
Introduction
Generative AI is already running payroll systems, processing loan applications, and executing customer-facing workflows at scale. Security teams are defending that reality with tools built for a different one.
Traditional controls — firewalls, DLP, code scanners — operate on network traffic, data patterns, and static code. None of them see adversarial instructions embedded in natural language. With OWASP classifying prompt injection as LLM01:2025 — the top threat against large language models — deployed risk has outpaced available defenses.
NIST has responded. Between July 2024 and early 2026, the agency published or initiated four significant frameworks:
- NIST AI 600-1 — generative AI risk guidance
- NIST AI 100-2 (March 2025 update) — adversarial machine learning
- NCCoE Agent Identity Concept Paper — identity management for AI agents
- AI Agent Standards Initiative — emerging standards for agentic systems
Taken together, they give enterprises a threat taxonomy and a direction for action.
What follows breaks down what those documents actually say, how prompt injection behaves in agentic deployments, and the controls security teams need before the next incident — not after it.
Key Takeaways
- NIST AI 100-2 E2025 (March 2025) expanded its adversarial ML taxonomy to cover autonomous AI agent vulnerabilities — indirect prompt injection, tool supply chain attacks, and multi-agent abuse
- Prompt injection (OWASP LLM01:2025) is the primary vector NIST identifies against generative AI — and it's structurally more dangerous when agents act on retrieved data autonomously
- NIST research clocked novel agent attacks at an 81% task-hijacking success rate versus 11% for known baselines — most enterprise defenses are calibrated for the wrong threat
- COSAiS will extend SP 800-53 with AI deployment overlays; enterprises in regulated sectors should start gap analysis now
- Runtime enforcement is required to operationalize NIST guidance; input filters reduce surface area but cannot fully stop prompt injection against stochastic LLMs
NIST's 2025–2026 Generative AI Security Landscape
NIST's AI security publications have moved from governance scaffolding to operational specifics over the past two years. Understanding which document does what is the first step to using them effectively.
The Core Document Stack
| Document | Published | Primary Purpose |
|---|---|---|
| NIST AI 100-1 (AI RMF 1.0) | January 2023 | Governance framework: Govern, Map, Measure, Manage |
| NIST AI 600-1 | July 2024 | GenAI risk profile — 12 risks unique to or exacerbated by generative AI |
| NIST AI 100-2 E2025 | March 2025 | Adversarial ML taxonomy — now includes agentic AI attack categories |
| NCCoE Agent Identity Concept Paper | February 2026 | OAuth 2.0, SPIFFE/SPIRE, workload identity for AI agents |
AI 600-1 is a companion to the AI RMF, not a standalone compliance document. Its 12 named risks include confabulation, data privacy, information integrity, and information security — the last of which covers the lowered barriers to offensive cyber that generative AI creates. Regulated industries should treat all 12 as audit-ready categories now, not after an examiner asks.
AI 100-2 E2025 closed a significant gap in the 2023 edition. The March 2025 update extended NIST's adversarial ML taxonomy to cover AI agent vulnerabilities — indirect prompt injection, agent tool supply chain attacks, and agentic deployment contexts — that the original release addressed only partially.
The AI Agent Standards Initiative
On February 17, 2026, NIST announced the AI Agent Standards Initiative (CAISI), built on three pillars: agent interoperability standards, open-source protocol development (including Model Context Protocol), and fundamental research in agent identity and authorization.
NIST's January 2026 RFI (NIST-2025-0035) drew 937 submissions, including formal responses from the OpenID Foundation and a financial services coalition comprising the American Bankers Association, Bank Policy Institute, and BITS. That depth of engagement — spanning identity standards bodies and major banking trade groups — means security teams can expect agent identity and authorization requirements to surface in regulatory guidance well before industry consensus is reached.
Prompt Injection: NIST's #1 Generative AI Threat
Prompt injection is the attack class where user prompts or external data alter LLM behavior in unintended ways. NIST AI 100-2 E2025 defines it as untrusted input combined with a higher-trust prompt to produce behavior the system was never designed to allow.
Direct vs. Indirect Injection
The distinction matters enormously in enterprise deployments:
- Direct prompt injection — an attacker crafts malicious input in the prompt itself, requiring direct access to the user interface
- Indirect prompt injection — adversarial instructions are embedded in documents, emails, web pages, or database records that the model retrieves and acts on, with no direct attacker access required
Indirect injection is the harder problem. The malicious instruction arrives through a legitimate retrieval channel: a PDF the agent was asked to summarize, a calendar entry it was asked to reschedule, a web page it pulled for research. Input validation at the query layer doesn't see it.
Why Prevention Alone Is Insufficient
NIST AI 100-2 E2025 is unusually direct on this point: many mitigations are empirical and lack theoretical guarantees. Model-based detection cannot prevent all impermissible outputs. This isn't a gap NIST expects to close with better prompting. It's a structural property of how LLMs process natural language.
Successful prompt injection in enterprise deployments can result in:
- System prompt leakage and sensitive data disclosure
- Unauthorized execution of connected-system commands
- Privilege escalation across integrated services
- In agentic systems: cascading tool calls, data exfiltration, or downstream agent manipulation
The NIST-Aligned Mitigation Hierarchy
No single control closes the gap, but layered controls reduce it substantially:
- Constrain model behavior via system prompt controls and behavioral guardrails
- Enforce least-privilege access so agents can't act beyond their intended scope
- Implement semantic input and output filtering — not just pattern matching
- Segregate and label untrusted external content before it enters the model's context
- Require human approval for high-risk or irreversible agent actions
- Red-team regularly against indirect injection vectors, using frameworks like NIST's open-source AgentDojo-Inspect toolchain

The Multimodal Expansion
Those layered controls assume text-based input. Cross-modal injection removes even that assumption.
NIST AI 100-2 E2025 and OWASP both flag cross-modal injection as an emerging and under-defended threat category. Adversarial instructions can be hidden in images processed alongside text, bypassing text-focused filters entirely. Anthropic's November 2025 research on prompt injection in browser-use agents describes exactly this class of attack, where instructions hidden in web content hijack Claude Opus 4.5's browsing behavior.
Obfuscated variants using Base64 encoding, multilingual inputs, or adversarial suffixes complicate filter-based defenses further still.
Agentic AI and the Expanding Prompt Injection Attack Surface
Agentic architectures change the risk calculus. An autonomous agent doesn't just generate text — it reads from external data sources, writes back to them, invokes tools, chains tasks to subordinate agents, and accumulates context across sessions. A successful injection no longer manipulates a single model output — it can hijack an entire workflow.
The 81% Finding
NIST's January 2025 technical blog, "Strengthening AI Agent Hijacking Evaluations," reported a result that every security team running AI in production should internalize: novel attack techniques targeting agent-specific behavioral patterns achieved an 81% task-hijacking success rate, versus 11% for the strongest known baseline attack.
Three implications follow:
- Defenses calibrated to known attack playbooks substantially underestimate attacker capability against real agent deployments
- Single-shot evaluations are insufficient — multi-attempt testing (25 attempts per task in the NIST evaluation) raised success rates further and better reflects real attacker behavior
- Per-task risk variation is wide; aggregate statistics mask operations where hijacking succeeds at near-100% rates
Agent Authorization: The Gap Nobody Fixed
NIST's NCCoE concept paper (February 2026) identified a structural problem that most enterprise AI deployments share: agents either inherit full user-level permissions (over-privileged) or operate under generic service account credentials (unauditable). Neither model supports least-privilege enforcement.
The concept paper proposes binding agent permissions to specific delegated tasks and time windows, using:
- OAuth 2.0 scoping for task-specific permission grants
- Pushed Authorization Requests for secure, server-side authorization initiation
- SPIFFE/SPIRE workload identity for cryptographic agent authentication
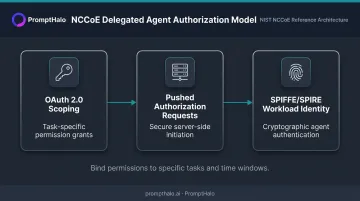
This isn't a finished standard — it's a direction. Enterprises building agent deployments today should be designing authorization architectures that can accommodate these patterns when they mature.
COSAiS: The Compliance Trajectory
NIST's COSAiS project (Control Overlays for Securing AI Systems) will deliver dedicated SP 800-53 overlays for single-agent and multi-agent deployments, translating abstract security requirements into AI-specific implementation guidance.
NIST has not confirmed an official finalization timeline. Enterprises in regulated sectors shouldn't wait — beginning gap analysis against available COSAiS materials now positions teams ahead of the compliance curve rather than scrambling when overlays finalize.
Operationalizing NIST Guidance: What Security Teams Must Do Now
The four AI RMF core functions — Govern, Map, Measure, Manage — provide the operating structure. Here's what each requires in practice for AI security in 2026.
Step 1: Build an AI Agent Inventory
You cannot protect what you haven't enumerated. Every production agent deployment — commercial, vendor-provided, or internally built — needs documentation covering:
- Scope of tool and API access
- Data sources read from and written to
- Human identities the agent acts on behalf of
- The authorization model governing its actions
This inventory is the prerequisite for gap analysis against COSAiS overlays. Enterprises that cannot enumerate deployed agents cannot demonstrate compliance, regardless of which framework applies.
Step 2: Expand Red Team Coverage to Agent-Specific Attack Vectors
Most existing penetration testing programs test direct adversarial inputs. They do not test indirect prompt injection via documents, calendar entries, email, or retrieved web content — which is where real attackers will focus.
Red team exercises should explicitly scope these channels, using NIST's AgentDojo-Inspect toolchain or equivalent frameworks. Use multi-attempt testing protocols rather than single-shot evaluations. The NIST finding of 81% success over 25 attempts versus lower single-shot rates illustrates why single evaluations understate probabilistic LLM risk.
Step 3: Enforce Least-Privilege Authorization for Every Agent Action
Map current agent access patterns against the NCCoE's delegated authorization model. Agents running under full user permissions or generic service accounts represent unacceptable risk — not because of what they're doing now, but because a successful injection attack inherits whatever permissions the agent holds.
Narrowly scoped agents limit the blast radius of any attack that gets through. An agent with read-only access to a specific data source cannot exfiltrate from sources it was never authorized to touch, even if an adversarial instruction tries.
Step 4: Implement Runtime Detection as the Final Control Layer
Policy controls and input validation reduce surface area. They don't eliminate prompt injection risk — and NIST says so explicitly. Runtime enforcement is the layer that catches what pre-deployment controls miss.
This means detection at inference time: analyzing what the model receives and how it responds, validating tool calls before they execute, and enforcing per-action scope in real time.
PromptHalo's runtime security platform operates inline on every inference, tool call, and agent-to-agent handoff, making allow/restrict/challenge/deny/monitor decisions in under 100ms. ML-based detection achieves a stated catch rate above 95% at under 5% false positives, with no model retraining or code changes required. The platform deploys via API gateway, agent mode, or inline middleware in under a day.
Step 5: Generate Decision-Level Audit Trails
Application-level logging — recording that a request was made and a response returned — is not sufficient for AI compliance. Decision-level logging captures what the model received, what it decided, what tools were invoked, and under what authority, as a tamper-evident record at the per-inference level.
This distinction matters for two reasons. Anomaly detection requires the granularity to surface behavioral drift that aggregate logs would obscure. And regulatory evidence requires records that demonstrate control effectiveness at the decision level, not just system availability.
PromptHalo's append-only audit logs capture each decision with its reason, the acting agent identity, session and tenant context, and timestamp. Each record is structured for compliance export and mapped to NIST AI RMF, OWASP LLM Top 10, and the EU AI Act.
What This Means for Regulated Enterprises
The NIST AI RMF remains a voluntary framework. But the compliance landscape around it is anything but passive.
The financial services coalition's joint response to NIST's RFI — signed by the American Bankers Association, Bank Policy Institute, and BITS — called for voluntary, consensus-based guidance on agent deployments and secure automated integrations. The OpenID Foundation's response focused on agent identity, workload identity federation, and transaction tokens as foundational requirements.
These aren't abstract positions. They reflect where financial institutions are actively deploying and where regulatory conversations are heading.
The Audit Readiness Gap
Most existing audit programs derive from traditional IT frameworks. They cover network controls, access management, and data handling — but bias drift, retrieval poisoning, and indirect prompt injection fall entirely outside their scope. Security teams preparing for AI audits in 2026 need to:
- Extend control libraries to include NIST AI 100-2 E2025 threat categories
- Demonstrate that controls were tested against agent-specific attack scenarios
- Produce evidence at the decision level, not just system-level logs
The gap between what existing audit programs cover and what AI systems actually do is the single most common compliance risk in enterprise AI deployments right now.
Compliance as Competitive Differentiation
In regulated sectors — fintech, payments, healthcare — demonstrating a documented AI security posture is becoming a procurement prerequisite, one that directly affects which deals get closed. Enterprises that can show runtime controls, red team results, and audit-ready logs aligned to recognized frameworks close deals that competitors without that documentation cannot.
Treating NIST AI RMF alignment as a proactive program — rather than a reactive compliance exercise — produces measurable advantages:
- Faster deployment: documented controls reduce internal approval cycles for new AI features
- Lower regulatory friction: pre-mapped evidence shortens examiner review timelines
- Procurement leverage: a verifiable AI security posture becomes a differentiator, not just a checkbox
Frequently Asked Questions
What is NIST AI 100-2 and how does it address prompt injection in 2025?
NIST AI 100-2 is NIST's authoritative taxonomy for adversarial AI attacks and mitigations. The March 2025 edition (E2025) expanded coverage to include autonomous AI agent vulnerabilities — including indirect prompt injection and supply chain attacks on agent tools — that were only partially addressed in the 2023 edition. It also acknowledges that current mitigations cannot provide fool-proof prevention.
Is NIST's generative AI security guidance mandatory for enterprises?
The AI RMF and companion documents (AI 600-1, AI 100-2) are voluntary frameworks. However, federal agencies, financial regulators, and enterprise procurement processes increasingly reference them. Enterprises in regulated sectors should treat alignment as a practical requirement, not optional guidance.
What is the difference between direct and indirect prompt injection?
Direct prompt injection involves an attacker crafting malicious input in the prompt itself, requiring direct access to the interaction. Indirect prompt injection embeds adversarial instructions in external data sources — documents, emails, web pages — that the LLM retrieves and acts on. In agentic systems, indirect injection is more dangerous because it arrives through legitimate retrieval channels, bypassing query-time input validation entirely.
What is COSAiS and why should enterprises monitor it?
COSAiS (Control Overlays for Securing AI Systems) is NIST's project to extend SP 800-53 with AI-specific implementation overlays, including for single-agent and multi-agent deployments. NIST hasn't confirmed a final publication date, but enterprises in regulated sectors should begin gap analysis against available materials now rather than waiting.
Why do traditional security tools fail to detect prompt injection?
Firewalls, DLP tools, and code scanners operate on network traffic, data patterns, and static code — none of which captures the semantics of adversarial instructions embedded in natural language or retrieved content. Detecting prompt injection requires inference-time analysis of what the model receives and how it responds, which is outside the visibility of conventional security stacks.
How can organizations use the NIST AI RMF to build defenses against generative AI threats?
The four core functions map directly to practical controls:
- Govern: Establish AI risk ownership and policies covering GenAI threats
- Map: Enumerate all agents and external data sources
- Measure: Red team against NIST AI 100-2 E2025 attack categories using multi-attempt testing
- Manage: Implement runtime enforcement and decision-level audit trails that demonstrate continuous control effectiveness


