
Introduction
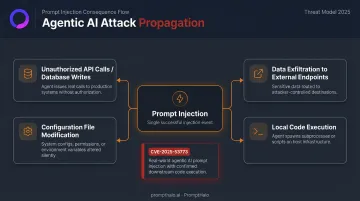
Prompt injection has held the top spot on the OWASP Top 10 for LLM Applications for consecutive years, and the attack surface has expanded well beyond bad chatbot responses. Today's injections target agentic AI systems wired to tools, databases, and retrieval pipelines. A successful attack can trigger unauthorized API calls, exfiltrate data through a poisoned RAG corpus, or execute code on a developer's machine.
The PoisonedRAG research demonstrated that injecting just five malicious texts into a knowledge database achieved a 90% attack success rate — a number that should stop any team running RAG in production. Meanwhile, CVE-2025-53773 showed how a prompt injection in GitHub Copilot enabled local code execution (CVSS 7.8 High).
Content filters built for static inputs weren't designed to catch attacks that route through retrieval pipelines, tool calls, or agent-to-agent handoffs. This guide evaluates the leading LLM guardrail solutions for prompt injection detection, RAG and retrieval poisoning protection, and agentic AI security — covering detection accuracy, latency, deployment complexity, and compliance audit capabilities.
Key Takeaways
- LLM guardrails are runtime controls that intercept malicious inputs and unsafe outputs — distinct from model alignment, which operates at training time
- Retrieval poisoning is a production threat: five malicious documents can manipulate AI responses with 90% success rate
- ML-based guardrails outperform rule-based approaches under adversarial conditions — clean-data accuracy is not the metric that matters
- Production-grade guardrails decide allow, restrict, or deny in under 100ms — across input, output, and agentic layers
- Regulated enterprises need tamper-evident, decision-level audit logs mapped to OWASP LLM Top 10, NIST AI RMF, and EU AI Act requirements
The LLM Threat Landscape in 2026: Prompt Injection and RAG Attacks
Understanding what you're defending against matters before evaluating any tool. The threat has split into two distinct classes, and each requires different defenses.
Direct vs. Indirect Prompt Injection
Direct injection is the familiar attack: a user submits crafted instructions designed to override the system prompt or manipulate model behavior. It's visible, attributable, and easier to detect because it arrives through the user input channel.
Indirect injection is structurally harder to stop. The attack payload arrives through content the agent retrieves and reads: PDFs in a RAG pipeline, MCP tool outputs, database records, external webpages. The attacker doesn't need access to the prompt interface; they just need to get a poisoned document into the retrieval corpus.
As OWASP notes, prompts can affect model behavior even when the content is imperceptible to human readers, as long as the model parses it.
Why Agentic AI Exploded the Attack Surface
Agents connected to tools, memory stores, and knowledge bases inherit every attack surface in that ecosystem. A successful injection no longer produces a bad text response — it can:
- Trigger unauthorized API calls or database writes
- Forward sensitive data to external endpoints
- Modify project configuration files
- Execute code in the local environment
CVE-2025-53773 illustrated exactly this: a prompt injection in GitHub Copilot manipulated project settings to enable auto-approval of tool calls, enabling local code execution. The official advisory classifies it as command injection with a CVSS 7.8 High score.
Why No Single Guardrail Is Enough
OWASP explicitly states that due to "the stochastic influence at the heart of how models work," there are no foolproof prevention methods. Defense-in-depth — multiple independent layers covering for each other — is the only production-viable architecture.
Best LLM Guardrail Solutions for Prompt Injection and RAG Protection in 2026
These solutions were selected based on detection accuracy under adversarial conditions, latency, coverage across input/output/agentic surfaces, RAG poisoning protection, and compliance audit trail quality.
PromptHalo
PromptHalo is a runtime security and trust platform built specifically for agentic AI. It runs in two phases: a red-teaming component that continuously attacks your agents, RAG layers, and tool chains to surface exploitable paths before deployment, and an inline enforcement component that blocks threats on every inference, tool call, and agent-to-agent handoff in real time.
What separates it from perimeter-style defenses is the closed-loop design. Attack patterns discovered during red-teaming are encoded into a shared Threat Library, which the runtime enforcement engine uses for production detection — so newly discovered attack patterns become runtime defenses without waiting for a new release cycle.
Detection performance: ML-based detection achieves a stated catch rate above 95% at under 5% false positives, versus approximately 35% catch rate and 15–20% false positives for rule-based approaches. Detection combines embedding-based scoring against the Threat Library with classifier-based risk scoring.
Agentic control: PromptHalo issues agent security passports that travel with each request, carrying policy, budget, and authority information. Risk profiling scores agent behavior continuously, and authority decay forces re-authorization when a time, step, or risk threshold is exceeded — so agents can't accumulate unlimited permissions over extended operations.
Deployment: Model- and vendor-agnostic, deploying via API gateway, agent mode, or inline middleware. No model retraining, no code rewrite, under one day to deploy.
| Dimension | Details |
|---|---|
| Key Detection Capabilities | Prompt injection (direct and indirect), jailbreaks, retrieval/RAG poisoning, data leakage, out-of-scope tool and API calls, agent-to-agent handoff threats |
| Deployment & Integration | Model- and vendor-agnostic; deploys in under a day; no model retraining or code rewrite; works across any AI application from any provider |
| Compliance & Audit | Decision-level, replayable, tamper-evident audit logs; append-only records capturing decision, reason, agent identity, session context, and timestamp; mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act |
GA Guard (General Analysis)
GA Guard is an adversarially trained guardrail family available in three tiers: GA Guard Core (the base model), GA Guard Lite (edge-optimized), and GA Guard Thinking (maximum adversarial hardening). All three are trained on red-team attack data and policy-driven synthetic data.
The standout capability is native 256k-token long-context moderation — which General Analysis describes as a first in the guardrail category — making it viable for agent trace moderation and memory-augmented workflows that exceed typical context limits.
Benchmark performance (vendor-reported, from Hugging Face model cards):
| Tier | Moderation F1 | Jailbreak F1 | Long-Context F1 | Latency |
|---|---|---|---|---|
| Core | 0.899 | 0.930 | 0.891 | 29ms |
| Lite | 0.875 | 0.898 | 0.885 | 16ms |
| Thinking | 0.906 | 0.933 | 0.893 | 650ms |
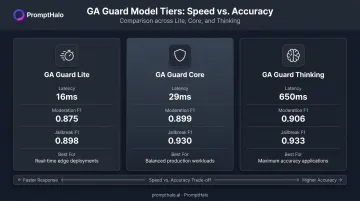
GA Guard Core hits 29ms latency, making it practical for inline production use. Thinking trades speed for adversarial hardening — better suited to batch moderation or high-stakes decisions where latency is acceptable. Note that the CC-BY-NC-4.0 license applies to the open Hugging Face releases; commercial production use requires separate licensing through General Analysis.
| Dimension | Details |
|---|---|
| Key Detection Capabilities | Content harm, prompt injection, jailbreaks, long-context agent trace moderation; trained on adversarial red-team datasets |
| Deployment & Integration | Open-source models on Hugging Face; managed via SDK/API; custom policy guardrails available through General Analysis |
| Compliance & Audit | Public benchmark transparency; custom policy training; CI/CD policy checks |
NVIDIA NeMo Guardrails
NeMo Guardrails is an open-source framework (Apache 2.0) that gives developers programmatic control over AI safety through Colang — a scripting language for defining conversational flows, topical constraints, and multi-LLM orchestration rules as code.
It's a strong fit for engineering teams already in the NVIDIA stack who want explicit ownership of their guardrail logic. Parallel rails execution in Colang 1.0 reduces latency when multiple checks run simultaneously.
The tradeoffs worth knowing before committing:
- Colang has a meaningful learning curve for teams new to policy-as-code
- The policy library requires ongoing engineering maintenance as threat patterns evolve
- NVIDIA has not published official F1 scores on adversarial prompt injection benchmarks
- Teams without dedicated AI security engineering capacity may find the policy authoring overhead unsustainable
| Dimension | Details |
|---|---|
| Key Detection Capabilities | Topical restrictions, conversational flow enforcement, multi-LLM orchestration safety, input/output policy rules via Colang scripts |
| Deployment & Integration | Open-source; self-hosted or cloud; integrates with NVIDIA inference stack; requires Colang policy authoring |
| Compliance & Audit | Policy-as-code supports auditability; teams must build their own logging and reporting pipelines |
AWS Bedrock Guardrails
For teams already running on Amazon Bedrock, AWS Bedrock Guardrails is the native safety layer. It covers content filtering across configurable severity levels, denied topic policies, PII detection across 32 entity types (with BLOCK or MASK actions), and contextual grounding checks built for RAG pipelines.
AWS marketing claims Bedrock Guardrails blocks up to 88% of harmful content, with Automated Reasoning checks delivering 99% accuracy for validation decisions. IAM-based authentication eliminates additional credential management for AWS-native teams.
Two limitations stand out. The No Free Lunch with Guardrails research found that stronger guardrails create usability tradeoffs, and long-context jailbreak prompts specifically exploit context-length limitations. Bedrock Guardrails also only works with Bedrock-hosted models — no cross-vendor coverage.
| Dimension | Details |
|---|---|
| Key Detection Capabilities | Content filtering (hate, violence, sexual, self-harm), denied topic policies, PII detection (32 entity types), prompt attack detection, contextual grounding checks |
| Deployment & Integration | AWS-native only; IAM authentication; tight integration with Bedrock model hosting; no cross-vendor support |
| Compliance & Audit | CloudTrail logging; integrates with AWS compliance tooling; limited out-of-the-box regulatory framework mapping |
Lakera Guard
Lakera Guard takes a different approach: API-first, low-latency, and designed to drop in without building from scratch. A single REST endpoint covers prompt injection and jailbreak detection across 100+ languages, making it one of the faster paths to a working detection layer.
On Lakera's own PINT Benchmark, Guard achieves a 95.22% PINT Score for prompt injection detection. Lakera's documentation confirms that it screens user input, reference content, and LLM output — making it more than a pure input-side layer. A threat analytics dashboard surfaces attack patterns over time, useful for understanding adversarial trends across your user base.
Where Lakera fits best: as a fast first-layer detector in a defense-in-depth stack. It doesn't natively provide agentic tool-call authorization policy, so teams building autonomous agent workflows will need to pair it with additional agentic controls for full coverage.
| Dimension | Details |
|---|---|
| Key Detection Capabilities | Prompt injection detection, jailbreak detection, multi-language support (100+), threat analytics dashboard |
| Deployment & Integration | REST API; simple integration; no model changes required; works across any LLM provider |
| Compliance & Audit | Threat analytics and logging dashboard; limited native compliance framework mapping; pairs well with additional agentic layers |
How We Chose the Best LLM Guardrail Solutions
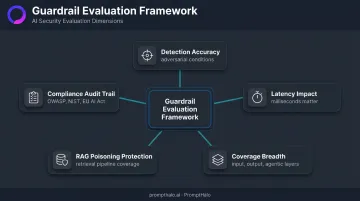
The Five Evaluation Dimensions
These solutions were assessed across:
- Detection accuracy under adversarial conditions — not clean-data benchmarks, which routinely overstate real-world performance
- Latency impact — tens of milliseconds keeps guardrails in the production hot path; seconds gets them disabled under load
- Coverage breadth — input, output, and agentic tool layers each require distinct defenses
- RAG/retrieval poisoning protection — the retrieval pipeline is an attack surface, not just user input
- Compliance audit trail quality — framework mapping to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act
The Benchmark Selection Problem
The most common mistake organizations make is selecting guardrails based on marketing benchmarks run against curated test sets. Research presented at NeurIPS 2024 SafeGenAI confirmed that transformer-based classifiers significantly outperform simpler baselines — but only when evaluated on adversarial prompts. Clean-data accuracy numbers are meaningless for production threat models.
For regulated enterprises, the decision criteria extend beyond accuracy:
- Compliance teams need audit trails mapped to the frameworks auditors actually use
- Product teams need latency that doesn't degrade user experience
- Security teams managing agentic AI need coverage of tool calls and retrieval pipelines, not just chat inputs
The Red-Teaming Imperative
Those criteria also expose a gap that benchmarks can't close: you don't know where your guardrails fail until someone tries to break them. Deploying without adversarial testing is security theater.
The evaluation process that produces durable results combines red-teaming to find failure points with runtime enforcement to contain the blast radius of those failures. Solutions that feed red-team findings back into their enforcement logic — through a shared threat library or continuous training pipeline — compound protection over time rather than holding a fixed position against an attack surface that changes faster than static rules can track.
Conclusion
LLM guardrails in 2026 are an architectural property, not a single-tool decision. The right solution depends on your specific threat model (direct injection, indirect RAG poisoning, agentic tool abuse, or all three), plus your compliance environment and whether you need to cover a single model or a multi-agent, multi-vendor AI stack.
When evaluating vendors, three checks matter most:
- Ask for adversarial benchmark results against real-world attack datasets, not synthetic tests
- Measure latency in your actual production pipeline, not vendor-provided lab conditions
- Verify that coverage extends to retrieval pipelines and tool calls, not just input/output filtering
For regulated environments, confirm that audit trails are tamper-evident, decision-level, and mapped to the frameworks your auditors expect.
For enterprises that need runtime security across agentic AI, PromptHalo covers prompt injection, retrieval poisoning, jailbreaks, and unauthorized tool calls — with real-time enforcement and compliance-ready audit trails. The platform red-teams your AI to find exploitable paths, then enforces trust on every agent action before it executes. Request a demo to see how it maps to your agent architecture.
Frequently Asked Questions
What is the difference between prompt injection and jailbreak attacks?
Prompt injection is a broad class of attacks where crafted inputs manipulate an LLM into ignoring its intended instructions — including indirect injection through retrieved documents or tool outputs. Jailbreaking is a specific subset that bypasses safety constraints through role-play, fictional framing, or persona manipulation. Both fall under OWASP LLM01 but require overlapping yet distinct defenses.
Is RAG still relevant for AI applications in 2026?
RAG remains the primary architecture for grounding LLM responses in proprietary or domain-specific knowledge, with adoption accelerating alongside agentic AI. It also introduces retrieval poisoning as a distinct attack vector — malicious content in indexed documents can manipulate agent behavior — making retrieval pipeline guardrails just as critical as input-layer defenses.
What is retrieval poisoning and how does it differ from direct prompt injection?
Retrieval poisoning is a form of indirect injection where malicious instructions are embedded inside documents, webpages, or database records that an agent retrieves and processes. Unlike direct injection, the attacker doesn't need access to the prompt interface — only to the retrieval corpus. The PoisonedRAG research demonstrated a 90% attack success rate by poisoning just five documents, making input-layer defenses alone insufficient.
Do LLM guardrails work with all AI models and providers?
It depends on the solution. Cloud-native guardrails are tied to a specific provider's infrastructure, while model-agnostic platforms like PromptHalo enforce controls across any LLM from any vendor without touching the underlying model. For multi-vendor or multi-agent stacks, that vendor-agnostic coverage is a critical evaluation criterion.
How do LLM guardrails affect inference latency?
Latency varies significantly by approach. Purpose-built ML-based guard models run in tens of milliseconds and are generally undetectable to end users. Approaches that route each check through a large general-purpose LLM can add several seconds per inference, making them impractical for real-time applications. Measure guardrail latency in your actual production pipeline, not just vendor benchmarks, before committing.
What compliance frameworks do LLM guardrails need to address in 2026?
The core frameworks are the OWASP LLM Top 10, NIST AI RMF, and the EU AI Act — which mandates evidence-grade logging and human oversight for high-risk systems, with those obligations applying from August 2026. Financial services organizations also face DORA requirements covering ICT and third-party risk that AI guardrail audit trails must support.


