
The problem is structural. Security assumptions built for single-agent deployments don't transfer to multi-agent architectures. A compromised agent doesn't just fail in isolation — it can cascade failures across the pipeline, exfiltrate regulated data across domain boundaries, or initiate unauthorized transactions. Traditional firewalls, DLP tools, and input/output filters were designed for a different world: one decision point, one output, one place to inspect.
This article breaks down where multi-agent systems actually break, how trust models need to change, and what regulated enterprises must put in place to satisfy audit and accountability obligations that regulators will not waive.
Key Takeaways
- Multi-agent LLM systems expose three attack surfaces single-agent guardrails cannot address: inter-agent handoffs, RAG retrieval channels, and shared context stores.
- Implicit peer trust between agents is the most exploited architectural weakness in production deployments.
- Regulated industries require architectural enforcement for audit, traceability, and access-control obligations — prompt-level defenses don't meet the bar.
- Runtime inline enforcement at every agent action is the one control layer that keeps pace with agentic AI's speed and autonomy.
Why Multi-Agent LLM Systems Create a New Security Paradigm
The Confused-Deputy Problem at Scale
In a single-agent system, there's one decision point, one trust boundary, and one output to validate. Input filters and output scanners work because everything flows through a single chokepoint.
Multi-agent systems collapse that model entirely. When an outer agent acts on a user's behalf and instructs a more privileged inner agent, it inherits and passes authority it may not legitimately hold.
A manipulated outer agent can instruct a more privileged inner agent to perform actions neither the user nor either agent intended. This happens not because the models are misaligned, but because trust inheritance is a structural property of multi-agent frameworks.
Every agent-to-agent handoff, every tool call, and every retrieval event becomes a potential exploitation path. Standard input/output filters only inspect one hop.
Prompt Injection Propagates Across the Chain
Per-hop detection doesn't provide chain-level protection. Research from AgentDojo found that indirect prompt injection attacks against tool-using agents achieved a targeted attack success rate of 47.69% against GPT-4o, rising to 57.55% under adaptive attack conditions. Intermediate agents can reformat malicious instructions into more coherent, harder-to-detect forms downstream — meaning injection threats don't just survive across hops, they can amplify.

Emergent Behavior as a Compliance Risk
When multiple agents collaborate, the system can produce outputs no single agent was individually programmed to generate. A 2025 research paper confirmed that systems of interacting AI agents introduce security challenges beyond existing cybersecurity and AI safety frameworks.
Pre-deployment testing can't capture this. Emergent behaviors appear under conditions that are difficult to replicate in staging:
- Real-world load across production data volumes
- Agent combinations that were never tested together
- Interaction patterns that only emerge at scale
For financial services firms, an undetected agent compromise isn't just a technical incident. It triggers audit obligations, potential regulatory reporting, and accountability questions that static pre-deployment testing was never designed to answer. Runtime monitoring needs to operate at every inference, tool call, and agent handoff — not as a post-incident capability, but as the enforcement layer.
The Attack Surfaces Unique to Multi-LLM Architectures
Three attack surfaces distinguish multi-agent systems from single-agent deployments. Each requires a dedicated control layer.
Inter-Agent Handoffs and Privilege Escalation
Agents that operate under implicit peer trust share a single credential fabric. Compromising one agent's identity grants access to every agent it can reach. In hierarchical fintech workflows — payment authorization chains, compliance document routing — this creates lateral movement risk that mirrors traditional network compromise patterns. The difference: the attacker's entry point is a language model instruction, not a stolen password.
Role-swapping attacks compound this. When role assertions are self-declared rather than cryptographically bound, an attacker can instruct an agent to assume a higher-privileged role. Per-edge zero-trust with cryptographic workload identity is the minimum defensible posture for agents crossing organizational or domain boundaries.
The NIST NCCoE published a February 2026 concept paper on standards-based approaches to AI agent identity and authorization. That it remains concept-stage illustrates how far the standards gap still extends.
RAG Retrieval Poisoning and Tool Call Exploitation
Retrieval poisoning is indirect prompt injection through the data layer. Research on PoisonedRAG found that injecting just 5 malicious texts into a knowledge base containing millions of documents achieved a 90% attack success rate. The attacker doesn't need access to the user input or the model — only the retrieval source.
Tool call exploitation carries comparable risk. ToolEmu tested 36 high-stakes tools and found that even the safest LM agent failed 23.9% of the time. Agents with broad tool permissions can be manipulated into calling APIs, writing to databases, or initiating financial transactions that exceed their intended authority.
Key controls required at the infrastructure layer:
- Enforce tool whitelisting externally — prompt-level restrictions the model can override don't count
- Evaluate every tool call against the agent's authorized permissions before it executes
- Prevent privilege self-escalation by binding authority to the original grant, not the agent's current context
PromptHalo enforces this inline on every tool call, blocking out-of-scope API calls and dangerous commands before they execute, at the infrastructure layer rather than relying on the model to police itself.
Shared Context and Cross-Domain Data Leakage
Aggregating context from agents operating at different data classification levels into a unified session store creates structural cross-contamination risk. Regulated data tagged for one domain can leak into agents with no authorization to process it — gradually, across multi-step interactions, in ways that no single transaction makes obvious.
A four-tier classification approach — public, internal, confidential, regulated — provides the necessary granularity. The governing rule it implies:
- Restrict orchestrator agents to metadata only — they should never hold full regulated content
- Limit cross-domain communication to redacted summaries, not raw classified data
- Validate classification handling at every agent boundary before any information transfers
Inter-Agent Trust Models: From Implicit Trust to Zero-Trust
Not all trust models carry the same risk. Here's how the three primary models compare for regulated-industry deployments:
| Trust Model | Security Posture | Audit Capability | Applies To |
|---|---|---|---|
| Implicit peer trust | Weakest — shared credential fabric, no per-hop verification | Minimal — no per-edge event trail | Internal prototypes only |
| Role-based with cryptographic binding | Moderate — roles enforced, but role assertion must be verified | Partial — role assignments logged, not per-action | Low-sensitivity internal workloads |
| Per-edge zero-trust | Strongest — every call independently authenticated and authorized | Full — every edge produces an auditable event | Regulated-industry deployments |
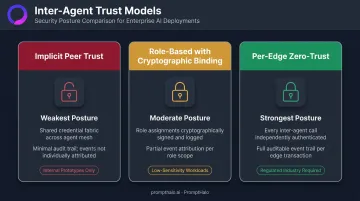
For financial services, per-edge zero-trust is the required baseline. Every agent-to-agent call must be independently authenticated and authorized against a policy that evaluates caller identity, callee identity, requested action, and current context before the call processes.
Authority Decay and Per-Action Budget Enforcement
Authentication alone isn't sufficient. An authenticated agent that continues operating indefinitely accumulates risk with every action it takes.
Authority decay addresses this by shrinking an agent's permissions as it acts. PromptHalo implements this through agent security passports — signed credentials that travel with each request and carry three enforced parameters:
- Time budget: authority expires after a defined window, regardless of action count
- Step budget: each action consumes from a fixed allowance before re-authorization is required
- Risk budget: cumulative risk scoring decays the agent's clearance as stakes increase
The practical effect: a compromised agent's blast radius is bounded. Once its budget is exhausted, it cannot initiate high-stakes operations until a policy-driven re-authorization occurs.
Compliance in Regulated Industries: What Multi-Agent Systems Must Satisfy
The Distributed Accountability Problem
Regulatory frameworks require organizations to demonstrate how decisions were made. GDPR Article 15(1)(h) requires meaningful information about the logic involved in automated decisions. EU AI Act Articles 11-15 impose technical documentation, logging, transparency, and human oversight requirements for high-risk AI systems — and creditworthiness AI systems are explicitly classified as high-risk under Annex III, point 5.
Multi-agent architectures distribute decision-making across components in ways traditional audit mechanisms cannot reconstruct. When five agents contributed to a credit decision, "the model did it" is not an auditable answer.
OCC Bulletin 2026-13 acknowledged this gap directly, stating that generative AI and agentic AI are novel and rapidly evolving and are not within scope of its revised model risk guidance. The regulatory frameworks exist; the agent-specific implementation guidance is still catching up.
SOC 2 Type II Requirements for Multi-Agent Orchestration
SOC 2 Type II compliance creates specific obligations for multi-agent AI deployments:
- CC6.1 — Logical access controls: every agent must operate under a named service account identity, not shared credentials
- CC6.2 — Authorization management: agent permissions must be explicitly registered, scoped, and revocable
- CC9.2 — Vendor risk: LLM API providers must be scoped as subservice organizations with assessed controls
Every inter-agent communication must be logged with sender identity, receiver identity, data classification tag, policy evaluated, and outcome. A log that captures what happened but not why a policy decision was made doesn't satisfy Type II examination requirements.

Cross-Agent Data Governance Under GDPR
SOC 2 addresses access and logging controls. GDPR adds a parallel obligation: clear data lineage and processing transparency at every step.
In multi-agent systems, data is continuously transformed as it passes between agents — summarized, enriched, combined — and lineage breaks down without persistent classification tags tracking those changes.
Two technical requirements follow from this:
- Classification tags must travel with data across agent boundaries, not just originate at the point of ingestion
- Policy enforcement checkpoints between agents must validate classification handling before information transfers occur
PromptHalo's audit logs address this directly, capturing every decision with the acting agent identity, session context, and timestamp in an append-only, tamper-evident trail. Compliance teams can answer regulatory questions through a structured query rather than a forensic reconstruction of what each agent processed and when.
Runtime Enforcement and Tamper-Evident Audit Trails
Why Detection-Only Fails in Regulated Environments
Detecting a prompt injection or unauthorized tool call after it executes may satisfy a logging requirement. It does not prevent a financial transaction from being initiated or regulated data from being exfiltrated.
Regulated-industry deployments require inline, real-time enforcement that evaluates each agent action before it executes. The enforcement decision — allow, restrict, challenge, deny, or escalate — must happen within the latency budget of a production agentic workflow.
PromptHalo's Runtime Security layer sits inline on every inference, tool call, and agent-to-agent handoff, making per-action decisions in under 100ms. It deploys in under a day with no model retraining and no code rewrite, operating as an external security layer that monitors input and output streams without touching the underlying model.
What a Defensible Audit Log Must Capture
A minimum-viable inter-agent audit log for regulatory purposes must include:
- Agent identities — initiating and receiving agent, each with a named service account
- Timestamp and session ID — precise, immutable event sequencing
- Data classification tag on the payload at the time of transfer
- Policy evaluated — which rule was applied to this specific action
- Policy decision — allow, restrict, deny, escalate, and the reason
- Cryptographic integrity hash — ensuring the log record cannot be altered after the fact
Logs must be immutable. Specific accountability questions — which agents accessed which data over a defined period — must be answerable through a structured query, not manual reconstruction.
PromptHalo generates decision-level, replayable audit logs that are tamper-evident and mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act. When an auditor asks which agents processed a specific customer record last quarter, that's a query, not an investigation.
The Gap Most Enterprises Discover Too Late
Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. For regulated enterprises, inadequate risk controls often surface at the worst possible moment — during an audit, after an incident, or when a regulator asks for the AI decision trail.
Deploying agentic AI without a defined trust story means your exposure grows with every agent action — and regulators won't accept "we didn't know" as a control. PromptHalo gives each agent a security passport with a defined trust envelope that shrinks as risk accumulates, making the difference between acceptable AI risk and regulatory liability measurable rather than assumed.
Frequently Asked Questions
What are the characteristics of multi-agent systems?
Multi-agent systems consist of multiple autonomous AI agents with specialized roles, coordinated through handoffs or orchestration layers. Each agent can use tools, access memory, and delegate tasks to other agents, enabling complex multi-step workflows that a single agent cannot execute alone.
What is the difference between single-agent and multi-agent LLM?
A single-agent LLM handles a task end-to-end through one model with one decision point and one trust boundary. A multi-agent LLM system distributes tasks across specialized agents that communicate and hand off work, introducing inter-agent trust boundaries and propagation risks that single-agent guardrails cannot address.
What is specification and verification of multi-agent systems?
Specification defines the intended behavior, permissions, data access rules, and trust contracts for each agent and each inter-agent communication edge. Verification tests whether the deployed system conforms to those specifications under real-world and adversarial conditions, including continuous monitoring for behavioral drift.
What are the main security risks in multi-LLM agent systems?
Multi-LLM agent systems face three compounding risks: prompt injection propagating across agent chains, privilege escalation through implicit inter-agent trust, and regulated data leakage across domain boundaries via shared context or RAG retrieval channels.
How do prompt injection attacks spread across multi-agent systems?
Injections enter through user inputs, external API responses, or poisoned retrieval documents. Intermediate trusted agents can reformat malicious instructions in ways that make them more effective downstream, meaning per-hop filtering alone does not provide chain-level protection.
What compliance frameworks apply to multi-agent AI in regulated industries?
The primary frameworks are:
- OWASP LLM Top 10 (2025) — adversarial attack coverage for LLM deployments
- NIST AI RMF — risk management across the AI lifecycle
- SOC 2 (CC6.1, CC6.2, CC9.2) — access and vendor trust controls
- GDPR Articles 5, 15, 22, 30 — data lineage and processing transparency
- EU AI Act Articles 11–15 — high-risk AI system documentation requirements
Most frameworks require decision-level audit trails and documented data governance controls.


