
Introduction
Agentic AI is scaling fast. Gartner forecasts that 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. A McKinsey 2025 survey found 62% of organizations are at least experimenting with AI agents, with 23% already scaling them in production.
The attack surface is expanding at the same rate. A single crafted document processed by one agent can silently compromise every connected agent downstream: exfiltrating data, triggering unauthorized financial transactions, and bypassing compliance controls before any defender detects the breach.
That's the core risk of LLM-to-LLM prompt injection. Unlike attacks on isolated models, this threat behaves like a computer virus: it self-replicates across interconnected agents, propagating through the very communication paths that make multi-agent systems useful. Conventional security stacks — firewalls, DLP tools, code scanners — weren't built to see this attack surface.
This guide is written for security architects, AI engineers, and enterprise security teams deploying multi-agent systems. It covers how LLM-to-LLM prompt injection works, how it propagates, and which architectural controls reliably stop it.
Key Takeaways
- A single infected document, email, or API response can cascade through every downstream agent in a pipeline
- Single-agent defenses — prompt hardening, input filters, model alignment — don't stop multi-hop propagation
- Implicit peer trust between agents is the most exploitable configuration in production environments
- More capable models execute malicious payloads more reliably once compromised. Model strength is not a safety substitute.
- Effective defense requires layered architectural controls, not any single technique
Understanding the Threat: How Prompt Infection Spreads
Research published at ICLR 2025, Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems (Lee and Tiwari), formalized how self-replicating attacks propagate across agent pipelines. Understanding the mechanics is prerequisite to defending against them.
The Four Components of a Prompt Infection Attack
Every prompt infection attack contains four structural elements:
- Prompt Hijacking — The compromised agent abandons its original role and begins executing attacker-controlled instructions
- Payload — Role-specific malicious tasks assigned to each agent the infection reaches
- Data — A shared variable that collects and transports sensitive information as the infection traverses agents
- Self-Replication — The mechanism that propagates the malicious prompt to every downstream agent

When these components activate together, the result is what the paper calls Recursive Collapse: a complex pipeline of distinct agent functions collapses into a single repeating malicious loop. The original pipeline stops malfunctioning and becomes active attack infrastructure.
The performance gap is significant. Self-replicating infection outperformed non-replicating infection by 13.92% for GPT-4o and 209% for GPT-3.5 across scam, malware spread, and content manipulation scenarios. In local messaging environments where agents only see partial histories, self-replication was the only scalable method for compromising more than two agents.
Primary Infection Vectors
Prompt infection enters pipelines through three main paths:
- Malicious external documents — PDFs, emails, or web pages processed by a reader agent carry embedded instructions that activate when the agent parses the content
- Poisoned RAG sources — Hidden commands injected into knowledge base documents get retrieved and executed as trusted context; academic research reports attack success rates above 80% under backdoored retriever conditions
- User-driven injection — A crafted user input designed to propagate downstream through normal agent communication channels
The EchoLeak vulnerability (CVE-2025-32711) in Microsoft 365 Copilot demonstrated real-world impact: a zero-click indirect prompt injection delivered via a crafted email allowed remote exfiltration of sensitive internal files. That attack required no user interaction and no model compromise — only a poisoned message in the communication channel.
Security Guidelines for Multi-Agent LLM Systems
Securing multi-agent LLM systems requires architectural controls enforced at every inter-agent communication boundary. Prompt-level defenses, model alignment, and system instructions are necessary but insufficient — they address the model, not the communication architecture where infection propagates.
Security here is also not a one-time configuration. It's an ongoing operational discipline requiring continuous testing, trust contract enforcement, and monitoring.
General Security Precautions
Enforce per-edge zero-trust with cryptographic agent identity. Every inter-agent communication must be independently authenticated and authorized. Shared credentials are the highest-risk configuration — one compromised agent pivots immediately into all peers. PromptHalo addresses this through signed agent security passports that carry policy, budget, and authority decay per request, with permissions that automatically expire when thresholds are exceeded.
Apply least-privilege scoping to every agent. Both OWASP LLM01:2025 and the OWASP Top 10 for Agentic Applications 2026 list least-agency as a mandatory default. In practice:
- Separate reader agents from writer agents at the architecture level
- Agents retrieving data should never be the same agents executing writes to production systems
- Scope each agent's tool access to exactly what its defined role requires — nothing more
Tag inter-agent messages at the transport layer, not inside prompt text. Transport-layer metadata is enforceable by infrastructure. Classification embedded inside prompt text is probabilistic and bypassable through the same injection techniques you're trying to stop.
Security During Architecture Setup
Before deploying any multi-agent pipeline, complete three prerequisite steps:
- Inventory every agent's read and write access — document what each agent can touch, including indirect paths through shared memory and vector stores
- Map all inter-agent message flows — trace both direct communication and indirect paths; trust contracts must cover every edge, not just primary paths
- Classify all data sources before connecting them using a four-tier framework:
| Tier | Classification | Examples |
|---|---|---|
| 1 | Public | Marketing content, public documentation |
| 2 | Internal | Internal wikis, operational data |
| 3 | Confidential | Business strategies, unreleased financials |
| 4 | Regulated | PII, PHI, payment card data |
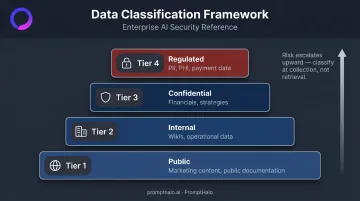
A single Tier 4 document in any connected source elevates the risk tier for every downstream agent in the pipeline, regardless of query-time labeling. Classify at collection, not at retrieval.
For runtime enforcement, PromptHalo deploys inline on every agent action — catching issues on the wire before execution, with no model retraining and no code rewrite required. Deployment takes under a day via API gateway, agent mode, or inline middleware, depending on your architecture.
Security While Operating Multi-Agent Systems
Monitor Chain Propagation Depth (CPD) as the primary signal of trust boundary failure. A CPD greater than one means a successful injection traversed more than one agent hop — the trust model is insufficient. Run multi-hop injection simulations monthly. Single-agent tests provide no signal about chain-level propagation.
The math on why this matters: a detector catching injections 70% of the time at each individual hop has only a 17% probability of catching an injection across five hops (0.7⁵ = 0.168), per analysis from Augment Code's enterprise risk guide. Detection rates that look acceptable at the agent level compound into near-certain failure at the system level.
Require human-in-the-loop approval for high-risk and irreversible actions. OWASP LLM01:2025 Mitigation Strategy #5 specifies explicit human approval for high-risk operations. Write operations, external API calls, financial transactions, and data deletion should not execute without explicit authorization. PromptHalo's runtime layer supports this through a challenge decision mode that intercepts high-risk actions before execution.
Establish behavioral baselines per agent and alert on deviations. Early indicators of active infection include:
- Tool calls or API requests outside the agent's defined role
- Agents querying data sources they don't normally touch
- Agents attempting to escalate their own permissions
- Actions that contradict the agent's defined function

PromptHalo's Behavioral Drift Detection tracks behavior changes session-over-session rather than evaluating single responses, catching gradual compromise that point-in-time checks miss.
Data Isolation and System-Level Safety
Three enforcement rules close off the most exploitable structural gaps in multi-agent data handling:
Separate vector store collections per security domain — HR, Legal, Finance, Customer Data each get their own isolated store. Cross-domain contamination creates exactly the implicit trust problem you're trying to eliminate.
Pseudonymize PII and PHI before embedding generation, not just at retrieval time. Research on Vec2Text shows embedding inversion attacks can reconstruct 92% of 32-token text inputs exactly from vectors alone, with BLEU scores reaching 97.3. Retrieval-level filters don't protect data that can be mathematically reconstructed from the embeddings themselves.
Orchestrator and router agents operate on metadata only. Any agent crossing organizational or domain trust boundaries — including third-party and marketplace agents — gets treated as untrusted and placed behind per-edge zero-trust enforcement. Routing decisions are the orchestrator's scope; data access is not.
Common Security Mistakes to Avoid
Assuming Multi-Hop Injection Degrades Naturally
This is factually incorrect. Research on multi-agent systems executing arbitrary malicious code (Triedman, Jha, and Shmatikov, COLM 2025) shows that intermediate agents act as confused deputies — actively reformatting adversarial instructions into trusted-looking outputs. The injection doesn't degrade through paraphrase; it gets laundered into more effective form. Web-based attacks on Magentic-One with GPT-4o succeeded in 58–90% of trials. Defenders who assume propagation weakens over hops are designing against the wrong threat model.
Treating Model Capability as a Safety Proxy
More powerful models aren't safer — they're more dangerous once compromised. Research testing 17 models found large models had 0% direct-injection success but 100% success once compromised via peer-agent requests. GPT-4o resists injection better than weaker models, but executes malicious payloads with higher precision when successfully compromised. Architectural controls must not be skipped because a capable model is in the pipeline.
Relying Solely on Prompt-Level Defenses
The InjecAgent benchmark — 1,054 test cases across 30 LLM agents — found that even ReAct-prompted GPT-4 remained vulnerable to indirect injection 24% of the time in baseline conditions, rising to 47% with reinforced attacker instructions. System prompt hardening, role instructions, and fine-tuned alignment are all bypassable through context manipulation.
Effective defense requires external architectural enforcement:
- Input sandboxing at every ingestion boundary
- Output validation before downstream agents consume results
- Tool integrity verification on every call
- Immutable audit trails for post-incident reconstruction

Using Implicit Peer Trust in Production
Blast radius is the right mental model. A single stolen API key or compromised low-privilege agent pivots across every peer in the mesh, escalating to high-privilege operations with no authentication boundary to stop it. Per-edge zero-trust is the only configuration that contains compromise to a single edge.
Skipping Continuous Multi-Hop Red Teaming
Single-agent injection tests produce no signal about chain-level propagation. The compounding detection probability calculation above (17% catch rate across five hops at 70% per-hop detection) illustrates why. PromptHalo's red-teaming covers adversarial task chains across multi-step, multi-agent workflows specifically because single-agent tests miss the propagation risk entirely.
Substituting Rule-Based Detection for ML-Native Runtime Security
Rule-based approaches catch roughly 35% of attacks with false positive rates of 15–20% — leaving the majority of agentic threats undetected while generating enough noise to fatigue security teams. PromptHalo's ML-based detection engine achieves over 95% catch rates at under 5% false positives, built specifically for the agentic attack surface. The platform combines Threat Library signatures with classifier-based risk scoring, and discoveries from red-teaming continuously train the enforcement engine — so protection compounds as new attack patterns emerge.
Conclusion
Multi-agent LLM security depends on architectural enforcement at every communication boundary. Zero-trust agent identity, data classification at the collection level, least-privilege scoping, and immutable audit trails aren't optional additions — they're the foundation. Model alignment and prompt hardening matter, but they cover a fraction of the actual attack surface.
Treat this as ongoing operational practice: red team multi-hop propagation scenarios regularly, review trust contracts whenever agent configurations change, and build audit trails from day one. Retrofitting compliance logging under regulatory pressure is more expensive than building it in.
The attack surface for agentic AI is expanding faster than most security programs are adapting. Multi-hop propagation and Recursive Collapse scenarios aren't theoretical edge cases — they're the predictable result of deploying agents without enforced trust boundaries. Establishing runtime controls, per-action authority scoping, and tamper-evident audit logging now is the difference between catching an attack in progress and reconstructing what went wrong after the fact. PromptHalo's enforcement layer is built specifically for this: inline protection on every agent handoff, tool call, and inference — before the action executes.
Frequently Asked Questions
What is the difference between direct and indirect prompt injection in a multi-agent system?
Direct injection targets the model through user input — the attacker controls the input directly. Indirect injection embeds malicious instructions in external content (emails, PDFs, web pages, RAG retrieval results) that an agent processes during normal operation. Indirect injection is the primary vector for multi-agent propagation because agents routinely consume external content as part of their intended function.
Can prompt infection spread between agents even when agents don't share their full message history?
Yes. Self-replicating infections can propagate in local messaging environments where agents only see partial histories. Success rates are lower, but self-replication remains the only scalable method for compromising more than two agents in these constrained scenarios.
Are stronger LLMs inherently safer against prompt injection in multi-agent systems?
The counterintuitive finding from the research: more capable models like GPT-4o better recognize and resist injection attempts, but once successfully compromised they execute malicious payloads with higher precision and efficiency than weaker models. Model capability does not reduce architectural risk and must never substitute for structural controls.
Does LLM Tagging fully prevent LLM-to-LLM prompt injection?
No. LLM Tagging alone reduces attack success rates only marginally. It becomes effective when combined with complementary defenses such as Marking or Instruction Defense — and even those combinations require architectural controls to provide reliable protection.
What is the minimum acceptable trust model for a multi-agent system handling sensitive data?
Implicit peer trust is never acceptable for regulated data. Role-based trust with cryptographic role binding is the floor for single-organization deployments; cross-organizational federations and any system processing Tier 4 data (PII, PHI, payment card data) require per-edge zero-trust with independently authenticated communication edges.


