
Why AI Hallucination Mitigation Can't Be Generic in Healthcare and Finance
Consider two scenarios. In the first, an AI writing assistant confidently invents a statistic in a marketing email. Someone catches it, the draft gets corrected, and the cost is a few minutes of a copywriter's time. In the second, an AI clinical documentation tool inserts a medication allergy that was never mentioned during a patient encounter. That entry persists into the EHR, propagates into a care plan, and a pharmacist fills a prescription the patient should never have received.
Same failure mode. Completely different consequences.
NIST AI 600-1 defines AI hallucination as "confabulation": outputs that are statistically plausible but factually incorrect, delivered with the same confidence as accurate information. In most enterprise contexts, that's a quality problem. In healthcare and financial services, it's a structural incompatibility with the regulations, safety standards, and accountability frameworks those industries operate under.
The challenge runs deeper than catching bad outputs. Existing security infrastructure — DLP tools, firewalls, code scanners — wasn't designed to evaluate AI inference, which means security and compliance teams are now accountable for outputs they didn't produce and can't easily audit.
Key Takeaways:
- In regulated workflows, hallucinations propagate downstream before detection — these systems assume data integrity
- Healthcare and finance face three distinct risk vectors: knowledge errors, retrieval poisoning, and agentic action on fabricated premises
- Effective defense requires layered controls across input, retrieval, runtime, and human review — no single fix is sufficient
- HIPAA, FDA SaMD guidance, and model risk management rules create direct accountability for AI output integrity
- Runtime enforcement — evaluating outputs before they execute — is the critical gap most organizations haven't closed
Why Regulated Industries Face Amplified Hallucination Risk
In general-purpose AI settings, hallucinations are inconvenient. In regulated environments, they cascade. Clinical workflows, compliance filings, and financial transactions are built on an assumption of data integrity — when AI outputs enter these pipelines, they're treated as reliable inputs to downstream decisions, not as probabilistic guesses requiring verification.
Three hallucination risk vectors hit regulated environments hardest:
Fabricated domain knowledge — invented drug interactions, hallucinated regulatory citations, false clinical guideline references. These errors are especially dangerous because they mimic the correct vocabulary and reasoning structures of the domain, making them hard to catch without expert review.
Retrieval poisoning — when AI systems pull from large, unverified external corpora, adversarial actors can corrupt the knowledge base itself. Research published at USENIX Security demonstrated 90% attack success rates by injecting just five malicious texts into a large retrieval corpus.
Agentic hallucinations — when an autonomous AI agent acts on a fabricated premise: calling an API, initiating a transaction, documenting a patient encounter. The hallucination is no longer a text error; it's an operational event.

Security and compliance teams in these sectors now own AI outputs they didn't generate, cannot easily audit, and for which conventional security tooling provides no meaningful coverage.
AI Hallucination Risks in Healthcare Settings
The Medical Hallucination Taxonomy
Healthcare AI faces a specific set of hallucination failure modes, each capable of causing direct clinical harm:
- Fabricated drug dosages or contraindicated interaction warnings
- Incorrect differential diagnoses in AI-assisted clinical decision support
- Hallucinated lab values appearing in EHR summaries
- Citations to clinical guidelines that don't exist
What makes these harder to detect than ordinary errors is their clinical coherence. A fabricated dosage recommendation doesn't look wrong — it looks like a reasonable clinical judgment rendered in precise medical language.
A 2025 medRxiv preprint surveying 75 healthcare professionals found that 37 reported encountering medical hallucinations in their workflows, spanning literature review, data analysis, patient diagnostics, treatment recommendations, and EHR summaries. Multi-model clinical decision support testing has found hallucination rates ranging from 50% to 82% when models were presented with fabricated clinical details.
What an AI Hallucination Looks Like in Clinical Practice
Consider what this looks like in practice: an ambient AI documentation tool records a physician encounter, then inserts a medication that was never mentioned into the clinical note. The note gets reviewed quickly, signed, and enters the EHR — and that medication now appears in the patient's active list, shaping the next clinician's treatment decisions.
AP reported that OpenAI's Whisper transcription tool hallucinated content in 8 out of every 10 tested audio transcriptions in one study, with another developer finding hallucinations in nearly all of 26,000 transcripts reviewed — and the tool was being used in medical settings.
Those numbers become more dangerous when combined with automation bias. A NEJM AI study of 44 physicians found that erroneous LLM suggestions reduced mean diagnostic accuracy from 84.9% to 73.3%, with top-choice accuracy falling from 90.5% to 76.1%. Clinicians who trust AI-generated documentation scrutinize it less — meaning hallucinations in high-trust workflows are more likely to spread undetected.

The Downstream Consequences for Healthcare Organizations
The liability exposure from a hallucinated clinical AI output has no settled legal precedent. When an AI-influenced decision results in patient harm, accountability is distributed across the care provider, the institution, and the AI vendor — and courts have yet to establish how that distribution works.
The regulatory layer adds another dimension:
- Healthcare AI meeting the FDA's definition of Software as a Medical Device (SaMD) requires premarket review. Hallucinations affecting clinical outputs may indicate the AI is operating outside validated parameters.
- FDA's draft guidance on AI-enabled device software functions requires total product lifecycle controls and postmarket performance monitoring — meaning organizations can't treat a deployed model as a one-time validation event.
- Under 21 CFR Part 803, software anomalies meeting MDR criteria must be reported. A hallucination that reaches a clinical decision could qualify.
AI Hallucination Risks in Financial Services
The Finance-Specific Risk Profile
Financial services AI hallucinations manifest differently than clinical ones, but the structural problem is the same: errors enter trusted workflows before anyone checks them. The primary exposures are:
- Regulatory compliance failures from hallucinated citations in AML reports, credit risk assessments, or regulatory filings
- Erroneous financial decisions driven by fabricated performance data or invented safe harbor provisions
- Customer-facing misinformation in AI-assisted advisory or support contexts
The CFPB has explicitly warned that banking chatbots can provide inaccurate information about consumer financial products, creating material consumer harm. The SEC charged two investment advisers in 2024 for false and misleading AI-use statements — underscoring that regulators are paying close attention to what AI actually produces, not just what organizations claim about it.
What an AI Hallucination Looks Like in Financial Workflows
An AI model assisting with financial advisory generates a recommendation citing a fund's 10-year annualized return. The figure doesn't match actual historical performance. The advisor reviews for logic and presentation — not to independently verify every data point — and forwards the recommendation to the client.
These errors are particularly dangerous because they exploit the domain knowledge gap. Compliance reviewers assessing AI-generated regulatory filings are evaluating structure and reasoning — they're rarely equipped to independently verify every regulatory citation the model produces.
When AI Agents Execute Trades and Transfers
That knowledge gap compounds sharply once AI moves from generating documents to taking action.
When AI agents hold tool-calling authority — executing trades, initiating wire transfers, querying live market data — a hallucination stops being a document problem. It becomes an operational event.
Multi-agent architectures make this substantially worse. One agent's hallucinated output becomes the next agent's ground truth. In a handoff chain, errors skip validation between agents — they arrive at the next step already treated as verified inputs, accumulating false confidence at each step.
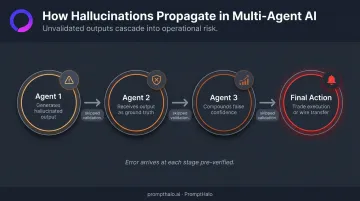
The Financial Stability Board's 2026 sound practices for responsible AI adoption and global regulators' calls for tighter agentic AI controls reflect this concern directly — regulators now classify autonomous AI action as a systemic risk category, not an operational edge case.
Key regulatory frameworks creating accountability:
| Framework | Relevance to AI Hallucination |
|---|---|
| SR 26-2 (replaces SR 11-7) | Model risk management for AI in financial decision-making |
| EU AI Act (Articles 12–15) | Logging, transparency, human oversight, accuracy requirements |
| SEC AI-in-advisory guidance | Explainability and auditability in AI-assisted financial decisions |
| CFPB chatbot guidance | Accuracy obligations for AI-generated consumer financial information |
Enterprise Safeguards: Building a Layered Defense
No single control eliminates hallucination risk in regulated environments. The enterprise posture must address the model input layer, the retrieval and context layer, the output layer, and the runtime enforcement layer independently — because each failure mode requires a different intervention.
Input-Layer Controls: Grounding and Prompt Architecture
Retrieval-augmented generation (RAG) is the primary input-layer safeguard. By constraining AI outputs to verified, organization-controlled source documents — clinical protocols, regulatory filings, approved product documentation — rather than the model's broad training data, organizations significantly reduce the surface area for factually incorrect outputs.
RAG quality, however, is only as good as the retrieval corpus. Research shows RAG can reduce hallucination rates by over 40% versus standard baselines. But PoisonedRAG research demonstrated 90% attack success with just five malicious texts injected into a large corpus. Grounding doesn't eliminate retrieval poisoning risk — it just changes where the attack surface lives.
Structured prompt design is a complementary control: chain-of-thought prompting, explicit source citation requirements, and output format constraints narrow the model's generation space. These controls are input-side only — they don't protect against agentic hallucinations that occur mid-workflow after the prompt has already been processed.
Runtime Enforcement: Catching What Input Controls Miss
Runtime guardrails are the critical second layer — controls that evaluate AI outputs at the moment of generation, before they execute tool calls, enter records, reach users, or propagate downstream.
This is the gap that most enterprise AI security stacks currently leave open. Firewalls and DLP tools evaluate network traffic and data movement. They have no visibility into what an AI model just generated, whether that output is factually grounded, or whether it's about to instruct an agent to call an unauthorized API.
PromptHalo's runtime security layer is purpose-built for this problem. Sitting inline on every inference, tool call, and agent-to-agent handoff, it makes per-action enforcement decisions in under 100ms:
- Allow, restrict, challenge, deny, or monitor each action before execution
- Enforce scope limits and detect out-of-bounds outputs at the agent level
- Block retrieval poisoning attempts before they propagate downstream
For multi-agent architectures, PromptHalo issues agent security passports that travel with each request, with authority decay built in. As an agent operates across handoffs, its authority budget decays over time and steps, requiring re-authorization when thresholds are exceeded. This prevents one agent's hallucinated output from automatically becoming another agent's trusted ground truth.
The detection combines Threat Library signatures with classifier-based risk scoring, achieving a catch rate above 95% at under 5% false positives — critical in healthcare and finance where alert fatigue is a real operational cost. The platform deploys in under a day with no model retraining and no code rewrite, across any AI application from any vendor.
Human-in-the-Loop and Red Teaming
For high-stakes decisions — clinical documentation, regulatory submissions, credit decisions — AI outputs must pass through structured human verification before downstream action. The design of these approval gates matters enormously.
Automation bias research shows that a human reviewer who trusts AI outputs will scrutinize them less. Human oversight not specifically designed to catch AI errors becomes performative over time — a compliance theater exercise rather than a genuine check.
Human oversight catches errors after generation. Red teaming catches the conditions that produce them before deployment. Systematically probing AI systems under realistic operational conditions — retrieval poisoning attempts, prompt injection, edge-case domain queries — identifies exploitable failure modes before they appear in production. NIST AI 600-1 explicitly recommends structured red teaming for AI systems as a risk management requirement.
PromptHalo's red teaming capability runs adversarial task chains across multi-step, multi-agent workflows, probing for prompt injection, jailbreak, poisoning, and data-leakage vulnerabilities. Critically, discoveries are encoded into a shared Threat Library, so newly identified attack patterns become runtime defenses immediately — no release cycle required.
Aligning AI Controls with Regulatory Compliance Requirements
The hallucination control stack maps directly onto the compliance frameworks governing regulated AI deployment:
- HIPAA (45 CFR 164.312): Audit controls require mechanisms to record and examine system activity; integrity controls require protection from improper alteration of ePHI. AI systems processing clinical data must meet both.
- FDA SaMD guidance: The 2025 draft guidance on AI-enabled device software functions requires total product lifecycle controls and postmarket performance monitoring — including documentation of software anomalies.
- NIST AI RMF: Govern, Map, Measure, and Manage functions require validation, monitoring, transparency, and risk management throughout the AI lifecycle.
- EU AI Act (Articles 12–15): High-risk AI systems must maintain logs, provide transparency, enable human oversight, and demonstrate accuracy and robustness. Financial services and medical device AI both fall within the high-risk classification.
- SR 11-7 / Model Risk Management Guidance: Existing model risk management guidance covers traditional model validation; notably, generative and agentic AI fall outside that framework's scope, meaning firms deploying these systems need separate AI governance structures.
The audit trail is the foundational compliance control across all of these frameworks. Regulators in both sectors expect organizations to demonstrate not just that AI outputs were reviewed, but that the AI system's decision logic was logged, timestamped, and retrievable for post-incident investigation.
That's where purpose-built audit infrastructure matters. PromptHalo produces compliance-ready, decision-level audit logs that are append-only and tamper-evident. Every decision is captured with its reason, the acting agent or passport identity, the session and tenant context, and a timestamp — giving compliance teams a replayable evidence trail for debugging, regulatory export, and post-incident investigation.
Technical controls address the infrastructure side. Governance closes the organizational gap. That means establishing:
- Defined ownership of AI risk at the organizational level
- Documented validation procedures for models entering production
- Change management processes that account for model updates
- Incident response playbooks that specifically address AI hallucinations reaching patients or financial counterparties before detection
Frequently Asked Questions
What is an example of AI hallucination in healthcare?
A clinical documentation tool may insert a medication never mentioned during a patient encounter; a decision support system may fabricate a drug dosage referencing a nonexistent guideline. Because these errors use clinically valid terminology, clinicians often can't catch them without independent verification.
What is an AI governance platform for healthcare?
AI governance platforms manage and enforce responsible AI behavior across the full AI lifecycle in healthcare — covering risk classification, output validation, audit trail generation, and alignment with FDA SaMD guidance and HIPAA. Unlike general deployment tools, they address regulatory accountability directly: who owns AI risk, how outputs are validated, and what gets logged when something fails.
How can AI be regulated in healthcare?
The primary pathways are FDA oversight of AI qualifying as Software as a Medical Device, HIPAA requirements for AI systems processing protected health information, and the NIST AI RMF as the governance standard for identifying and managing AI risk. Each AI use case requires its own pathway assessment and a matching validation and monitoring program.
What are examples of AI hallucination risks in financial services?
Three scenarios illustrate the range of exposure: fabricated regulatory citations in compliance filings (submission accuracy risk); hallucinated historical performance data in AI-generated recommendations (fiduciary risk); and agentic AI executing transactions on internally fabricated data points (operational event). Each represents a distinct regulatory failure mode that review processes rarely catch without targeted controls.
What is retrieval poisoning in AI systems?
Retrieval poisoning is the corruption or manipulation of the external knowledge sources that RAG systems pull from — such that the AI retrieves and presents fabricated or adversarially altered content as authoritative. In regulated environments, this is a high-priority attack surface: the AI's output appears well-sourced and credible even when the underlying knowledge base has been compromised.
How do runtime guardrails differ from prompt engineering for hallucination control?
Prompt engineering operates at the input layer before generation and can reduce but not eliminate hallucination probability. Runtime guardrails evaluate and enforce controls at the output and action layer — intercepting problematic outputs before they execute, enter records, or propagate downstream. Both are necessary; neither substitutes for the other. Prompt engineering narrows the generation space; runtime enforcement catches what still gets through.


