
Introduction
According to Gravitee's 2026 State of AI Agent Security report, 54% of senior technology leaders surveyed reported experiencing or suspecting an AI agent security incident in the past 12 months, and 34.9% confirmed one. That same report found 90% of organizations have unmonitored agents running in production and 48% running completely unsecured.
The gap between governance documentation and actual runtime enforcement is where the real risk lives. Autonomous agents with elevated permissions can read emails, approve transactions, modify configurations, and invoke other agents. A compromised agent acts at machine speed, traversing systems before any alert fires.
Cloud-native environments make this harder to contain. Kubernetes and containerized infrastructure aren't the problem — agents behave non-deterministically in ways existing controls were never designed to detect. Firewalls inspect packets. DLP tools scan data. Neither can evaluate the intent behind an LLM inference or the legitimacy of a tool call.
This guide covers what AI agent security in cloud-native deployments requires — from baseline controls and deployment configuration through runtime enforcement and compliance. Specifically, it covers:
- Baseline security controls and deployment configuration for cloud-native agents
- Runtime enforcement: monitoring tool calls, agent-to-agent handoffs, and inference behavior
- Identity, permissions, and least-privilege design for autonomous agents
- Compliance mapping and audit logging for regulated environments
Key Takeaways
- 54% of organizations have already experienced a confirmed or suspected AI agent security incident, yet most run agents without runtime monitoring.
- Firewalls, WAFs, and DLP tools cannot inspect the intent behind an LLM inference — purpose-built controls are required.
- Activating enforcement before behavioral baselines are established will break production — always observe first.
- Every MCP server connection is a new attack surface that must be treated as a security boundary.
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act all require decision-level, tamper-evident audit logs at the time of inference.
Why AI Agent Security in Cloud-Native Environments Is Different
Traditional containerized microservices behave predictably. You can write a static network policy, configure RBAC, and trust that the workload will do exactly what its manifest says. AI agents don't work that way.
An agent executes generated code, traverses permissions dynamically based on prompt inputs, and invokes tools that may not have been part of its original design. The declared behavior in a deployment manifest and the actual runtime behavior are entirely different things.
The Elevated-Permission Problem
Agents are deliberately granted broad access — to APIs, databases, email systems, and external services — because automation requires it. That access creates compounding risk: a single agent compromise doesn't affect one system, it affects everything the agent can reach.
The Gravitee report found that only 14.4% of organizations require full security or IT approval before an AI agent goes live. That means the vast majority of production agents are operating with permissions that were never formally reviewed.
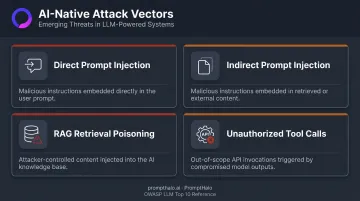
The AI-Native Attack Surface Traditional Tools Miss
OWASP's LLM Top 10 and NIST define the core threat categories:
- Direct prompt injection — malicious instructions arrive in the user prompt and redirect agent behavior
- Indirect prompt injection — malicious instructions are hidden inside documents, emails, or database records the agent retrieves and processes as legitimate input
- RAG retrieval poisoning — attackers inject malicious content into a knowledge base so the agent executes attacker-controlled instructions as retrieved facts
- Unauthorized tool calls — agents invoke APIs and tools outside their intended scope, either through compromise or prompt manipulation
The EchoLeak vulnerability (CVE-2025-32711) demonstrated this in production: a crafted email caused Microsoft 365 Copilot to exfiltrate enterprise data through indirect prompt injection, bypassing existing classifiers entirely.
Firewalls and DLP tools operate at the network and data layer. They inspect traffic and files. They cannot inspect the intent behind an LLM inference or determine whether a tool invocation is legitimate.
The Kubernetes Compounding Factor
That blind spot compounds when you consider the infrastructure most agents run on. According to the CNCF's 2024 Annual Survey, 84% of container users run Kubernetes in production, and generative AI workloads on Kubernetes are now mainstream across enterprises. The platform was built for stateless, deterministic workloads. AI agents are neither.
Specific Kubernetes risks for AI agent deployments:
- Over-permissioned service accounts — pods that don't specify a service account inherit the namespace default, which frequently carries more access than the agent needs
- Namespace isolation failures — agents sharing namespaces with non-AI workloads can access cluster resources they were never intended to reach
- MCP server connections — a single MCP server can expose an agent to dozens of downstream systems; most go live without any security review
Security Guidelines for AI Agents in Cloud-Native Deployments
Agent security is not a pre-deployment checklist. It is an ongoing operational discipline that must match the non-deterministic nature of agent behavior — continuous discovery, observation, enforcement, and audit.
Baseline Security Controls
You cannot baseline, govern, or enforce controls on agents you do not know exist. Shadow agents — deployed by development teams without security review — are common in enterprise environments. They typically carry over-permissioned access, no audit logging, and no behavioral controls. For Kubernetes environments, automated discovery should scan running workloads across namespaces and flag any AI agent processes that lack a registered security profile.
Least privilege must come from observed behavior, not declared permissions. A deployment manifest may grant an agent access to 40 APIs while the agent only contacts 8 in normal operation. Restricting to declared permissions without runtime data produces either over-permissive policies or production breakage — observed behavior must drive enforcement decisions.
Establish behavioral baselines per agent workload before activating enforcement. Baselines define what tool calls, API destinations, data access patterns, and network connections are normal for a specific agent. Without one, every unfamiliar action becomes either a missed threat or a false positive — and your team can't act on either reliably.
These three controls — inventory, observed least privilege, and behavioral baselines — set the foundation. Deployment validation is where they get tested.
Security During Agent Deployment and Configuration
Before any agent goes live, validate:
- Tool allowlists — is the agent bound only to approved tool sets, or does it have access to tools it will never legitimately use?
- Permission scope boundaries — are service accounts scoped to the minimum the agent actually requires?
- Human-in-the-loop gates — are approval checkpoints in place for high-impact actions such as data writes, financial transactions, and configuration changes?
If any of these controls are absent or unverified, deployment should not proceed.
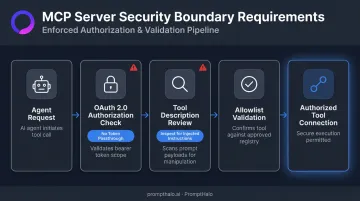
Treat every MCP server connection as a security boundary. The MCP Authorization specification requires OAuth 2.0 Resource Indicators and prohibits token passthrough, meaning each tool connection must be independently authorized rather than inherited from the agent's session token. Invariant Labs has documented that malicious instructions can be embedded directly in MCP tool descriptions — invisible to users but fully visible to AI models. Every MCP connection requires review and allowlisting before it goes live.
Runtime Security Controls
Post-execution detection is forensics. By the time an alert fires, an exfiltration or configuration change may already be complete. Inline controls on every inference, tool call, and agent-to-agent handoff are the only enforcement point that matters.
PromptHalo is built specifically for this layer. It operates inline across any AI application, making per-action decisions (allow, restrict, challenge, deny, or monitor) in under 100ms — without requiring access to the underlying model.
Because it's model-agnostic, it deploys in under a day with no model retraining and no code rewrite.
Detecting both direct and indirect prompt injection in real time requires understanding where each type enters. Direct injection arrives in the user prompt. Indirect injection is hidden inside content the agent retrieves — a document, email, RAG index entry, or ticketing system record — and processed as a legitimate instruction. In cloud-native environments, the indirect injection surface includes every external data source the agent reads. Palo Alto Unit 42 has documented web-based indirect prompt injection observed in the wild, and enterprise deployments face the same exposure.
Behavioral drift requires continuous monitoring. When an agent calls APIs it has never called before, accesses data stores outside its normal pattern, or initiates connections to unexpected endpoints, treat the deviation as investigation-worthy — not as an assumed workflow change.
The distinction between normal evolution and active compromise is where intent-focused behavioral analysis separates itself from rule-based alerting. Rule-based systems flag the deviation; behavioral analysis determines whether it fits a known threat pattern.
Infrastructure and Ecosystem Security Considerations
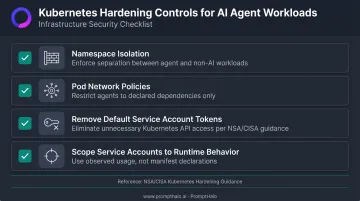
Kubernetes-specific hardening for AI agent workloads should include:
- Enforce namespace isolation between agent workloads and non-AI services
- Restrict pod-level network policies so agents can only reach declared dependencies
- Remove default service account tokens from pods that don't require Kubernetes API access (per NSA/CISA Kubernetes Hardening Guidance)
- Scope service account permissions to what the agent actually uses at runtime, not what the manifest declares
Without this layer, a compromised agent can move laterally to other pods or cluster resources using inherited service account credentials.
In orchestrator-to-subagent architectures, each handoff is a potential injection or impersonation point. Treat each one as a new trust boundary, not an inherited session. An orchestrator agent should not be able to instruct a subagent to perform actions outside the subagent's defined authority.
PromptHalo addresses this through agent security passports: signed credentials that travel with each request and carry policy, budget, and authority decay parameters. Agent authority doesn't persist indefinitely — budgets decay across time, steps, and risk thresholds, forcing re-authorization when an envelope is exceeded.
Common AI Agent Security Mistakes to Avoid
Most AI agent security failures aren't sophisticated attacks — they're predictable gaps that teams leave open by applying the wrong mental models to a new class of workload. Here are the four mistakes that show up most consistently.
Assuming Legacy Security Tools Cover the AI Attack Surface
Firewalls, DLP solutions, and network-layer scanners were built for deterministic workloads. They inspect traffic and data — not the intent behind an LLM inference or the legitimacy of a tool invocation. Teams relying solely on these controls are blind to prompt injection, retrieval poisoning, and unauthorized tool calls: the attack vectors that actually target agents.
Skipping Behavioral Baselining Before Writing Policies
Without observing what agents actually do in production, enforcement policies are either too permissive (meaningless) or too restrictive (breaks production). Without a behavioral baseline, enforcement is guesswork — and guesswork breaks production. Policies need evidence behind them before they can be trusted.
Ignoring Shadow AI Deployments
Development teams frequently deploy agents without security review. These shadow deployments sit outside every governance control the security team has implemented, and they typically carry the highest-risk access profiles in the environment — because no one reviewed them. Discovery can't be manual at the pace agents are being spun up.
Treating Compliance as a Documentation Exercise
Audit logs mapped to OWASP LLM Top 10, NIST AI RMF, or the EU AI Act must be generated at the decision level and be tamper-evident — not assembled after an incident from fragmented application logs. In regulated environments like fintech, incomplete or reconstructed audit trails can constitute a compliance failure on their own, regardless of whether a breach occurred.

Conclusion
AI agent security in cloud-native environments depends on continuous runtime vigilance, behavioral baselines built before enforcement activates, purpose-built controls that operate inline at the agent action level, and audit trails generated at the decision level. Unlike a launch checklist, it demands continuous adjustment as agents gain new tool integrations, expanded permission scopes, and updated model versions.
Security and platform engineering teams that embed these controls into the DevSecOps lifecycle — rather than bolting them on post-launch — are the ones shipping agentic features at speed without accumulating regulatory debt. The goal is to grow agent autonomy without growing your incident surface. That requires discovery, runtime enforcement, and compliance evidence working together from day one.
Frequently Asked Questions
What platforms help secure AI agents?
Effective AI agent security platforms must provide runtime enforcement (not just posture scanning), behavioral detection, agent discovery including shadow agents, and tamper-evident audit logging. Legacy CNAPP, DLP, and WAF tools were not built to inspect the intent behind LLM inferences or tool calls — platforms like PromptHalo operate inline at the inference and tool-call layer, enforcing decisions on every agent action before it executes.
What are the 4 C's of cloud-native security?
The 4 C's — Code, Container, Cluster, and Cloud — define the four hardening layers in cloud-native environments. AI agent deployments introduce a fifth consideration: the agent's runtime behavior and tool call surface, which sits above the cluster layer and requires behavioral controls the traditional 4 C's framework was not designed to address.
What is prompt injection and how does it threaten cloud-native AI agents?
Prompt injection is an attack where malicious instructions hijack an agent's goals. Direct injection arrives in the user prompt; indirect injection hides in documents, emails, or data the agent retrieves — including any RAG index, shared storage, ticketing system, or external API in a cloud-native environment.
How is AI agent security different from traditional cloud security?
Traditional cloud security governs deterministic workloads with static policies. AI agents behave non-deterministically — changing their tool calls, data access patterns, and actions based on prompt context at runtime. That requires behavioral observation and intent-focused enforcement rather than rule-based controls that assume fixed, predictable behavior.
What compliance frameworks apply to AI agent deployments?
Three frameworks apply directly. OWASP LLM Top 10 provides the primary threat taxonomy for LLM-based systems. NIST AI RMF covers Govern, Map, Measure, and Manage functions for US federal risk management. The EU AI Act mandates transparency, human oversight, and audit logging for high-risk AI applications — all three require decision-level audit logs, not post-incident reconstructions.
How do you enforce least privilege for autonomous AI agents?
Least privilege for AI agents cannot be written from static configuration — it must be derived from observed runtime behavior. Track which tools, APIs, and data sources the agent actually uses in normal operation, then build enforcement policies from those baselines. Applied incrementally, this constrains the agent to its operational scope without disrupting production workflows.


