
Introduction
Picture this: an enterprise AI agent autonomously processes a support ticket. Embedded in a customer email is a hidden instruction — invisible to any human reviewer — that redirects the agent to transfer sensitive data to an external endpoint. The transfer completes before any analyst sees the original message.
This isn't a hypothetical edge case. It's a realistic consequence of deploying agents that act autonomously at machine speed: authenticating with credentials, calling external tools, handing off tasks to other agents, and accessing sensitive data stores without human approval at each step.
The security problem here is different in kind from traditional application security. Existing tools weren't built for this attack surface:
- Firewalls don't read prompt semantics
- DLP tools don't catch data leakage through model responses
- Code scanners can't assess whether an agent's reasoning was manipulated by adversarial content in a retrieved document
And enterprises are deploying agents faster than security frameworks can follow. Gartner predicts 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025.
This guide covers the full stack of enterprise AI agent security: threat landscape, identity and trust controls, runtime enforcement, multi-agent governance, compliance mapping, and maturity measurement.
Key Takeaways
- AI agents introduce attack vectors — prompt injection, memory poisoning, retrieval poisoning, and unauthorized tool calls — that legacy security controls miss entirely
- An effective framework covers five pillars: agent discovery, least-privilege access, behavioral monitoring, runtime enforcement, and compliance auditability
- Runtime enforcement — blocking threats before execution, not after — is the critical missing layer in most enterprise AI security programs
- Regulatory frameworks including OWASP LLM Top 10, NIST AI RMF, and the EU AI Act now mandate demonstrable AI security controls
- Only 13% of organizations believe they have adequate AI agent governance in place today
Why AI Agents Demand a Dedicated Security Framework
Traditional applications have predictable input-output relationships. AI agents don't. Small changes in input can produce dramatically different outputs, and agents act at machine speed — meaning a single compromised agent can execute malicious instructions before any human analyst has a chance to intervene.
Those properties — speed, autonomy, and semantic unpredictability — define a threat surface that conventional security tools weren't built to handle.
Unique Vulnerabilities in the Agentic Attack Surface
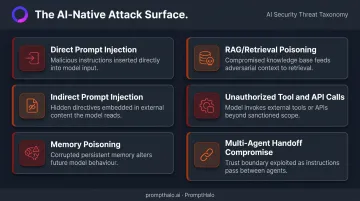
The primary AI-native threat vectors are distinct from anything in traditional application security:
- Direct prompt injection — malicious instructions embedded in user input that redirect agent behavior
- Indirect prompt injection — hidden instructions inside documents, emails, or web pages the agent retrieves; any external data source the agent can read becomes part of the attack surface
- Memory poisoning — adversarial content injected into an agent's persistent memory, corrupting future behavior across sessions
- Retrieval/RAG poisoning — malicious texts inserted into a knowledge base that induce attacker-chosen responses when retrieved
- Unauthorized tool and API calls — agents invoking capabilities outside their intended scope, as defined under OWASP LLM06:2025 Excessive Agency
- Multi-agent handoff compromise — a single compromised agent propagating malicious instructions downstream, with each handoff potentially inheriting the prior agent's permissions
Privilege escalation compounds all of these. Agents are typically provisioned with broad IAM roles at deployment and rarely reviewed — and when an agent is deprecated without deprovisioning, its credentials persist.
When agents communicate across boundaries using token-based transactions, inherited permissions can carry excessive access with minimal logging context. As NIST's NCCoE concept paper on AI agent identity explicitly asks: how do you establish least privilege for an agent whose required actions may not be fully predictable at deployment?
The Gap Traditional Security Tools Cannot Close
The threats above share a common property: they operate at the semantic layer. Standard security scanners cannot interpret the meaning of prompts or assess AI-generated outputs for manipulation — so they miss data leakage through model responses, jailbreaks, and agent reasoning altered by adversarial inputs embedded in retrieved content.
The governance gap is measurable. Gartner reported that only 13% of organizations believe they have the right AI agent governance in place — and predicts that by 2027, 40% of enterprises will demote or decommission autonomous AI agents due to governance gaps identified only after production incidents occur.
Regulatory pressure adds urgency. OWASP LLM Top 10, NIST AI RMF, and the EU AI Act now require demonstrable AI security controls — and enterprises that cannot produce audit evidence face compounding exposure: regulatory penalties on one side, undetected production incidents on the other.
The Five Pillars of an Enterprise AI Agent Security Framework
Enterprise AI agent security is not a single tool or policy. It's a layered discipline built across five interconnected pillars, each depending on the one before it. The sequence of implementation matters.
Pillar 1 — Agent Discovery and Inventory
You cannot govern what you cannot see.
The first pillar requires a continuously updated inventory of every agent in the environment — sanctioned and shadow-deployed — including the IAM roles, OAuth tokens, data stores, tools, and non-human identities each agent uses.
Shadow AI is one of the most exploitable blind spots in enterprise environments. IBM's 2025 Cost of a Data Breach Report found that 63% of organizations lack AI governance policies to manage or prevent shadow AI, and 97% of organizations that reported an AI-related security incident lacked proper AI access controls.
A lightweight agent registration and approval workflow should capture:
- Agent name, owner, and business unit
- Assigned IAM roles and OAuth token scopes
- Data stores and external APIs the agent is permitted to access
- Deployment date, review schedule, and deprecation process
- Classification of agent autonomy level (supervised vs. fully autonomous)

Without this inventory, every other pillar is built on incomplete information.
Pillar 2 — Least-Privilege Access Control
Least privilege for AI agents means each agent operates with the minimum permissions required for its specific task — nothing more.
The gap between what agents are permitted to access at provisioning versus what they actually use at runtime is a persistent privilege escalation risk. Agents provisioned with broad IAM roles "just in case" carry excessive access that attackers can exploit if those agents are compromised.
The primary enforcement mechanisms are:
- Role-based access control (RBAC) scoped to agent function, not team or system defaults
- OAuth and API token scoping constrained to specific endpoints and actions
- Per-action permission budgets that track authority across time and steps, forcing re-authorization when risk thresholds are exceeded
PromptHalo's runtime enforcement implements authority decay: as an agent operates, its authority diminishes over time and steps, preventing elevated privileges from persisting beyond what each task requires.
Pillar 3 — Behavioral Monitoring and Anomaly Detection
Rule-based detection alerts on known-bad patterns. Evasion-focused attacks sidestep it by using legitimately authorized tools for unauthorized purposes, staying within the rules while violating the intent.
Effective behavioral monitoring establishes per-agent baselines from observed runtime activity, not assumed function. What matters isn't just which API an agent called, but whether that action aligns with the agent's authorized purpose. This intent-focused approach catches what rule-based systems miss: an agent with legitimate database read access suddenly querying out-of-scope tables, or a customer-service agent generating content that resembles financial advice.
PromptHalo's behavioral drift detection tracks how agent behavior changes session over session, drawing on per-tenant session and memory state to recognize when outputs are drifting from expected patterns.
Gartner recommends that high-autonomy agent systems use continuous monitoring, enforced guardrails, rapid rollback mechanisms, and circuit breakers — not just static rule sets.
Pillar 4 — Runtime Enforcement (Pre-Execution Controls)
Post-execution analysis is forensics: it documents what went wrong, but it doesn't prevent harm.
Runtime enforcement intercepts agent actions — tool calls, prompt inputs, agent-to-agent handoffs — at the point of execution, validating them against approved workflows and blocking violations before they complete.
Most enterprise AI security programs rely on perimeter controls and post-hoc logging. Neither stops a compromised agent mid-execution. Runtime enforcement does.
Pillar 5 — Compliance Auditability
Compliance at enterprise scale requires automated evidence collection, not manual documentation assembled at audit time.
Each agent action must generate a tamper-proof audit trail capturing:
- Who invoked the agent (passport identity)
- What actions were taken and which systems were accessed
- Which data was touched
- The reasoning behind each decision
- Session and tenant context with a precise timestamp
PromptHalo's append-only, tamper-evident audit logs capture every decision along with its reason, the acting agent's identity, and session context. The result is a replayable evidence trail for debugging, compliance export, and post-incident investigation.
For enterprises managing dozens or hundreds of deployed agents, manual evidence collection at audit time isn't viable. Automated logging at the decision level is the only approach that scales.
Runtime Enforcement: Securing Every Agent Decision Before It Executes
By the time a post-execution alert fires, data may already be exfiltrated or a configuration changed. Runtime enforcement operates at every inference, tool call, and agent-to-agent handoff — making an allow, restrict, challenge, deny, or monitor decision before the action executes.
The latency requirement is strict: enforcement must operate in milliseconds to be viable in production without degrading agent performance.
What Runtime Enforcement Must Cover
Effective runtime enforcement must cover every vector where agentic systems can be manipulated:
- Prompt injection scanning — both direct user input and indirect content retrieved from external sources
- Jailbreak detection — instruction overrides and adversarial techniques designed to push agents outside intended behavior
- RAG/retrieval poisoning detection — poisoned knowledge base content carrying hidden instructions
- Out-of-scope tool and API call blocking — preventing agents from invoking capabilities beyond their assigned task
- Data leakage prevention at egress — inspecting responses inline before they reach the user
- Multi-agent handoff integrity — validating that agent-to-agent transfers don't propagate compromised instructions

This must be model-agnostic and vendor-agnostic — working across any AI application from any provider without touching the underlying model or requiring a code rewrite.
Meeting those requirements at enterprise scale requires detection that's both fast and accurate — which is where ML-based approaches diverge sharply from rule-based ones.
PromptHalo's Septa Enforcement Engine
PromptHalo's Septa enforcement engine makes real-time, inline decisions on every agent action in under 100ms. Its ML-based detection achieves over 95% catch rate at under 5% false positives — compared to roughly 35% catch rate and 15–20% false positives for rule-based approaches. The platform deploys in under a day with no model retraining and no code rewrite, across any AI application from any vendor.
Detection combines Threat Library signatures with classifier-based risk scoring, reducing reliance on brittle rules that sophisticated attacks are specifically designed to evade.
The Closed-Loop Defense Advantage
PromptHalo's closed-loop defense works through a continuous find-then-defend cycle. The AI Red Teaming solution continuously attacks agents, RAG layers, and tool chains the way a real adversary would — identifying exploitable paths before they reach production. Every attack it discovers is encoded into the shared Threat Library and immediately becomes a runtime defense.
Protection compounds over time: each newly discovered attack pattern becomes enforceable at runtime, and the ML detection engine continuously trains on new adversarial findings. That means an enterprise deploying PromptHalo today is measurably better protected six months from now — without any manual tuning.
Compliance, Audit Trails, and Regulatory Alignment
Mapping Regulatory Frameworks to Agent Security Requirements
| Framework | Key Requirements for AI Agents |
|---|---|
| OWASP LLM Top 10 | Documented controls for prompt injection (LLM01), excessive agency (LLM06), and improper output handling (LLM05) |
| NIST AI RMF | Govern, Map, Measure, Manage functions applied to agent context, data access, tools, and risk controls |
| EU AI Act | Lifecycle risk management, automatic event logs for traceability, and cybersecurity measures for high-risk AI systems |
| SOC 2 | Continuous monitoring of system components under CC7.2 Trust Services Criteria |
| HIPAA | Audit controls recording activity in systems containing ePHI; documentation retention for 6 years |
| GDPR | Records of processing activities under Article 30; safeguards for solely automated decisions under Article 22 |
Each of these frameworks carries real enforcement timelines. The EU AI Act entered into force in August 2024, with general application beginning August 2026. High-risk AI system obligations — including automatic event logs for traceability — become enforceable in 2027. Enterprises in regulated industries that haven't built audit infrastructure by then face direct compliance exposure.
Financial Services: Heightened Stakes
For financial services firms, the regulatory pressure is especially intense. The U.S. Treasury's March 2024 report on managing AI-specific cybersecurity risks in financial services identified AI explainability, regulatory fragmentation, and capability gaps as critical concerns. The SEC has already charged investment advisers for misleading AI claims, and the CFPB requires specific, accurate adverse-action reasons when complex algorithms influence credit decisions.
When AI agents touch sensitive transactions, customer PII, or compliance workflows, regulators expect audit trails that can withstand scrutiny — not just internal records. PromptHalo's tamper-evident, decision-level audit logs capture every agent action with the context required for regulatory reporting, mapped directly to OWASP LLM Top 10, NIST AI RMF, and EU AI Act requirements.
Measuring and Maturing Your AI Agent Security Posture
A Four-Stage Maturity Model
Most enterprises today sit somewhere between Observe and Govern. The platforms maturing fastest are building toward enforcement and autonomous response by default.
| Stage | What It Looks Like |
|---|---|
| Observe | Basic logging of agent actions; no behavioral baselines; reactive incident response |
| Govern | Agent inventory established; access policies defined; manual compliance evidence collection |
| Enforce | Runtime pre-execution controls active; automated anomaly detection; CI/CD security gates |
| Autonomous Response | Self-healing controls; continuous red-teaming feeding live defenses; automated compliance reporting |
The CSA released an AI Security Maturity Model in May 2026 as a benchmarking tool for security leaders assessing their current state. The five metrics below map directly to each maturity stage — and tell you how far you have left to go.
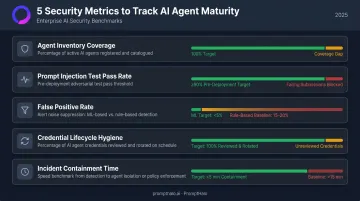
Metrics Security Leaders Should Track
- Agent inventory coverage: What percentage of deployed agents — including shadow AI — are inside your governed inventory? Gaps here are your biggest unknown risk.
- Prompt injection test pass rate: Track red-teaming results across agent workflows before deployment, not after an incident.
- False positive rate: Rule-based approaches typically run 15–20% false positives; ML-based detection targets under 5%. High rates signal your tooling isn't built for AI-native threats.
- Credential lifecycle hygiene: Percentage of agents with reviewed, scoped, and rotated credentials — a leading indicator of privilege sprawl.
- Incident containment time: How quickly runtime enforcement isolates a compromised agent once a threat is confirmed.
Each metric translates to a concrete ROI story:
- Faster release cycles when security gates are embedded in CI/CD
- Avoided compliance penalties through automated audit trail generation
- Preserved stakeholder trust in regulated markets where AI incidents carry reputational weight
Frequently Asked Questions
What are the most critical threats an AI agent security framework must address?
The primary attack vectors include:
- Prompt injection (direct and indirect)
- Memory poisoning
- Unauthorized tool and API calls
- Retrieval/RAG poisoning
- Privilege escalation through over-scoped credentials
These operate at machine speed, making pre-execution controls essential. Post-execution analysis arrives after the harm is done.
How does an AI agent security framework differ from traditional application security?
Traditional tools evaluate structured, deterministic systems and cannot interpret the semantic meaning of prompts, assess AI-generated outputs for manipulation, or detect agent behavior altered by adversarial inputs in retrieved content. AI agent security requires purpose-built controls for probabilistic, autonomous systems.
What does least privilege mean for AI agents, and how is it enforced?
Least privilege for agents means scoping each agent's permissions to only the specific tools, data stores, and APIs required for its assigned task. Enforcement relies on RBAC, token scoping, and per-action permission budgets, with authority decay mechanisms that prevent permissions from persisting indefinitely.
How do you implement runtime enforcement for AI agents without retraining models or rewriting code?
Runtime enforcement operates as an inline layer between the agent and its tools, intercepting and evaluating every action before execution without modifying the underlying model. Platforms like PromptHalo deploy this capability in under a day, across any AI application from any vendor, with no code rewrite required.
What compliance frameworks apply to enterprise AI agent deployments?
OWASP LLM Top 10, NIST AI RMF, EU AI Act (for high-risk AI applications), SOC 2, HIPAA, and GDPR each impose requirements that AI agents handling sensitive data must satisfy. Automated audit trail generation, not manual documentation, is the only realistic path to compliance at enterprise scale.
How long does it take to deploy an AI agent security framework at enterprise scale?
Runtime enforcement can be deployed in under a day without model retraining, giving you immediate coverage while the broader framework matures. The full build is iterative: agent inventory first, then access controls, then enforcement — typically phased over weeks, not months.


