
Introduction
AI agents have moved well past generating text. Today they book appointments, write to databases, call external APIs, and trigger financial transactions — autonomously, at scale, across interconnected systems. That autonomy is also what makes them dangerous when something goes wrong.
A misconfigured chatbot gives a bad answer. A misconfigured agent executes a bad action — and may do so across a dozen downstream systems before anyone notices. The two failure modes are not comparable in scale or speed.
Traditional controls like firewalls, DLP tools, and code scanners were built for deterministic, human-authored traffic. They were never designed to evaluate natural language reasoning, validate tool-call scope, or detect when an agent's behavior has been hijacked mid-task.
Gartner projects that up to 40% of enterprise applications will include task-specific AI agents by 2026, up from less than 5% in 2025. The governance infrastructure hasn't kept pace.
This guide covers what AI agent guardrails are, why they differ from conventional security controls, the types that matter most, how to implement them in layers, and how to measure whether they actually work.
Key Takeaways
- Guardrails are external, operational controls — not model fine-tuning — that govern what an agent can perceive, reason about, and act on
- The four critical guardrail layers are: input, reasoning/behavioral, output, and action/tool-call
- ML-based detection achieves 95%+ catch rates and under 5% false positives — compared to roughly 35% catch rates and 15–20% false positives for rule-based approaches
- No single guardrail layer is sufficient — defense-in-depth across all four layers is required
- Continuous red-teaming is what keeps guardrails grounded in real threat intelligence, not theoretical policies
What Are AI Agent Guardrails?
AI agent guardrails are the policies, technical controls, and runtime enforcement mechanisms that govern what an AI agent can perceive, reason about, decide, and act on. They are external and operational — not baked into model weights through fine-tuning or training-time alignment.
The analogy to network infrastructure holds — up to a point. A firewall governs which traffic crosses your network boundary; guardrails govern which actions an agent is permitted to take.
The difference is that static firewalls evaluate structured packets against fixed rules. Effective agent guardrails must evaluate context, intent, and action scope in real time against a threat surface that shifts with every model update, new tool integration, or agent workflow change.
Where Guardrails Apply
Guardrails operate across the full agent lifecycle — not just at one checkpoint:
- Inputs: User messages, retrieved documents, tool responses coming into the agent
- Reasoning: The internal planning and decision-making process before action
- Outputs: Responses delivered to users or downstream systems
- Actions: Tool calls, API requests, database writes, and external communications
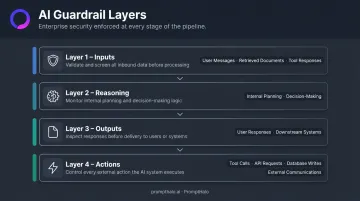
This scope applies equally across autonomous agents, semi-autonomous agents requiring periodic human confirmation, and multi-agent pipelines — where one agent's output feeds directly into another's input.
Why Traditional Security Controls Fall Short for AI Agents
Firewalls inspect packet headers. DLP tools pattern-match against known data formats. Code scanners analyze static syntax. None of these were designed to answer the question an agent guardrail must answer: Is this agent doing what it's supposed to be doing, given what it knows, and is the action it's about to take within its authorized scope?
The gap is structural. Traditional controls cannot:
- Parse natural language instructions to determine intent
- Evaluate whether a proposed tool call falls within the current task's scope
- Detect when an agent's reasoning has been redirected by a malicious instruction buried in a retrieved document
The Agentic Attack Surface Is Different
Agentic systems create risk vectors with no equivalent in traditional application security:
- Autonomous tool calls execute against external APIs without human review
- RAG retrieval poisoning corrupts the agent's context at the knowledge base level
- Multi-agent handoffs create chained pipelines where one compromised step propagates errors across the entire workflow
OWASP's LLM06 identifies excessive agency as a top risk category — specifically calling out scenarios where LLM-based systems invoke functions, tools, or plugins and where the invocation decision itself is delegated to the agent. A single manipulated output can cascade into unauthorized API calls, data writes, or privilege escalation before any human-facing alert fires.
IBM's 2025 research found that **97% of organizations with AI-related security incidents lacked proper AI access controls** and 63% had no governance policies to prevent shadow AI. That isn't a configuration problem. It reflects a category mismatch: the tools enterprises rely on were designed for a fundamentally different threat model.

Types of AI Agent Guardrails
Effective guardrail architecture operates across four distinct layers. Each catches what the others miss.
Input Guardrails
Input guardrails intercept and evaluate all content before it reaches the agent's reasoning engine: user messages, retrieved documents, and external tool responses. They screen for prompt injection attempts, jailbreak patterns, malicious instructions, and retrieval-poisoned context.
Blocking at input is the cheapest and fastest defense — it avoids all downstream processing cost. PromptHalo's input detection runs inline in milliseconds, using embedding-based scoring against a shared Threat Library rather than brittle static rules, catching threats before the reasoning engine ever sees them.
Reasoning and Behavioral Guardrails
These controls validate what the agent plans to do before it acts. Key enforcement mechanisms include:
- Scope validation: Checking whether a proposed tool sequence falls within the agent's authorized task
- Privilege escalation detection: Flagging attempts to claim permissions beyond the agent's defined role
- Authority decay: Progressively restricting agent permissions as task complexity or operational risk increases
PromptHalo implements authority decay through agent security passports: identity credentials that travel with each request, carrying budgets across time, steps, and risk level. When those budgets are exceeded, the system forces re-authorization rather than letting the agent continue with privileges it was never meant to hold.
Output Guardrails
Output guardrails scan agent responses before they reach the user or any downstream system. This is the last internal line of defense. Controls at this layer include:
- Real-time data leakage detection and blocking
- Content policy enforcement via configurable rule sets
- Behavioral drift detection across sessions (not just single responses)
PromptHalo's Policy Enforcement Engine lets security teams define custom rules — flag, log, transform, or block — applied per action, with every decision recorded in a tamper-evident audit trail.
Action and Tool-Call Guardrails
This layer operates at execution time, governing what the agent can actually do in the world:
- Action allowlists defining approved APIs and endpoints
- Per-action budget enforcement scoped to time, steps, and risk level
- Human-in-the-loop triggers for high-impact operations (financial transactions, database writes, external communications)
- Inline blocking of out-of-scope tool and API calls before they execute
PromptHalo sits inline on every inference, tool call, and agent-to-agent handoff, making per-action decisions in under 100ms: allow, restrict, challenge, deny, or monitor, with full auditability on every outcome.
Rule-Based vs. ML-Based Detection
Where and how detection runs are equally important decisions.
| Approach | Catch Rate | False Positive Rate | Limitation |
|---|---|---|---|
| Rule-based (regex, keyword matching) | ~35% | 15–20% | Misses novel, nuanced, or obfuscated attacks |
| ML-based (semantic classifiers) | >95% | <5% | Higher compute cost |
Anthropic's Constitutional Classifiers research demonstrates what this looks like in practice: baseline jailbreak success against Claude 3.5 Sonnet was 86%, dropping to 4.4% with classifier-based defenses — at a 23.7% increase in compute cost. That tradeoff is worth it for most enterprise deployments.

PromptHalo's ML-based enforcement combines Threat Library signatures with classifier-based risk scoring, achieving over 95% catch rate at under 5% false positives. Patterns discovered through red-teaming are encoded directly into the Threat Library, so detection compounds without manual rule updates.
The Key Threats AI Agent Guardrails Protect Against
Prompt Injection and Jailbreaks
Prompt injection exploits the agent's natural language reasoning. Malicious instructions embedded in user input, retrieved documents, or tool responses can override system instructions and redirect agent behavior. In an agentic context, a successful injection doesn't just produce a bad answer — it can trigger unauthorized API calls, exfiltrate data, or escalate privileges.
OWASP ranks prompt injection as LLM01:2025 — the top risk in its LLM taxonomy. A 2025 academic evaluation of over 1,400 adversarial prompts found attack success rates of 87.2% against GPT-4 and 82.5% against Claude 2 in research settings, with GPT-4-successful prompts transferring to Claude 2 in 64.1% of cases. Unit 42 has also documented real-world indirect prompt injection against a production AI ad review system.
Data Leakage and Retrieval Poisoning
Two distinct but related risks operate here:
- Excessive permissions exposure: Agents with overly broad access can surface PII, credentials, or financial records through outputs or tool calls — often without any network-layer DLP tool detecting it
- RAG retrieval poisoning: Adversarial content injected into a knowledge base corrupts the agent's context, causing it to act on false or malicious information
PoisonedRAG research demonstrated 90% attack success rate when injecting just five malicious texts per target question into a knowledge base containing millions of clean documents. On the NQ benchmark, 97% attack success was achieved with five malicious texts among 2.68 million clean texts. These attacks are invisible to traditional DLP tools operating at the network layer.
Out-of-Scope Tool Calls and Action Cascades
Agentic autonomy creates cascade risk: a small reasoning error or scope ambiguity can trigger a chain of unintended tool calls that compound before any human reviews the outcome. Multi-agent orchestration amplifies this cascade risk — one agent's malformed output becomes another agent's input, and errors propagate across the pipeline before any single point of review can catch them. MITRE ATLAS identifies agent tool poisoning and LLM prompt injection techniques as named attack categories with documented real-world applicability, not edge-case theoretical scenarios.
How to Implement AI Agent Guardrails: A Layered Approach
No single guardrail is sufficient. Effective protection requires coordinated controls at every layer: the same reason you don't protect a bank vault with a single lock.
Policy and Identity Foundation
Start by defining the rules before building the controls:
- Data classification tiers — what the agent can and cannot access
- Decision autonomy thresholds by risk level — low-risk agents operate autonomously; high-risk agents in finance or healthcare require human approval gates
- Agent service identities — treat agents like any other service account in your IAM system, with least-privilege access, credential scoping, and session limits
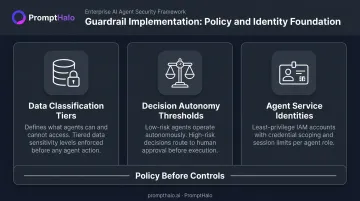
PromptHalo's security passport model formalizes this: each agent receives a credential that carries its policy, budget, and authority decay parameters, scoped per action and enforced externally.
Prompt Filtering and Execution Controls
At the technical layer, implement:
- Input sanitization to neutralize injection patterns before they reach reasoning
- Execution allowlists for permitted APIs and function calls
- Rate limiting to prevent runaway loops and resource exhaustion
- Policy enforcement rules to flag, transform, or block outputs in real time
PromptHalo's Policy Enforcement Engine lets teams define these rules per action across agent workflows, with every decision recorded for audit and review.
Human-in-the-Loop Integration
HITL is deliberate risk calibration, not a concession to automation's limits. Deploy it where the stakes justify it:
- Pre-action approval for financial transactions, database writes, and external communications
- Confidence-threshold pauses when agent certainty falls below a defined level
- Post-action audits for quality assurance and compliance review
Continuous Red-Teaming
Guardrails cannot be configured once and left alone. Threats evolve, agent behavior can vary even with identical inputs, and new attack vectors emerge with every model update or new tool integration.
PromptHalo's red-teaming approach continuously stress-tests an organization's agents, RAG layers, and tool chains across attack types including:
- Prompt injection variants and jailbreak attempts
- Retrieval poisoning against RAG pipelines
- Adversarial task chains across multi-step, multi-agent workflows
Discoveries feed directly into the shared Threat Library, which drives runtime enforcement. A newly discovered attack pattern becomes a production defense without waiting for a new release cycle.
Measuring Guardrail Effectiveness and Staying Compliant
Four Metrics That Matter
Track these across every agent deployment:
- Attack block rate — percentage of prompt injection, jailbreak, and out-of-scope action attempts successfully stopped
- False positive rate — legitimate requests incorrectly blocked; high false positives degrade usability and incentivize workarounds
- Latency impact — inline enforcement should resolve in under 100ms; PromptHalo's runtime enforcement meets this threshold, with commerce-specific trust checks completing in under 50ms
- Audit trail completeness — every agent decision, tool call, and output should be traceable to a specific prompt, agent identity, session context, and timestamp. PromptHalo's append-only, tamper-evident audit logs capture each decision with its reason, the acting agent's passport identity, session and tenant context, and timestamp: a replayable evidence trail for debugging, compliance export, and post-incident investigation.
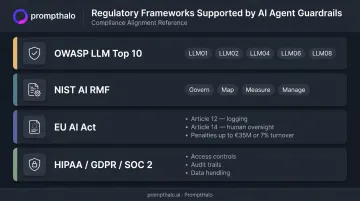
Compliance Framework Alignment
Well-implemented guardrails support compliance with the major AI regulatory frameworks:
- OWASP LLM Top 10 maps directly to guardrail categories: LLM01 (prompt injection), LLM02 (sensitive information disclosure), LLM04 (data and model poisoning), LLM06 (excessive agency), LLM08 (vector and embedding weaknesses)
- NIST AI RMF organizes risk management around Govern, Map, Measure, and Manage — guardrails operationalize all four
- EU AI Act Article 12 requires automatic logging for high-risk AI systems; Article 14 requires effective human oversight; Article 99 penalties reach up to €35M or 7% of worldwide annual turnover for prohibited practices
- HIPAA, GDPR, SOC 2 all require access controls, audit trails, and data handling protections that guardrails directly enforce
Meeting these frameworks isn't a checkbox exercise. Guardrail effectiveness demands periodic independent audits, lessons learned from near-misses and failed attacks, and formal change management before any model update or new agent deployment.
Frequently Asked Questions
What is the difference between AI guardrails and traditional cybersecurity controls?
Traditional controls (firewalls, DLP, SIEM) operate on deterministic, structured traffic and cannot evaluate natural language intent, agent reasoning chains, or the legitimacy of an autonomous tool call. AI guardrails are purpose-built to govern LLM-based agent behavior at the inference and action level — where conventional tools have no visibility.
How do AI agent guardrails protect against prompt injection?
Input-layer guardrails scan all incoming content — user messages, retrieved documents, tool responses — for injection patterns before they reach the agent's reasoning engine. Behavioral guardrails then validate planned actions, catching any injections that slipped through by flagging behavior that deviates from the agent's authorized scope.
Do AI agent guardrails slow down agent performance?
Latency impact depends on implementation. Rule-based filters add minimal overhead; ML-based classifiers require more compute. Well-engineered inline enforcement (such as PromptHalo's sub-100ms decision latency) is achievable without degrading user experience. For most deployments, the security gain far outweighs the latency cost.
What compliance frameworks do AI agent guardrails help satisfy?
The primary frameworks are OWASP LLM Top 10, NIST AI RMF, the EU AI Act, GDPR, HIPAA, and SOC 2. Guardrails support compliance by enforcing access controls, generating audit trails, enabling human oversight workflows, and preventing the data handling violations these regulations prohibit.
How often should AI agent guardrail policies be updated?
Treat guardrails as living infrastructure. Update them continuously through red-teaming feedback loops, review them after every significant model update or agent deployment change, and conduct independent audits at least quarterly to ensure coverage keeps pace with evolving attack tactics.
Can AI agent guardrails work across agents from different AI vendors?
Model- and vendor-agnostic guardrails operate at the API and inference layer rather than inside the model itself. PromptHalo deploys via API gateway, agent mode, or inline middleware, working consistently across agents built on different LLMs and providers without requiring model access or code rewrites — making it practical for enterprises running heterogeneous AI stacks.


