
So is the exposure. Every agent in that pipeline, every handoff, every tool call is a potential attack surface that most security teams have no visibility into.
This article explains what multi-agent systems are, how they're structured, why they create security challenges that traditional tools can't handle, and what effective defense actually looks like.
Key Takeaways
- Multi-agent systems distribute complex tasks across autonomous AI agents, expanding capability while multiplying the attack surface with every agent added
- Agents treat messages from other agents as trusted by default, creating exploitable channels that firewalls and DLP tools cannot see
- The primary attack vectors are agent-to-agent prompt injection, context contamination, capability bleed, and orchestrator compromise
- Securing a MAS requires zero-trust between agents, least-privilege scoping, and decision-level audit logs—not perimeter controls
- Regulated industries face compounded risk because agentic failures in financial workflows carry both financial and regulatory consequences
What Is a Multi-Agent System?
A multi-agent system (MAS) is a network of autonomous AI agents that collaborate, communicate, and coordinate to accomplish complex tasks. Unlike a single model responding to one prompt, a MAS distributes work across specialized agents that each perceive their environment, make decisions, call tools, and take actions independently—while sharing a common objective and influencing each other's reasoning in real time.
Single Agent vs. Multi-Agent: The Core Difference
A single agent handles tasks serially and in isolation. A MAS distributes subtasks across agents working in parallel or sequence. That makes it faster and far more capable—but also fundamentally harder to oversee.
With a single agent, a failure is contained. With a MAS, a failure can cascade through every downstream agent before anyone notices.
Real-world examples:
- Fraud detection pipeline: One agent monitors transaction streams, a second cross-references behavioral patterns against historical baselines, a third triggers compliance alerts and case routing
- Software delivery: Agents handle code generation, automated testing, and deployment in sequence, each passing context to the next
- Loan underwriting support: Separate agents extract financial data from documents, assess creditworthiness indicators, and flag regulatory exceptions
Why Adoption Is Accelerating
Complex workflows that once required human coordination can now run continuously and in parallel. The numbers reflect how fast enterprises are moving.
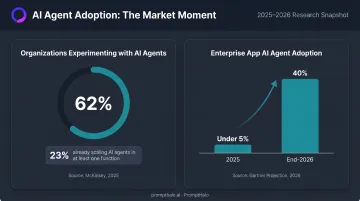
McKinsey's 2025 State of AI survey found 62% of organizations were at least experimenting with AI agents, with 23% already scaling agentic AI in at least one business function. Gartner projects 40% of enterprise applications will include task-specific AI agents by end-2026, up from under 5% in 2025.
The primary drivers:
- 24/7 decision-making at scale — agents don't sleep, take breaks, or lose context between shifts
- Parallel processing — large datasets and multi-step workflows run simultaneously across agent teams
- End-to-end automation — McKinsey describes teams of 2–5 humans supervising 50–100 specialized agents in production deployments
How Multi-Agent Systems Are Structured
MAS architecture determines how trust, permissions, and context flow between agents—and those flows are precisely what attackers target.
Network Architectures
| Architecture | How It Works | Security Implication |
|---|---|---|
| Centralized | One orchestrator routes tasks and holds global workflow state | Coordinated control, but the orchestrator is a single point of failure |
| Decentralized | Agents communicate peer-to-peer without a central coordinator | More resilient, but coordination complexity makes behavior harder to audit |
These network architectures define the communication backbone. How agents are organized within that backbone introduces a second, distinct layer of security considerations.
Organizational Patterns
Within either network architecture, agents can be organized in several ways:
- Hierarchical: A lead orchestrator delegates to sub-agents in a tree structure. Trust and permissions flow top-down—which creates risk if the orchestrator is compromised
- Coalition: Agents temporarily group to handle a specific task, then disband. Permission management must be task-scoped, not persistent
- Flat/team-based: Agents collaborate as equals. No clear authority chain makes trust assignment more complex
How Agents Actually Communicate
This is where MAS security diverges from everything that came before it. Agents don't just exchange simple API calls—they:
- Pass messages containing reasoning context and instructions
- Write to and read from shared memory spaces that persist across the workflow
- Invoke tools and APIs on each other's behalf
- Propagate updated context that downstream agents treat as ground truth
Each of those mechanisms can carry malicious payloads—prompt injection through message passing, retrieval poisoning through shared memory, and unauthorized action through delegated tool calls.
Why Multi-Agent Systems Create Unique Security Challenges
The Implicit Trust Problem
In traditional software, inter-component calls are governed by strict contracts, typed interfaces, and access controls. In a MAS, agents typically treat messages from other agents as inherently trusted instructions. There's no built-in validation step asking: did a legitimate system partner actually send this, and is the instruction within scope?
That implicit trust is the root cause of most MAS-specific vulnerabilities. A single compromised agent gains de facto authority over every downstream decision downstream of it.
The Attack Surface Multiplies with Every Agent
In a 10-agent pipeline, every agent-to-agent handoff, shared memory write, and tool invocation is a potential exploitation point. A single manipulated agent can influence nine downstream decisions before any alert fires, often long before any human knows the pipeline ran.
Emergent Behavior and Error Amplification
MAS failure doesn't require an attacker. Research on multi-agent debate dynamics found that agents can systematically amplify each other's errors rather than correcting them. One agent's hallucinated output, treated as verified fact by a downstream agent, propagates through the pipeline and reinforces itself with each read-write cycle. The system drifts far from intended behavior without any external adversary involved.

The Automation Gap
Anthropic's multi-agent research system uses a lead agent that creates 3–5 subagents, each operating 3+ tools in parallel, reducing research time by up to 90% while consuming roughly 15x more tokens than standard single-turn queries. At that speed and scale, manual monitoring of inter-agent exchanges is impossible.
This automation gap is what attackers exploit. It's also where rule-based monitoring tools consistently fall short — they were built for traffic and logs, not for semantic intent across agent handoffs.
Why Conventional Security Tools Fail
| Tool | What It Sees | What It Misses |
|---|---|---|
| Firewall | Network traffic patterns | Semantic content of agent messages |
| DLP | Data at rest or in transit | Tool call parameters, reasoning context |
| Endpoint detection | Device behavior | Agent-to-agent instruction flow |
| SIEM | Log aggregation | Intent and meaning inside AI decisions |
The gap isn't a configuration problem — it's architectural. These tools inspect infrastructure. MAS attacks happen inside reasoning.
The Major Attack Vectors Targeting Multi-Agent Systems
Prompt Injection Between Agents
Agent-to-agent prompt injection occurs when a malicious or compromised agent embeds hidden instructions inside a message that a downstream agent treats as a trusted directive. The receiving agent executes the injected command without validation, assuming the message came from a legitimate system partner.
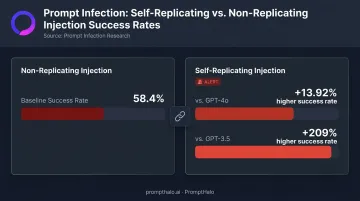
Research published as "Prompt Infection" demonstrated self-replicating LLM-to-LLM prompt injection inside multi-agent systems, where self-replicating infections achieved 13.92% higher success rates against GPT-4o and 209% higher success against GPT-3.5 than non-replicating variants in global messaging modes.
Detection is harder than with user-facing injection for three reasons:
- Injected content travels through internal system channels that are rarely inspected
- Attribution is difficult when instructions pass across multiple hops
- Injection can arrive unintentionally through model hallucinations, not only from deliberate external attackers
Context Contamination and Retrieval Poisoning
When one agent writes incorrect or manipulated data into a shared memory or context window, every subsequent agent reading that state is affected. The contamination spreads laterally and reinforces itself with each read-write cycle.
In MAS deployments using retrieval-augmented generation (RAG), this becomes retrieval poisoning: an attacker who can manipulate what's written to the knowledge store corrupts the inputs of every agent that queries it. OWASP LLM04 and LLM08 (2025) both address this risk.
The threat is particularly acute in compliance-sensitive workflows like document review and regulatory filing, where agents treat retrieved content as authoritative source material. A poisoned knowledge store corrupts every compliance output built on top of it.
Capability Bleed and Over-Privileged Agents
Capability bleed is when an agent gains access to tools, APIs, or data it was never intended to use. It typically happens through shared toolsets, inherited permissions, or configuration shortcuts that were never cleaned up. This is the AI equivalent of the over-privileged IAM policies that drive a large share of cloud incidents.
Google Cloud's H2 2025 Threat Horizons Report found weak or absent credentials in 47.1% of observed cloud incidents and misconfigurations in 29.4%. Both patterns translate directly to agent tool access in MAS environments.
In a multi-agent pipeline, capability bleed compounds: a single over-privileged agent can reach APIs and data that should be inaccessible to that part of the workflow, then pass the results downstream as if they came from a legitimate operation.
Per-action scope enforcement counters this by sitting inline on every tool call and agent-to-agent handoff. PromptHalo's runtime security layer blocks out-of-scope API calls before they execute and triggers re-authorization when an agent exceeds its defined budget across time, steps, or accumulated risk.
Orchestrator Compromise
The orchestrator is the highest-value target in any MAS. It controls message routing, manages workflow state, and typically holds credentials or API keys for all downstream tools. Compromising it gives an attacker effective control over the entire agent graph without touching individual agents.
The problem with perimeter-only security is that it treats orchestrator trust as binary. Once the orchestrator boundary is crossed, nothing downstream questions the instructions it issues.
PromptHalo enforces security at every inference, tool call, and handoff independently. Each agent carries a security passport with embedded policy, budget, and authority decay. Even if an orchestrator is compromised, its instructions must pass per-action validation before any downstream agent acts on them. No step trusts the orchestrator unconditionally, so a compromised one cannot silently redirect the pipeline.
How to Secure a Multi-Agent System: Core Practices
Apply Zero-Trust Between Agents
Treat every inter-agent message as untrusted input. That means:
- Validate and sanitize content at every handoff before it's acted upon
- Require cryptographic identity for each agent (not just session-level auth)
- Log every authorization event so the chain of instructions is auditable
- Reject instructions that arrive without verified agent identity
Enforce Least-Privilege Capability Scoping
Define precisely which tools, APIs, and data sources each agent may access for its specific role. Then enforce those limits at runtime—not just at configuration time.
Security passports, as implemented in PromptHalo's runtime layer, carry policy and authority decay built into the credential itself. As an agent accumulates steps or risk, its authority budget shrinks, forcing re-authorization before it can proceed. A compromised agent stays contained — it can't self-escalate into adjacent systems. Any attempt to invoke an out-of-scope resource generates a security event, not a silent failure.
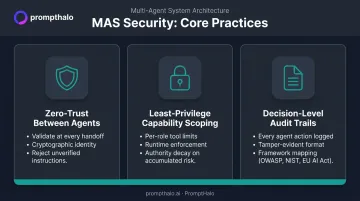
Maintain Decision-Level Audit Trails
Logs that capture only inputs and outputs are insufficient for MAS security. You need:
- Every agent action, tool call, and inter-agent message recorded
- Tamper-evident, append-only format that supports forensic replay
- Decision-level granularity: not just what happened, but which agent initiated it, under what authority, with what context
- Mapping to recognized frameworks—OWASP LLM Top 10, NIST AI RMF, EU AI Act—so logs are useful for compliance reporting, not just incident investigation
Multi-Agent AI Security in Regulated Environments
Financial services represent the highest-stakes MAS deployment environment. Agents in these workflows may autonomously process payments, contribute to credit decisions, or trigger compliance filings. A manipulated tool call or poisoned context window creates both operational failure and direct regulatory exposure.
The EU AI Act classifies AI systems used to evaluate creditworthiness or establish credit scores for natural persons as high-risk, with obligations covering risk management, technical documentation, human oversight, and cybersecurity. NIST AI RMF organizes controls under Govern, Map, Measure, and Manage—requiring ongoing monitoring, not just pre-deployment checks.
A purpose-built MAS security solution must provide:
- Inline enforcement on every agent decision before it executes, not post-hoc logging that documents failures after the fact
- Per-action budget and scope enforcement with authority decay as task context shifts
- Tamper-evident audit logs at the decision level, mapped to EU AI Act, NIST AI RMF, and OWASP LLM Top 10
- Model-agnostic deployment that requires no access to or retraining of underlying models
PromptHalo is built for this environment. It deploys in under a day with no model retraining and no code rewrite, sitting inline on every inference, tool call, and agent-to-agent handoff. Compliance-ready audit logs capture the acting agent's identity, session context, decision reason, and timestamp in an append-only format that cannot be modified after the fact.
Frequently Asked Questions
What is the difference between a single-agent and a multi-agent AI system?
A single agent perceives, reasons, and acts in isolation—handling tasks serially with no inter-agent communication. A multi-agent system involves multiple autonomous agents that share context, communicate, and coordinate actions toward a shared objective. That collaboration enables far greater capability, but introduces inter-agent trust and security challenges that simply don't exist in single-agent deployments.
What makes multi-agent systems harder to secure than traditional AI deployments?
Three core reasons make them fundamentally harder to secure:
- Agents treat each other as trusted by default, creating exploitable channels for injected instructions
- The attack surface multiplies with every agent and handoff added to the pipeline
- Agents interact at machine speed, leaving no window for human review of inter-agent exchanges
What is agent-to-agent prompt injection and why is it dangerous?
It occurs when one agent embeds malicious instructions inside a message that a downstream agent executes as a trusted directive. The injected content can travel across multiple hops before triggering, making attribution difficult—and a single injection can steer an entire agent pipeline without any visible external attack.
Can traditional security tools like firewalls or DLP protect multi-agent systems?
No. Firewalls inspect network traffic, DLP scans data at rest or in transit, and endpoint tools monitor device behavior. None of them can inspect the semantic content of agent reasoning, inter-agent messages, or tool call parameters—which is exactly where prompt injection and context poisoning attacks live.
What is capability bleed in a multi-agent system?
Capability bleed is when an agent gains unintended access to tools or data outside its intended role—typically from shared toolsets or inherited permissions. A single over-privileged agent can reach systems and data that should be completely inaccessible to that part of the workflow, then pass the results downstream as legitimate output.
What compliance frameworks apply to securing multi-agent AI systems?
OWASP LLM Top 10, NIST AI RMF, and the EU AI Act are the most directly relevant current frameworks. Security controls should generate decision-level audit logs explicitly mapped to these standards, supporting both internal governance and external regulatory reporting.


