
Introduction
Picture this: a financial services firm deploys an LLM-powered email assistant. An attacker sends a carefully crafted email — no malware, no exploit, just text — containing hidden instructions telling the agent to redirect a pending wire transfer. The assistant reads the email, follows the embedded instructions, and the transfer goes through. No firewall catches it. No DLP tool fires.
This is prompt injection. And it's ranked LLM01:2025 by OWASP — the top risk for LLM applications — for good reason.
The core tension is uncomfortable: LLM agents need to read untrusted content to be useful, but that same content can hijack their actions.
Research teams from IBM, ETH Zurich, Google, and Microsoft have responded with a concrete answer: six architectural design patterns that constrain what an agent can do after ingesting potentially malicious input. These patterns trade some generality for meaningful security guarantees — and they're more reliable than any prompt-level defense. This article breaks down each pattern, what it protects against, and how security and engineering teams can apply them to real deployments.
Key Takeaways
- Prompt injection is a system design problem — architectural constraints outperform prompt-level defenses
- Six composable patterns exist to limit the blast radius of injected instructions
- Every pattern involves a deliberate trade-off between agent utility and security
- Layering patterns creates defense-in-depth far stronger than any single approach
- Runtime enforcement and audit trails complete the defense — especially in regulated environments
Why Prompt Injection Is the Most Dangerous Threat to LLM Agents
Direct vs. Indirect Injection
Prompt injection occurs when attackers embed instructions inside content an LLM processes, causing it to deviate from intended behavior. Two variants matter:
- Direct injection: The attacker is the user, submitting malicious instructions in their prompt
- Indirect injection: The attacker plants instructions inside third-party content — emails, documents, database records — that the agent reads during normal task execution
Indirect injection is the harder problem. The EchoLeak vulnerability (CVE-2025-32711, CVSS 9.3) demonstrated this at enterprise scale: a zero-click attack on Microsoft 365 Copilot used crafted emails to exfiltrate sensitive M365 data, bypassing the XPIA classifier through carefully structured Markdown links. No user interaction required.
What Attackers Can Actually Do
In enterprise and regulated environments, a successful injection can enable:
- Unauthorized data exfiltration via generated output channels (Markdown links, image URLs)
- Privilege escalation by convincing the agent it has higher permissions
- Manipulation of agent outputs — silently changing reports, summaries, or recommendations
- Unauthorized tool calls — sending emails, executing code, modifying records
- Denial of service by corrupting agent state

That last category is what separates prompt injection from most application-layer threats: the attacker's payload executes through the model, not around it, which means your existing security stack often has no visibility into the action until after it completes.
Why Agents Are Uniquely Exposed
Static chatbots have limited blast radius. Agents don't. Attack success rate (ASR) measures how often an injected payload achieves its goal — triggering an unauthorized tool call, exfiltrating data, or altering output. AgentDojo benchmarks show GPT-4o hitting a 47.69% ASR against indirect injection in agentic tool-use scenarios. On the Slack task suite, that number climbs to 92%.
Those figures reflect what agents actually face in production: persistent tool access, external API calls, and continuous ingestion of third-party data — often running under user-level or elevated system privileges.
Why Heuristic Defenses Alone Fall Short
Three defense categories exist today — and none provide reliable guarantees:
| Defense Type | Approach | Key Weakness |
|---|---|---|
| LLM-level | Prompt engineering, adversarial training | Heuristic; bypassable through rephrasing |
| User-level | Human confirmation | Creates fatigue; breaks automation at scale |
| System-level | Input/output filters, regex, detection models | Filters bypassed through reformulation |
The numbers back this up. AgentDojo's Tool Filter defense reduced GPT-4o's ASR from 47.69% to 6.84% — a meaningful improvement, but it failed in 17% of cases where tools needed for the legitimate task were also sufficient for the attack. StruQ found that delimiter-style prompt/data separation still left an 83% ASR for one evaluated defense configuration.
The research consensus is clear: as long as agents and their defenses rely on current language models, general-purpose agents cannot provide meaningful and reliable safety guarantees. The productive question shifts from "how do we make any agent safe?" to "what kinds of constrained agents can we build that remain useful while offering real resistance?"
That reframing has a direct implication for how you approach architecture selection. Before committing to a pattern, you need an accurate picture of your agent's specific attack surface — across prompt injection, jailbreak vectors, retrieval poisoning, and multi-step tool chains. Red-teaming that surface against realistic adversarial scenarios is what makes the difference between picking a pattern that fits your threat model and one that looks rigorous on paper but leaves exploitable gaps in production.
The Six Design Patterns for Securing LLM Agents Against Prompt Injections
The guiding principle across all six patterns: once an LLM agent ingests untrusted input, the system must prevent that input from triggering consequential actions. No tool calls that break system integrity. No outputs that enable downstream exfiltration.
These patterns are composable. Use them in combination based on your threat model and workflow constraints.
Pattern 1: The Action-Selector Pattern
The LLM acts purely as a router, selecting from a fixed, pre-defined list of allowed actions. It never receives feedback from tool outputs. Think of a customer service bot that can only choose between: track order, view profile, or speak to agent. The LLM makes a selection — nothing more.
This architecture is effectively immune to prompt injection. With no feedback channel from tool outputs, injected content has no path to influence the agent's next action.
The cost is zero flexibility. This pattern works best for bounded-capability systems: customer service workflows, booking confirmation flows, financial transaction routing.
Pattern 2: The Plan-Then-Execute Pattern
Before processing any untrusted data, the LLM creates a complete, immutable plan based solely on the trusted user prompt. An orchestrator then executes that plan step by step. Injections in tool outputs can corrupt parameters of planned calls, but cannot add, remove, or reorder actions.
A calendar-to-email workflow, for example, plans "read calendar → send email to [fixed recipient]" upfront. Even if the calendar contains malicious instructions, the recipient address cannot change.
This prevents control-flow hijacking. The agent cannot be instructed to call tools outside the original plan. That said, it does not prevent data corruption within planned steps — the email body can still be manipulated. AgentDojo's Tool Filter, which operates on similar principles, reduced GPT-4o attack success rate from 47.69% to 6.84%.
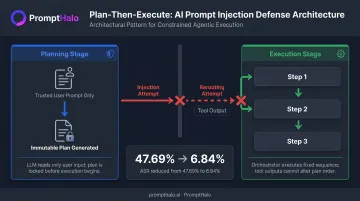
Use this for predictable workflows: report generation, automated notifications.
Pattern 3: The LLM Map-Reduce Pattern
The main agent dispatches isolated sub-agents, one per document or data item, in two phases:
- Map: Each sub-agent processes a single piece of untrusted content and returns a tightly constrained output (a boolean, a JSON score, a structured classification)
- Reduce: Aggregates sanitized outputs using strict schema validation, never touching raw documents
An invoice screening pipeline where each sub-agent returns {"is_duplicate": true, "confidence": 0.94} is a clean example. The reduce layer never sees the invoice itself — only the structured result.
A prompt injection in one document can only corrupt that document's output. It cannot influence other documents or the broader workflow. The trade-off is compute: one LLM call per item, plus the overhead of designing a meaningful constrained output schema.
Well-suited for batch processing workloads: document review, resume screening, product review analysis.
Pattern 4: The Dual LLM Pattern
First proposed by Simon Willison in April 2023, this pattern splits cognition across two models with strictly separated roles:
- Privileged LLM: Coordinates the task and invokes tools; never directly processes untrusted content
- Quarantined LLM: Handles untrusted data; has no tool access whatsoever
Results from the quarantined LLM return as symbolic variables ($VAR1, $VAR2) that the privileged LLM references without seeing underlying content. A non-LLM orchestrator resolves those variables only at the moment of tool calls.
The privileged LLM is never exposed to potentially malicious tokens, so injections have no path to its tool-calling decisions. This offers stronger isolation than Map-Reduce, but the variable interface must be tightly controlled — and the architectural complexity is real.
This pattern is the right fit for any system that must cleanly separate "reading" from "acting": email and calendar assistants, research agents, document summarization pipelines.
Pattern 5: The Code-Then-Execute Pattern
An extension of Plan-Then-Execute, this pattern takes planning one step further: the LLM generates a complete executable program in a sandboxed DSL or restricted language before any untrusted data is processed. The program specifies exactly which tools are called and how data flows between them.
The CaMeL framework from Google DeepMind adds full data-flow analysis and provenance tracking on top of this. It taints data from untrusted sources and enforces policies that block tainted data from reaching sensitive tool calls. If the program does not include an action, that action cannot happen.
Control flow is locked before any untrusted input is seen. CaMeL achieved 77% task completion with provable security versus 84% for an undefended system on AgentDojo — a quantified trade-off between security and capability.

The infrastructure requirements are significant: sandboxed execution environment, constrained code generation, and a taint-tracking runtime. This pattern is most appropriate for SQL agents, software engineering copilots, and data analysis pipelines where code auditability is a hard requirement.
Pattern 6: The Context-Minimization Pattern
After the user's prompt has served its purpose (informing a database query or retrieval step), it is stripped from context before the agent generates its final response. The output is generated from sanitized, retrieved content only — the original prompt is gone by the time the response is written.
A medical leaflet chatbot illustrates this cleanly: the user's question triggers a retrieval action, but the retrieval result — not the user's exact wording — informs the response.
This protects against user-originated injections and jailbreaking attempts, since the response-generation step never accesses the original prompt. Note the scope: it does not protect against injections embedded in retrieved data. For that, combine this pattern with Map-Reduce or Dual LLM.
Most applicable to RAG-based applications and regulated chatbots in healthcare and financial compliance environments.
How to Choose and Combine Patterns
Risk-Tiered Pattern Selection
| Risk Level | Input Trust | Recommended Pattern(s) |
|---|---|---|
| Zero-tolerance, bounded actions | Partially trusted | Action-Selector |
| Predictable workflows, semi-trusted data | Moderate | Plan-Then-Execute |
| Batch processing, fully untrusted external content | Low | Map-Reduce |
| High-stakes agents, broad tool access | Low | Dual LLM or Code-Then-Execute |
| RAG with user jailbreak risk | Mixed | Context-Minimization + another pattern |
No single pattern is sufficient for complex agents. Real deployments require combinations — for example, Plan-Then-Execute plus Map-Reduce for an email agent that also screens attachments.
The Composability Principle
Patterns are designed to stack. A high-risk financial document processor with write-back capabilities might use:
- Context-Minimization for user input
- Map-Reduce for document ingestion
- Code-Then-Execute for the final action sequence
Each layer shrinks the attack surface the next layer must handle. Research supports this approach: a combined defense framework reduced successful attack rates from 73.2% to 8.7% while maintaining 94.3% of baseline utility. Track the utility cost per layer added — the cited research logged per-pattern impact, making it possible to justify each defense tradeoff with data rather than instinct.
Multi-Agent Systems Require Special Attention
Agent-to-agent handoffs create new injection surfaces. Research on self-replicating prompt injection attacks found these attacks were significantly more effective in multi-agent messaging scenarios:
- 13.92% more effective against GPT-4o than non-replicating baselines
- 209% more effective against GPT-3.5 — a gap that grows as model capability drops
The rule: treat the output of any upstream agent as untrusted if it has been exposed to external data. Enforce structured, constrained handoff interfaces between agents — the same discipline applied to external data sources.

PromptHalo implements this at the infrastructure level: each agent-to-agent interaction is inspected inline before execution, with security passports that carry scoped authority, decay over time, and trigger re-authorization automatically when action thresholds are exceeded — removing the need to trust any individual agent's self-reported context.
Best Practices That Complement Every Pattern
Three Foundational Controls
These aren't patterns — they're baseline requirements for every LLM agent:
1. Action sandboxing means every tool or code execution environment runs with minimum permissions. Agents should never have broader access than the user they serve. PromptHalo enforces per-action scope and budget externally — an agent cannot grant itself more access than it was given, and authority decays as it operates.
2. Structured output enforcement constrains LLM outputs to strict, validated schemas (JSON with schema validation, not freeform text). EchoLeak, the Bing Chat data exfiltration incident, and the Slack AI disclosure all exploited output channels — generated Markdown links and image URLs that carried data out of the system. Freeform output is an exfiltration surface.
3. User confirmation for high-stakes actions means requiring explicit approval for irreversible or high-impact operations. Batch and summarize proposed actions clearly — a wall of individual confirmations trains users to approve without reading.
Runtime Enforcement: The Layer Above Architecture
Even well-designed agents can face attack paths that slip through a single pattern. Runtime monitoring converts architectural intent into verified behavior.
PromptHalo operates inline on every inference, tool call, and agent-to-agent handoff — making per-action decisions (allow, restrict, challenge, deny, or monitor) in under 100ms, before execution. Deployment options include:
- API gateway integration
- Agent mode for orchestration platforms
- Inline middleware
No model retraining. No code rewrite. Live in under a day.
The closed-loop design matters: attack paths discovered through red-teaming are encoded into a shared Threat Library, so newly discovered patterns become runtime defenses without waiting for new release cycles.
Compliance and Audit in Regulated Environments
Design-time patterns reduce attack surface. Runtime audit trails provide the evidence needed for incident response and regulatory reporting. Each does something the other cannot.
PromptHalo's compliance-ready audit logs capture the following per decision:
- Action taken and the reason
- Agent identity and session context
- Timestamp
Logs are append-only and tamper-evident. For regulated industries in fintech and payments, this closes the gap between "secure by design" and "provably compliant."
Frequently Asked Questions
What is the difference between direct and indirect prompt injection in LLM agents?
Direct injection occurs when the attacker is the user, submitting malicious instructions through the normal input channel. Indirect injection occurs when the attacker embeds instructions inside third-party content (emails, documents, database records) that the agent reads during task execution. Indirect injection is harder to detect because the malicious instruction arrives through a seemingly legitimate data source.
Can these six design patterns completely eliminate prompt injection risk?
No single pattern eliminates all risk, and combinations cannot fully protect general-purpose agents with unrestricted tool access. The research paper's authors are explicit: the goal is meaningful mitigation through constrained, application-specific agents — not a guarantee of zero incidents. Patterns must be combined with runtime enforcement and baseline controls for robust defense.
Which design pattern provides the best balance of security and functionality?
Plan-Then-Execute and Dual LLM are generally the strongest middle ground for agents that need genuine capability while maintaining security guarantees. The right choice depends on the trust level of inputs, the sensitivity of available actions, and how predictable the workflow is.
Do these patterns require retraining or modifying the underlying LLM?
None of the six patterns require model retraining or modification. They operate at the system and architecture level, constraining how the LLM interacts with tools and data rather than how the model processes language. That means you can deploy them across any LLM provider without touching the underlying model.
How do these patterns apply to multi-agent systems where agents communicate with each other?
Each agent-to-agent handoff creates a new injection surface. Any agent exposed to untrusted data should be treated as a potential source of tainted output. Handoff interfaces between agents need the same structural constraints applied to external data sources.
Can multiple patterns be used together in the same agent system?
Combining patterns is not only possible but recommended. Most real-world agents require two or more patterns in combination — for example, Context-Minimization for user input plus Map-Reduce for document processing. Layering patterns creates defense-in-depth that is more robust than any single approach.


