
The business cost of getting this wrong is concrete. IBM found that shadow AI increased average breach costs by $670,000, and 97% of organizations that experienced AI-related breaches lacked proper AI access controls.
None of this is an accident. AI agents and LLM-powered applications are not secure by default. Their probabilistic, non-deterministic nature means firewalls, DLP tools, and code scanners were built for a different threat model entirely. Defending these systems requires purpose-built controls applied at every layer — identity, data, runtime, and agentic workflows.
Key Takeaways
- AI attacks operate at the semantic layer — through language, not malicious binaries — making conventional defenses blind to them
- The most dangerous threats: prompt injection, jailbreaks, RAG poisoning, data leakage, and over-permissioned tool calls
- Effective defense stacks least-privilege identity, input/output filtering, runtime enforcement, and agentic guardrails
- Map controls to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act for compliance coverage
- AI security is continuous — red-team before deployment, enforce at runtime, monitor always
Why AI Agents and LLMs Create a Uniquely Dangerous Attack Surface
Traditional software does what it's told, deterministically. LLMs approximate statistical distributions — the same input can produce different outputs, and attackers can probe repeatedly until the model behaves unsafely. NIST's Generative AI Profile (AI 600-1) states directly that "conventional cybersecurity practices may need to adapt or evolve" for generative AI. That gap is where AI-native attacks live.
Agents Amplify the Risk Beyond the Chatbot
A standalone LLM produces text. An agent executes actions — calling APIs, querying databases, sending emails, triggering transactions. When a prompt injection succeeds against a chatbot, you get a harmful response. When it succeeds against an agent, you get unauthorized real-world operations, often at machine speed before any human can intervene.
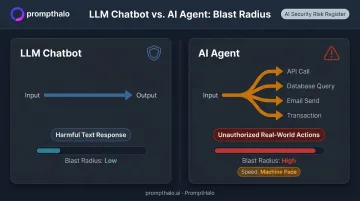
OWASP defines this under LLM06 (Excessive Agency): an agent granted broad permissions can perform damaging actions in response to manipulated outputs. The more access an agent holds, the wider the damage when that access is exploited.
The Non-Human Identity Problem
AI agents need user accounts, API keys, and workflow permissions to operate. CyberArk reports that machine identities already outnumber human identities 45:1, with 68% of organizations expecting that ratio to grow by at least 50% within the year. These identities are systematically under-secured:
- Rarely protected by MFA
- Often hold persistent, long-lived credentials
- Receive far less monitoring than human user accounts
That combination creates high-privilege footholds that attackers actively target — and that most existing security stacks aren't built to detect.
The AI-Native Threat Landscape: Attacks You Need to Prepare For
Prompt Injection and Jailbreaking
OWASP ranks LLM01:2025 Prompt Injection as the top vulnerability in its 2025 LLM Top 10. There's a reason for that.
Direct prompt injection occurs when a user's input directly overrides system-level instructions: the model ignores its guidelines, reveals its system prompt, or behaves in ways the developer never intended. Indirect prompt injection is harder to catch — an agent retrieves external content (a document, a web page, a tool output) that contains hidden instructions, then processes them as legitimate context.
A 2025 controlled study found prompt injection attacks succeeded in 94.4% of evaluated scenarios by turn 4 and persisted in 69.4%. These attacks are invisible to network-level defenses because they operate as natural language.
Jailbreaking is related but distinct. It targets the model's alignment training to produce outputs the model was trained to refuse: dangerous instructions, harmful content, or system prompt disclosure. Neither attack leaves a fingerprint that a traditional security tool can detect.
Data Poisoning and Retrieval Poisoning
Training data poisoning introduces malicious patterns, backdoors, or biased outputs during model training, corrupting integrity at the source. In agentic systems, retrieval poisoning is the more immediate concern.
The scale of the risk is well-documented:
- Injecting just 5 malicious texts into a large retrieval corpus achieved 90% attack success (PoisonedRAG research), rising to 97% in black-box settings
- CVE-2025-32711 (EchoLeak) — a zero-click prompt injection flaw in Microsoft 365 Copilot — enabled remote, unauthenticated exfiltration of enterprise data from a production system

When an agent's RAG pipeline is poisoned, every inference that draws from that knowledge base is potentially compromised.
Sensitive Data Leakage and Model Memorization
LLMs memorize training data. Researchers extracted over 10,000 unique verbatim training examples from ChatGPT for approximately $200 in API queries. In enterprise deployments, this risk compounds: agents regularly process PII, financial records, and credentials through tool interactions that may be logged, used for fine-tuning, or surfaced in outputs.
EchoLeak confirmed what many enterprises had only theorized: production AI systems, not sandboxed prototypes, are the target.
Over-Permissioned Agents and Misconfigured Tool Access
If a customer service agent has write access to production databases, a single successful prompt injection can cascade into a database modification, a credential leak, or an unauthorized transaction.
OWASP LLM06 frames this as the blast radius problem: excessive functionality, permissions, or autonomy allow damaging actions to propagate through an organization's systems faster than humans can intervene.
Uncontrolled planning loops (ReAct, Tree-of-Thoughts) compound this further. An agent executing iterative tool calls can accumulate harm across dozens of actions before any single step triggers an alert.
Security Guidelines for AI Agents and LLM-Powered Applications
Securing AI agents and LLM-powered applications requires a multi-layered program spanning identity, data, runtime behavior, and agentic controls. A gap in any single layer creates exploitable exposure across the entire pipeline.
Identity and Least-Privilege Access Controls
Apply least privilege rigorously — treat every agent as a privileged, non-human identity with its own access policy:
- Scope permissions to the task: Each agent should hold only the access its current task requires, with permissions decaying as the task completes
- Use short-lived credentials: Avoid persistent refresh tokens; scope tokens to specific tasks and rotate them regularly
- Enforce scope-based authorization on every API call: Use OAuth scopes to restrict reachable endpoints, and use token claims to enforce fine-grained, context-aware decisions
- Prevent token reuse across pipeline components: In multi-agent or MCP-based architectures, each component should receive its own appropriately scoped token — not a shared high-privilege credential

PromptHalo's Runtime Security solution addresses this directly through agent security passports — signed documents that carry each agent's identity, authority level, and permission scope across every inference, tool call, and handoff. Authority decays as the agent operates; when a budget envelope is exceeded, re-authorization is required before the agent can continue.
Securing Inputs, Outputs, and Data Pipelines
On the input side:
- Separate system prompts from user-supplied content at the architecture level
- Validate and sanitize inputs before they reach the model
- Deploy AI-specific input filtering that detects adversarial prompts, jailbreak patterns, and out-of-scope instructions
On the data pipeline side:
- Scan training datasets and RAG vector stores for PII, secrets, and proprietary information
- Enforce access governance so only authorized agents can query specific knowledge bases
- Apply masking or redaction for sensitive fields that agents process but should never surface
On the output side:
- Monitor model outputs in real time for data leakage — PII, credentials, internal system details
- Block responses that attempt to exfiltrate data or route users toward harmful actions
- Apply inline inspection before responses reach users or downstream systems
PromptHalo's Data Leakage Prevention service handles this inline — detecting sensitive information in output streams at the edge, before exposure occurs.
Runtime Enforcement and Behavioral Monitoring
Perimeter controls are insufficient for AI. Enforcement must happen at the inference layer — inline, on every action.
Every agent inference, tool call, and agent-to-agent handoff should pass through a runtime enforcement layer that evaluates the action against security policy before it executes. PromptHalo's Runtime Security solution sits inline on every action, making allow, restrict, challenge, deny, or monitor decisions in under 100ms — with no model retraining or code rewrites required.
Pair runtime enforcement with behavioral monitoring:
- Establish behavioral baselines per agent
- Alert or block on deviations — unusual API call patterns, out-of-scope resource access, abnormal output volumes, repeated probing behavior
- Generate tamper-evident, decision-level audit logs capturing what the agent did, why, under what identity, and when
Those logs matter beyond security investigation. The EU AI Act (Article 12) requires automatic logging for high-risk AI systems; NIST AI RMF and OWASP LLM Top 10 both support structured audit requirements for governance and risk management. PromptHalo's audit logs are compliance-ready, tamper-evident, and replayable — built specifically for these reporting obligations.
Agentic-Specific Controls for Tool Calls and Multi-Agent Workflows
Standard security controls weren't designed for agents that plan autonomously and hand off work to other agents. These agentic-specific controls address that gap:
- Per-action scope enforcement: Define explicit boundaries on which tools an agent can invoke, what parameters it can pass, and what rate limits apply per task
- Authority decay: Reduce agent permissions progressively as a task completes — a compromised agent cannot accumulate authority over time
- Handoff authorization: Treat every agent-to-agent handoff as a trust boundary requiring its own authorization check; one agent should never inherit or escalate the permissions of another
- Execution sandboxing: Restrict agent access to file systems, shell commands, and external APIs through policy-enforced environments; whitelist permitted tool interactions and rate-limit external calls
PromptHalo's Unsafe Tool Actions Prevention service blocks out-of-scope tool and API calls before they execute, with authority enforced externally so agents cannot self-grant additional access.
Common Security Mistakes to Avoid
Three patterns account for the majority of preventable failures in production AI systems:
Treating alignment training as a security boundary. RLHF reduces harmful outputs — it does not replace architectural controls. Research by Zou et al. found automated adversarial suffix attacks achieved up to 84% success against GPT-3.5/GPT-4 in tested settings. Alignment is a behavioral tendency, not an isolation mechanism.
Granting agents broad, persistent permissions "for convenience." IBM found that 97% of organizations with AI-related breaches lacked proper AI access controls. Over-permissioned agents with long-lived credentials are among the most common misconfigurations in agentic deployments. Least privilege must be applied at setup and maintained continuously.
Skipping adversarial testing before production. Standard QA does not surface prompt injection paths, indirect injection via RAG outputs, or data exfiltration routes. NIST AI 600-1 specifically recommends adversarial role-playing and red-teaming to identify anomalous failure modes.

Continuous adversarial testing closes this gap. PromptHalo's AI Red Teaming solution probes agents, RAG layers, and tool chains across prompt injection, jailbreak scenarios, poisoning attacks, and data-leakage paths, then feeds those discoveries directly into its runtime detection engine through a shared Threat Library.
Conclusion
Securing AI agents and LLM-powered applications requires layered, purpose-built controls applied across identity, data, runtime behavior, and agentic workflows. None of these are covered by traditional security tools designed for deterministic software. The threat surface is semantic, non-deterministic, and expanding. Your security program needs to keep pace — and static controls won't.
The most defensible posture combines adversarial testing to find exploitable paths before deployment with runtime enforcement that acts on every agent decision after deployment. That closed-loop model is what separates security that compounds over time from security that simply reacts. PromptHalo's Litmus red-teaming engine feeds discovered attack paths directly into the Septa enforcement layer, so every new threat your AI faces in testing makes runtime protection sharper for every agent action that follows.
Frequently Asked Questions
How to secure LLM applications?
Securing LLM applications requires input filtering and prompt injection defenses at the application layer, output monitoring for data leakage, strict identity and API access controls, and continuous behavioral monitoring. OWASP LLM Top 10 is the most practical starting framework for mapping controls to specific vulnerability categories.
How do I secure access for AI agents?
Treat agents as non-human identities with least-privilege, scope-based access. Use short-lived tokens scoped to each task, require explicit authorization for high-privilege actions, and enforce audience restrictions so tokens cannot be reused across pipeline components. Authority should decay as tasks progress, not persist indefinitely.
What is the biggest security risk in agentic AI systems?
Over-permissioned agents combined with prompt injection. A successful injection attack against an agent with broad tool access can trigger real-world actions (data deletion, unauthorized transactions, credential exfiltration) at machine speed, before a human can intervene. OWASP LLM06 (Excessive Agency) defines this as the core blast radius problem.
What compliance frameworks apply to AI agent security?
The three most relevant frameworks are OWASP LLM Top 10 (vulnerability mitigations), NIST AI RMF (governance and risk structure), and the EU AI Act (regulatory obligations). All three require decision-level audit logs capturing what the agent did, why, and under what identity.
What is the difference between prompt injection and jailbreaking?
Prompt injection targets LLM-powered applications by overriding system instructions through crafted inputs or poisoned external content. Jailbreaking targets the model's alignment training to produce content it was trained to refuse. In agentic contexts, prompt injection is more operationally dangerous: it triggers real tool actions with real-world consequences, not just harmful text output.
How do I know if my AI security controls are actually working?
Start with adversarial red-team testing (including indirect prompt injection via RAG outputs and tool results) as your baseline. From there, monitor continuously for anomaly signals: unusual tool call patterns, out-of-scope API access, and unexpected output content. Track catch rate and false-positive metrics against known attack benchmarks to measure whether controls are actually holding.


