
The security tools protecting those deployments weren't built for this threat model. Firewalls inspect network packets. DLP tools track file movement. Code scanners look for known vulnerabilities. None of them see a prompt injection embedded in a retrieved document, an agent making unauthorized API calls, or sensitive data leaking through natural language outputs.
This article covers exactly that gap: the unique threat model of LLM and agentic AI applications, why audit trails are both a security and compliance necessity, and how runtime enforcement closes the gaps that perimeter controls miss.
Key Takeaways
- LLM attacks live in natural language, not code — traditional AppSec tools can't patch or pattern-match them
- Audit trails must capture decisions, not just requests — standard API logs fall short for incident response and regulatory reporting
- Runtime enforcement requires five graduated actions (allow, restrict, challenge, deny, monitor), not binary block/pass
- RAG poisoning must be stopped at retrieval time — once a poisoned document reaches the model, the damage is done
- NIST AI RMF and the EU AI Act require documented evidence of controls — not just the controls themselves
Why Securing LLM Applications Is Different from Traditional AppSec
Traditional application security is built on a predictable foundation: the same input produces the same output, vulnerability classes are known, and patches close specific gaps. That model doesn't apply to LLMs.
The Non-Determinism Problem
LLMs are stochastic by design. The same prompt can produce different outputs across calls, model behavior can drift over time, and attacks arrive as natural language rather than malicious code. There is no CVE to patch when a prompt injection succeeds — the attack surface is the model's reasoning process itself.
NIST AI RMF 1.0 is explicit on this: AI risks are difficult to predict because models carry statistical uncertainty, emergent properties, and opacity. A deterministic security playbook simply has no equivalent control point to latch onto.
The Agentic Expansion
That unpredictability compounds when LLMs move beyond chat interfaces into autonomous agents. Each capability added — external API calls, RAG datastore queries, agent-to-agent handoffs — introduces a new point where a manipulated prompt can cause real downstream harm:
- Unauthorized tool execution triggered by a single crafted input
- Data leakage across systems the original prompt never explicitly targeted
- Retrieval poisoning that corrupts what the agent retrieves and acts on
- Scope creep where agents exceed their intended authority across multi-step tasks
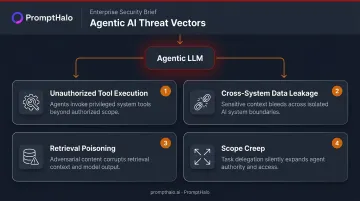
The risk spans application security, data security, and compliance, with no clear boundary between them — and no single team that owns it.
What Securing an LLM Application Actually Means
Securing an LLM application means controlling what happens at the inference layer, not at the model or infrastructure level. PromptHalo's platform operates without touching the underlying model, deploying in under a day with no model retraining and no code rewrite. Trust is enforced on every inference, tool call, and agent decision before the action executes.
The LLM Attack Surface: Threats That Existing Security Tools Miss
Prompt Injection (Direct and Indirect)
Direct injection occurs when a user crafts input designed to override the model's instructions. Indirect injection is harder to detect: malicious instructions are embedded in external content that the model retrieves — a poisoned document in a RAG pipeline, a compromised web page an agent visits, a manipulated search result.
OWASP's LLM01:2025 defines prompt injection as occurring when user prompts alter model behavior in unintended ways, and explicitly notes that inputs may affect the model even if imperceptible to humans. Rule-based pattern matching fails here because natural language attacks are specifically designed to evade known signatures.
Jailbreaks
Jailbreaks are a subcategory of prompt manipulation. They circumvent a model's safety guardrails to produce harmful, out-of-scope, or policy-violating outputs. Where prompt injection hijacks the model's instruction context, jailbreaks target the safety layer itself — a meaningful distinction for detection, since both attack vectors require interception at inference time, before the model acts on the input.
Retrieval Poisoning (RAG Poisoning)
In RAG-based systems, attackers insert malicious content into the knowledge base that the model queries. Research from PoisonedRAG demonstrated a 90% attack success rate when injecting just five poisoned texts into a database containing millions of entries. In regulated environments where models drive compliance workflows or financial decisions, that translates to attacker-controlled outputs with no visible entry point — and no network traffic for traditional security tools to flag.
Out-of-Scope Tool and API Calls
Agentic systems give models access to external tools: send email, execute code, query databases, process payments. OWASP's LLM06:2025 (Excessive Agency) identifies this as a condition where an LLM can call functions or interface with external systems, and an attacker — or a manipulated model — can abuse this access far beyond the intended scope.
API authentication confirms identity — it says nothing about whether a given action falls within the model's permitted scope. Without per-action enforcement, a single compromised agent interaction can cascade into unauthorized data access, financial transactions, or external communications.
Data Leakage Through AI Outputs
Sensitive information in the model's context window, system prompt, or retrieved documents can be extracted through carefully crafted queries. This differs from traditional data exfiltration: leakage occurs as generated summaries, encoded URLs, or natural language responses — not as file transfers that DLP tools monitoring network traffic are designed to catch.
Key indicators that distinguish AI-native data leakage from conventional exfiltration:
- Output contains verbatim system prompt fragments or internal configuration details
- Responses encode sensitive values inside URLs, markdown links, or base64 strings
- Repeated queries incrementally reconstruct restricted data across multiple turns
- Leakage passes through existing DLP filters because it resembles normal generated text

What Are Audit Trails in AI Applications and Why Do They Matter?
Decision-Level Logging vs. API Logs
Standard application logs record that a request was made. An AI audit trail records what the model received, what it decided, on what basis, and what action it took. In incident response, that distinction is the difference between a clear forensic record and guesswork.
When a successful prompt injection occurs, you need to replay exactly what the model processed and what it triggered downstream. Without a replayable audit trail, forensic investigation is guesswork and regulatory reporting is reconstruction after the fact.
PromptHalo's audit logs are append-only and tamper-evident — once an event is written, it cannot be modified or removed. Each record captures:
- The decision and its reason
- The acting agent or security passport identity
- Session and tenant context
- Timestamp
What Makes an Audit Trail "Evidence-Grade"
Three properties separate evidence-grade AI audit logs from standard logging:
- Tamper-evidence — append-only architecture ensures retroactive alteration is impossible
- Decision-level granularity — capturing reasoning context, not just inputs and outputs
- Framework mapping — logs mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act, so security teams and compliance functions work from the same record
Enforcement Actions as Measurable Evidence
PromptHalo logs five enforcement action categories on every decision: allow, restrict, challenge, deny, and monitor. Over time, this record answers questions that regulators and security teams both ask:
- How frequently are attacks occurring?
- Which workflows are most targeted?
- Are controls working, and can you prove it?
The EU AI Act's Article 19 requires providers of high-risk AI systems to retain automatically generated logs for a minimum of six months. Decision-level logs that capture enforcement actions give you that retention — and a record detailed enough to reconstruct exactly what happened, who authorized it, and whether controls held.
The Compliance Differentiator
That same evidentiary standard applies on the US side. In financial services, FINRA Regulatory Notice 24-09 confirms that existing supervision, communications, and books-and-records obligations extend to LLM use.
Audit log quality — not just existence — determines whether you can satisfy regulators who want to verify that automated decisions were made within approved scope with appropriate controls in place. Regulators aren't asking whether you kept logs. They're asking whether those logs can prove the decision was made within approved scope, with the right controls active at the time it ran.
Runtime Enforcement: How to Defend AI Applications at the Inference Layer
Inline, Real-Time Enforcement
Rather than scanning logs after the fact or relying on the model's own guardrails, runtime enforcement sits between the user and the model — evaluating every inference request and tool call before it executes.
PromptHalo's enforcement layer makes per-action decisions in under 100ms, applying one of five graduated responses:
| Action | When Applied |
|---|---|
| Allow | Request is within scope and policy |
| Restrict | Partial execution permitted with limits |
| Challenge | Additional verification required |
| Deny | Request blocked outright |
| Monitor | Logged without intervention |
Binary block/pass approaches create operational disruption. The five-action model lets security teams calibrate response without halting legitimate workflows.
ML-Based Detection vs. Rule-Based Approaches
Rule-based systems match known patterns — but prompt injection and jailbreaks are written in evolving natural language, specifically designed to evade known signatures.
According to Palisade's benchmark research, a rule-based detection layer achieved a 50% recall rate (meaning half of injections pass through undetected), while an ML-based BERT classifier reached 95% recall on the same dataset, with no increase in false positives.
PromptHalo's detection engine combines Threat Library signatures with classifier-based risk scoring, achieving over 95% catch rate at under 5% false positives versus roughly 35% catch and 15-20% false positives for pure rule-based approaches.

Security Passports and Authority Decay
Each agent in an agentic system operates under a signed security passport: a credential carrying its policy, budget, and authority scope. As an agent moves further from its original authorized task, its permissions narrow through authority decay — budgets across time, steps, and risk diminish as the agent operates, forcing re-authorization when an envelope is exceeded.
This directly limits blast radius when an agent is manipulated. An attacker who successfully injects instructions into an agent at step four of a workflow cannot retroactively claim the full permissions granted at step one.
Retrieval-Layer Defense
For RAG-based applications, enforcement must happen at retrieval time. PromptHalo's prompt injection protection is embedding-based, scored against a shared Threat Library, and covers both direct injection and retrieval/RAG injection — flagging content that appears to contain adversarial instructions before it enters the model's context window.
Once a poisoned document reaches the model's context window, the damage is already done. Catching it at retrieval is the only point in the pipeline where intervention is still effective.
The Closed-Loop Defense Model
PromptHalo's red-teaming function continuously attacks an organization's agents, RAG layers, and tool chains. Attack patterns discovered through that process are encoded into the shared Threat Library, which the runtime enforcement engine uses for production detection. A newly discovered attack pattern becomes a runtime defense without waiting for a release cycle. Protection compounds over time.
Connecting AI Security to Compliance Frameworks
OWASP LLM Top 10 as Shared Language
The OWASP LLM Top 10 for 2025 provides a reference taxonomy that security, development, and compliance teams can use to speak the same language about LLM application risk. The attack vectors covered in this article map directly to current entries:
- LLM01:2025 — Prompt Injection
- LLM02:2025 — Sensitive Information Disclosure
- LLM05:2025 — Improper Output Handling
- LLM06:2025 — Excessive Agency
Using OWASP numbering in audit logs and incident reports creates a shared classification that survives team and tool changes. NIST AI RMF and the EU AI Act build on that foundation, translating vulnerability classification into documented risk controls and legal obligations.
NIST AI RMF and the EU AI Act
NIST AI RMF's four functions — Govern, Map, Measure, and Manage — all require documented evidence of risk controls. Three of those functions directly shape how AI audit logging should be structured:
- Govern: Legal and regulatory requirements involving AI must be documented and managed
- Measure: AI system functionality must be monitored in production, with metrics and test results documented
- Manage: Incident tracking, response, and recovery must be followed and documented
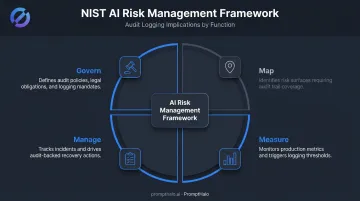
The EU AI Act sets harder requirements. Article 12 requires high-risk AI systems to automatically record events across the system's lifetime. Article 19 mandates that those logs be retained for at least six months.
From Compliance Burden to Continuous Evidence
When audit logs are mapped to framework controls from the moment of capture, security teams can generate regulatory reporting directly from the enforcement record — not reconstruct it manually after the fact.
For fintech and payments organizations facing regulators who want to verify that AI-driven decisions stayed within approved scope, this means teams arrive at regulatory reviews with evidence already assembled rather than racing to compile it.
Frequently Asked Questions
Frequently Asked Questions
How do you secure AI applications?
Securing AI applications requires runtime enforcement at the inference layer, going beyond perimeter controls and model guardrails. Key measures include detecting and blocking prompt injection and jailbreaks before they execute, enforcing per-action scope limits on agentic tool calls, and generating tamper-evident audit trails at the decision level.
What is an LLM audit trail and why does it matter?
An LLM audit trail is a decision-level record capturing what the model received, decided, and acted on, with tamper-evidence ensuring it cannot be retroactively altered. Standard API logs record only that a request was made. Decision-level logs are what incident response, forensic investigation, and regulatory reporting actually require.
What is prompt injection and how can it be prevented?
Prompt injection is an attack where malicious instructions embedded in user input or retrieved content override the model's intended behavior. Prevention requires ML-based detection at the inference layer, applied before the model processes the input. Pattern-matching filters fail here because natural language attacks are specifically designed to evade them.
What makes agentic AI harder to secure than traditional AI applications?
Agentic AI systems autonomously call tools, query external data, and hand off tasks to other agents, expanding the attack surface to every downstream action. Each tool call and agent handoff requires its own scope enforcement, security passport, and logging rather than a single authentication check at the entry point.
How do audit trails support AI regulatory compliance?
Frameworks like NIST AI RMF and the EU AI Act require documented evidence of risk controls for AI systems. Decision-level audit logs mapped to these frameworks allow organizations to produce regulatory reporting directly from their enforcement record rather than reconstructing it after the fact.
What is the difference between rule-based and ML-based LLM security?
Rule-based systems match on known attack signatures but fail against natural language attacks that evolve to evade detection. ML-based detection learns from behavioral patterns across a threat library, achieving roughly 95% recall on novel prompt injection and jailbreak variants compared to around 50% for rule-based approaches, with significantly fewer false positives.


