
Introduction
AI deployments are moving faster than the controls governing them — and the breach data is catching up. IBM's 2025 Cost of a Data Breach Report found that 13% of organizations reported breaches involving AI models or applications, with 60% resulting in compromised data and 31% causing operational disruption. More telling: 97% of those organizations lacked proper AI access controls.
In financial services, the cost of getting this wrong is steep. IBM puts the average financial-sector breach at $6.08M, with U.S. organizations averaging $10.22M. That figure doesn't include regulatory fines, client churn, or reputational damage from a disclosed incident involving customer PII or deal data.
Most organizations deploy AI without runtime safeguards. Static configuration controls aren't enough — exposure accumulates at inference time, in tool calls, and across agent decisions made against live sensitive data. This guide breaks down where that risk surfaces and what security teams can do about it.
Key Takeaways
- AI introduces attack vectors — prompt injection, data leakage, and retrieval poisoning — that traditional firewalls and DLP tools can't detect
- Safe AI deployment requires controls at three layers: pre-deployment, during operation, and at the agent level
- Enterprise AI deployments require explicit data retention controls and output filtering that consumer-grade tools don't provide
- Agentic AI systems introduce risks that standard security tooling was never built to handle — runtime enforcement is required
- AI security is an ongoing operational function, not a deployment-day checkbox
Safety Guidelines for Using AI With Customer and Deal Data
Protecting sensitive business data in AI workflows requires more than perimeter security. Firewalls and DLP tools protect deterministic systems — they check known patterns against known rules. AI is probabilistic. Its outputs depend on context, retrieved content, and instructions that change with every interaction.
This creates two overlapping risk categories:
- Operational risk — unintentional data exposure through model outputs, overpermissioned agents, or misconfigured retrieval layers
- Adversarial risk — deliberate manipulation through prompt injection, retrieval poisoning, or jailbreaks designed to hijack AI behavior

Both require runtime governance, not just perimeter protection.
General Safety Precautions
Apply the principle of least privilege. AI systems and agents should only access data they strictly need for a defined task. Overly permissive access creates silent leakage risk — the AI doesn't need to be compromised to expose data it was never meant to see.
PromptHalo enforces this through per-action authorization, issuing agent security passports with policy, budget, and authority decay built in. An agent cannot grant itself more access than it was initially scoped.
Classify data before it enters any AI workflow. Customer PII, financial records, deal terms, and contract data should be tagged and handled differently. Some categories should never be passed into general-purpose AI tools without masking. Classification isn't just a privacy function — it determines which data can flow into which AI contexts at all.
Establish an employee AI use policy. Specify which data types can and cannot be submitted to AI tools — covering both internal deployments and third-party tools employees use informally. Shadow AI is a real cost driver: IBM reported that high shadow-AI use added an average $670,000 to breach costs, and only 34% of organizations audited for unsanctioned AI use.
Safety During AI Deployment and Configuration
Vet AI vendors before deployment. Ask specifically:
- Are prompts, outputs, or retrieved content used for model training?
- Who retains data ownership, and for how long?
- Are third parties or subprocessors given access to content?
- Is zero data retention available as an option?
- What compliance certifications apply (SOC 2, ISO 27001, GDPR, CCPA)?
Walk away from any vendor who can't answer these clearly. OpenAI's consumer services, for instance, may use content for model improvement unless users opt out, while enterprise plans operate under different defaults. Never assume a vendor's consumer policy applies to its enterprise offering.
Isolate AI environments from core data systems. Direct, unmediated AI access to production databases, CRM records, or deal management platforms creates unnecessary blast radius. Scoped API access and sandboxed environments limit what an AI can touch if something goes wrong.
Build audit infrastructure before go-live. Sandboxed environments limit exposure, but they don't replace accountability — AI decisions affecting customer data or deal outcomes must be logged from day one in a tamper-evident format. PromptHalo's compliance-ready audit logs capture every decision with its reason, agent identity, session context, and timestamp — append-only, so records cannot be modified after the fact. This creates the replayable evidence trail required for regulatory reporting under frameworks like the EU AI Act and SOC 2.
Safety While Operating AI With Live Customer and Deal Data
Enforce input validation and output filtering in production. AI inputs should be checked for prompt injection patterns before processing, and outputs should be filtered for sensitive data before reaching users or downstream systems. This step is frequently skipped — and it's one of the most direct routes to data exposure.
The OWASP LLM Top 10 lists Improper Output Handling (LLM05) as a core risk specifically because AI output should be treated as untrusted input to downstream systems.
Monitor AI behavior continuously. Safe operation is not passive. Behavioral drift — gradual shifts in AI outputs across sessions — can gradually undermine compliance and reliability before any single incident triggers an alert.
PromptHalo detects drift by tracking behavior across sessions rather than evaluating individual responses in isolation, combining Threat Library signatures with classifier-based risk scoring. This achieves a catch rate above 95% at under 5% false positives, compared to roughly 35% for rule-based approaches.
Practice data minimization in prompts. Never include raw customer records, full deal terms, or unmasked PII in AI prompts unless operationally unavoidable and secured by runtime controls. The less sensitive data an AI handles, the less it can expose. This is one of the simplest and most consistently overlooked controls in enterprise AI deployments.
Deploy inline enforcement for complete coverage. For organizations that need protection across every inference and tool call, a runtime security layer is the only way to enforce this consistently at scale. PromptHalo's enforcement engine makes allow, restrict, challenge, or deny decisions in under 100ms — blocking prompt injection, jailbreaks, and out-of-scope actions before they execute, without requiring model access or retraining.
Agentic AI and Environmental Safety Considerations
Agentic AI systems — those that autonomously call external tools, query knowledge bases, or hand off tasks between multiple AI agents — introduce an attack surface that standard DLP, firewalls, and code scanners were never designed to address. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by end of 2026, up from less than 5% in 2025. Each autonomous tool call or retrieval action is a potential data exposure point.
Retrieval Poisoning
When an AI's retrieval layer (RAG) pulls from a compromised or manipulated knowledge base, the model can be steered toward incorrect, biased, or attacker-controlled outputs. The user's query looks clean. The system prompt is intact. The attack lives entirely in what the model retrieved and trusted.
This is especially dangerous in deal workflows or customer-facing AI, where a poisoned knowledge source can produce inaccurate pricing, incorrect policy responses, or fabricated compliance guidance. OWASP classifies this under LLM04 (Data and Model Poisoning) in its 2025 LLM Top 10.
Defending against this requires detection that operates at the embedding level, not just the text surface. PromptHalo detects retrieval and RAG injection using embedding-based scoring against a shared Threat Library, catching attack patterns that static rule-based systems miss.
Multi-Agent Handoffs
When one AI agent passes context and instructions to another, each handoff is an opportunity for scope creep, privilege accumulation, or injected instructions to propagate through the chain unchecked.
The controls required here are specific:
- Scope enforcement: each agent is bound to a defined permission boundary and cannot operate outside it
- Authority decay: permissions narrow automatically as actions accumulate, preventing privilege creep across the chain
- Per-action budgets: agents trigger re-authorization when action thresholds are exceeded, not just session limits

These controls require external enforcement — agents can't self-regulate across a chain. PromptHalo addresses this through agent security passports: signed credentials that travel with each request, carrying policy, budget, and authority decay built in. Scope is enforced at the action level, not left to the agent to honor.
Common Safety Mistakes to Avoid
Mistake 1: Using Consumer-Grade AI Tools for Customer PII or Deal Data
The assumption that a tool "doesn't store anything" is rarely accurate. Most consumer AI tools retain data for model improvement by default unless users actively opt out. In regulated industries, that constitutes an unauthorized data transfer — regardless of whether the vendor intended harm.
Samsung restricted employee use of ChatGPT-like tools in 2023 after sensitive information was entered into the system. The exposure wasn't the result of an attack. It was routine use with no policy controls in place.
Mistake 2: Assuming Safe Prompts Produce Safe Outputs
Prompt injection via indirect sources, model inversion, and retrieval poisoning can all produce harmful outputs even when the input prompt was carefully written.
In 2024, a British Columbia tribunal found Air Canada liable for incorrect bereavement fare information its chatbot provided. Organizations bear responsibility for what AI outputs — not just what they intended it to say.
Mistake 3: Treating AI Security as a One-Time Deployment Checklist
IBM's data on breached organizations reveals a consistent gap in ongoing governance:
- 63% lacked or were still developing AI governance policies at the time of their breach
- Only 34% audited for unsanctioned AI use
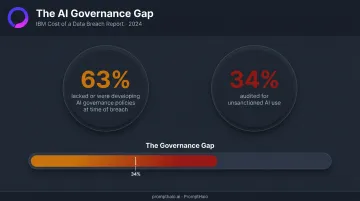
AI systems change behavior as they encounter new data and inputs. Without continuous monitoring, anomaly detection, and regular access reviews, security posture degrades between audits.
Conclusion
Safe AI use with customer and deal data depends on three things working together: disciplined data governance before deployment, enforced input and output controls during operation, and purpose-built runtime protection for agentic workflows.
None of these substitutes for the others. A clean vendor vetting process doesn't protect against prompt injection at runtime. Output filtering doesn't compensate for overpermissioned agents. And a strong security posture at launch degrades without continuous monitoring.
As AI systems take on more autonomous decisions involving sensitive data, organizations that build runtime safety into standard operations — treated as a continuous operational discipline rather than a one-time configuration — are the ones that expand their AI capabilities without widening their regulatory and reputational exposure. That's the operational model PromptHalo is built around: real-time enforcement at every agent decision, so safety compounds as your AI footprint grows.
Frequently Asked Questions
What is the ISO standard for AI security?
ISO/IEC 42001:2023 is the primary certifiable management system standard for AI governance and security. It requires a documented AI management system covering policies, controls, and continual improvement. This makes it especially relevant for financial services and healthcare organizations subject to regulatory audit.
What is a critical measure to ensure the security of customer data in AI systems?
Enforcing strict access controls and data minimization — ensuring AI only accesses the customer data required for a specific task — is the foundational control. Pair this with continuous output monitoring and tamper-evident logging to detect and document unauthorized data exposure in real time.
What is prompt injection and why is it dangerous for business AI systems?
Prompt injection is an attack where malicious instructions are embedded in inputs or retrieved content to hijack the AI's behavior, potentially causing it to leak data, bypass access controls, or execute unauthorized actions. It's especially dangerous in agentic systems that autonomously call tools or query databases.
How is AI data security different from traditional cybersecurity?
Traditional cybersecurity protects deterministic systems with known behavior. AI security must address probabilistic models whose outputs can be manipulated through input crafting, retrieval poisoning, or adversarial prompts. Firewalls and DLP tools were not designed to detect or block these attacks.
What are the biggest AI security risks for financial services?
The primary risks are prompt injection into customer-facing AI, retrieval poisoning of financial knowledge bases, unauthorized data leakage through AI outputs, and audit trail gaps that create compliance exposure under frameworks like the EU AI Act and SOC 2.
How should I vet an AI vendor before trusting them with sensitive deal data?
Ask whether data is used for model training, who owns it, how long it's retained, and whether third parties receive it. Verify compliance with GDPR, CCPA, and standards like ISO 27001 and SOC 2. Treat vague or evasive answers to any of these questions as an immediate disqualifier.


