that even internal tickets and presentations can carry hidden instructions that manipulate generated answers.
Tool Call and API Abuse
Agentic models don't just generate text: they execute actions. The AgentDojo NeurIPS 2024 benchmark demonstrates that agents are particularly vulnerable when tool-returned data contains prompt injection instructions. An unguarded agent can be manipulated into performing out-of-scope actions:
- Writing or modifying database records
- Sending messages through connected communication tools
- Calling external APIs outside sanctioned scope
- Moving laterally across integrated systems
Multi-Agent Handoff Risk
When one agent delegates to another, trust assumptions propagate without verification. A compromised upstream agent passes malicious instructions downstream, and no single control point catches the full chain. The Cloud Security Alliance describes session smuggling and privilege escalation as specific risks in agent delegation, requiring cryptographic lineage and scoped permissions at every handoff.
Identity Spoofing and Privilege Escalation
Agentic systems frequently operate with elevated API credentials and broad data access. Token compromise or spoofed agent identities create pathways to sensitive transactions and compliance workflows, without triggering any conventional security alert.
Each of these vectors requires controls that operate at the inference layer — not at the perimeter. That's where AI guardrails come in.
How Effective AI Guardrails Work
Inline vs. Out-of-Band Enforcement
The architecture decision matters more than any specific detection method. Out-of-band monitoring (observing and logging without blocking) is useful for analytics and tuning. It's insufficient when agent actions are irreversible.
Sending a message, writing a database record, calling an external payment API: none of these can be undone after the fact. Inline enforcement intercepts every inference, tool call, and agent-to-agent handoff before execution. That's the design requirement for agentic systems.
PromptHalo's Runtime Security sits inline on this basis, making a per-action decision (allow, restrict, challenge, deny, or monitor) in under 100ms.
ML-Based Detection vs. Rule-Based Approaches
Static rules fail against semantically varied attacks. A 2026 prompt injection benchmark found that a 26-detector regex baseline caught just 1 of 60 attacks on a real-world dataset (F1: 0.033), while a semantic detector caught 14 of 60 (F1: 0.378).
A separate benchmark of 480 queries showed regex-only filtering had a 69.65% bypass rate — roughly 7 in 10 attacks got through. An ML-based guardrail (Prompt Guard) cut that to 38.48% bypass at 74.41ms latency, both at sub-100ms performance.
PromptHalo's ML detection engine, trained continuously through its red-team discovery process, targets a catch rate above 95% at under 5% false positives. Rule-based approaches typically land around 35% catch rates with 15–20% false positives. The detection combines Threat Library signatures with classifier-based risk scoring rather than brittle keyword matching.

Granular Agent-Level Controls
Standard guardrail platforms enforce at the model level. Agentic systems require enforcement at the agent level. PromptHalo's approach includes:
- Security passports — signed credentials issued per agent that carry policy, budget, and authority constraints through every downstream handoff
- Risk profiling — per-agent risk scoring that adjusts enforcement thresholds based on the agent's behavior history and action context
- Authority decay — agent permissions that diminish over time or after a defined number of actions, requiring re-authorization rather than preserving elevated access indefinitely
- Per-action budget enforcement — scope limits applied individually to each tool call or API interaction, preventing any single action from exceeding its authorized envelope
Authority decay and per-action budget enforcement are absent from most competing platforms. They matter because agentic systems typically launch with broad access and tighten permissions slowly — that gap is where attackers operate.
Decision-Level Audit Trails
Compliance teams and regulators need more than request logs. Effective guardrails log every allow, restrict, challenge, deny, or monitor decision with the reason, acting agent identity, session and tenant context, and timestamp, stored append-only and tamper-evident.
The distinction matters in practice:
| Log Type | What It Captures |
|---|---|
| Request log | What was sent and received |
| Decision log | What the system decided, why, and which agent was responsible |
Decision logs make forensic replay and regulatory reporting tractable rather than theoretical.
Model- and Vendor-Agnostic Deployment
Guardrails should enforce trust across any AI application without requiring model retraining or code rewrites. PromptHalo deploys via API gateway, agent mode, or inline middleware, all feeding the same inspection and enforcement pipeline. Switching AI providers or adopting new models doesn't require rebuilding the security posture.
Guardrails as Innovation Enablers
Ungoverned AI doesn't stay safe — it stays hidden. IBM's 2025 Cost of a Data Breach Report found that 63% of organizations lacked AI governance policies, and that those without governance face higher breach rates and steeper remediation costs. Microsoft's 2024 Work Trend Index reinforces why: 78% of AI users bring their own tools to work. Banning AI doesn't reduce AI use — it drives it underground where enforcement is impossible.
Pre-Approved Frameworks Replace Per-Project Reviews
When guardrail policies are defined upfront and continuously enforced, AI teams don't need individual security reviews before each deployment. The guardrail layer that security already signed off on functions as a continuous deployment gate. New features ship through the same enforcement pipeline—no ad-hoc review required.
The bottleneck was never the guardrail — it was the per-project security review, the post-incident remediation cycle, and the compliance failure that grounded a production launch. Pre-approved frameworks eliminate the review overhead upfront, and well-designed guardrails cut the remediation and compliance failures that follow.

Latency Isn't the Trade-Off It Appears
The most common objection to inline enforcement is latency — that adding a security layer between the model and the user degrades the experience. The data doesn't support it. Nielsen Norman Group defines 100ms as the threshold for users to feel a system responds instantaneously. Guardrails operating under that threshold add no perceptible delay.
The benchmark data supports this. ML-based guardrails have demonstrated sub-100ms performance in published evaluations. PromptHalo's per-action enforcement targets this threshold by design—inline enforcement that doesn't require changes to model architecture or inference pipelines.
Aligning AI Guardrails to Compliance Frameworks
The major frameworks are converging on the same requirement: documented, auditable controls at the point of AI decision-making.
Framework Mapping
| Framework | Core Requirement | Guardrail Relevance |
|---|---|---|
| OWASP LLM Top 10 (2025) | Prompt injection, improper output handling, data/model poisoning, excessive agency | Maps directly to input, behavioral, and output guardrail layers |
| NIST AI RMF | Govern, Map, Measure, Manage | Requires real-time monitoring, input/output filtering, and red-teaming for prompt injection |
| EU AI Act | Risk classification, conformity assessments, automatic event logging, technical documentation | High-risk systems need tamper-evident logs and audit trails tied to specific decisions |
NIST's AI 600-1 GenAI Profile is particularly specific: it explicitly recommends real-time monitoring, real-time auditing for data lineage, input/output filtering, guardrail review, and AI red-teaming for prompt injection. Regulated deployments are measured against this profile, not general best-practice checklists.
What Regulators Actually Expect
Compliance documentation for AI systems needs to demonstrate:
- Decision-level logs, not just access logs—capturing what was decided, why, and by which agent
- Tamper-evident storage—append-only records that cannot be modified or removed after the fact
- Replayable audit trails—structured enough for forensic investigation and compliance export
Three regulatory regimes set the floor for what that looks like in practice:
- HIPAA: Audit controls required for any system containing electronic PHI, with documentation retained for six years
- FINRA: Existing securities rules — supervision and books and records — apply when AI is involved, regardless of technology used
- GDPR: Records of processing activities required, with storage limitation principles enforced throughout
None prescribe a specific guardrail log retention period. All point to the same underlying requirement: auditable, traceable controls at the point of decision.
Financial Services Considerations
For fintech and payments organizations, guardrails aren't just a security control—they're a compliance artifact. AI decision-making in customer transactions touches supervision obligations, model risk management under Federal Reserve SR 11-7, and records requirements under SEC Rule 17a-4. Evaluating guardrail solutions purely on detection capability misses the question regulators will ask: is your audit output regulator-ready, or just internally useful?
PromptHalo's audit logging is built for this gap: decision-level, tamper-evident records covering every agent action across transactions, compliance workflows, and customer interactions — structured for regulatory export, not just internal review.
Frequently Asked Questions
How do you secure AI in the enterprise?
Securing enterprise AI requires layered controls across the full agentic attack surface: input validation, behavioral enforcement, output filtering, and decision-level audit trails. Traditional perimeter security never reaches inside inference pipelines, tool calls, or agent-to-agent handoffs — the places where attacks actually occur.
What are AI guardrails and how do they differ from traditional security controls?
AI guardrails are real-time, context-aware enforcement controls designed for non-deterministic AI systems. Unlike firewalls or DLP tools that inspect static network traffic or match known data patterns, guardrails evaluate intent, behavior, and output semantics across the full inference lifecycle—at runtime, not at the perimeter.
Do AI guardrails slow down AI deployment cycles?
Well-designed guardrails operating under 100ms add no meaningful latency. The real delays come from post-incident remediation, compliance failures, and ad-hoc security reviews. Pre-approved guardrail frameworks eliminate those delays by embedding trust enforcement from the start.
What threats are unique to agentic AI systems?
The agentic-specific threat surface includes prompt injection via retrieved documents, tool call and API abuse, multi-agent handoff manipulation, RAG retrieval poisoning, and identity spoofing. These threats occur inside inference pipelines, not at the network layer, which is why conventional security stacks were never designed to catch them.
How do ML-based guardrails compare to rule-based approaches?
Rule-based guardrails match known patterns and are easily bypassed by semantically varied attacks. ML-based guardrails evaluate context and intent instead, achieving catch rates above 95% with false positives below 5%, compared to roughly 35% catch rates and 15-20% false positives for rule-based approaches. For enterprises, that gap matters: missed attacks and alert fatigue carry real cost.


