
According to McKinsey's 2025 State of AI report, 78% of organizations used AI in at least one business function, yet only 21% had fundamentally redesigned workflows to account for new risks. Meanwhile, IBM's 2025 Cost of a Data Breach Report found that 97% of organizations reporting AI-related security incidents lacked proper AI access controls.
Unlike traditional applications, LLMs expose sensitive data through natural language outputs, manipulated prompts, and autonomous tool calls—channels conventional security stacks were never built to monitor. This guide covers what causes LLM data leakage, what's at stake, and how to stop it.
Key Takeaways
- LLM data leakage occurs across four distinct vectors: prompts, model outputs, RAG pipelines, and agentic tool calls
- Traditional DLP tools cannot parse unstructured prompts, paraphrased outputs, or agent-driven data flows
- Consequences range from GDPR and HIPAA penalties to IP theft and downstream attacks
- Prevention requires layered controls — input sanitization, scoped retrieval, output guardrails, and runtime enforcement
- Sustained control requires continuous monitoring, adversarial testing, and compliance-mapped audit trails
Common Causes of LLM Data Leakage
LLM data leakage is the unintended or unauthorized exposure of sensitive information (PII, credentials, proprietary IP, internal system details) through any phase of an LLM interaction: prompting, inference, retrieval, or autonomous agent action.
It rarely stems from a single failure — it arises from exploitable weaknesses distributed across multiple layers.
Prompt Injection and System Prompt Leakage
Adversaries craft malicious inputs to override system instructions, coercing the model into revealing sensitive context: database credentials, API keys, internal role descriptions, or filtering logic. OWASP ranks LLM01:2025 Prompt Injection as its top LLM risk, with System Prompt Leakage (LLM07) listed separately as a distinct threat.
Two common scenarios:
- A public-facing chatbot where a jailbreak-style query extracts the full system prompt
- An internal assistant with database access where a structured input surfaces user credentials
Model Memorization and Training Data Leakage
LLMs trained on datasets containing PII or proprietary records can reproduce near-verbatim training examples when prompted with partial matches. Carlini et al. extracted 604 unique verbatim training examples from GPT-2, including 78 PII examples (names, phone numbers, addresses) and 1,450 lines of verbatim source code from a single GitHub repository. Larger models memorize far more: GPT-2 XL memorized over 18x as much as its 124M-parameter counterpart.

The risk is concrete for enterprise use: an LLM fine-tuned on customer records could return an account number when prompted with a name.
RAG Pipeline Leakage
Retrieval-Augmented Generation systems ground LLM responses by pulling documents from internal knowledge bases. When retrieval permissions are not scoped at the document level, users or attackers can surface records they have no authorization to see simply by crafting queries that match sensitive content chunks.
Common exposure points include:
- Confidential merger documents surfaced by employees without authorization
- Restricted HR policies retrieved through unguarded similarity searches
- Customer records matched by partial-query injection against an unsegmented index
Agentic Tool Calls and Out-of-Scope API Access
Autonomous AI agents that make tool calls, query external APIs, or hand off tasks to sub-agents can exfiltrate data when their permissions exceed the scope of the original request. Research by Greshake et al. demonstrated that LLM-integrated applications blur the line between data and instructions, enabling remote exploitation through indirect prompt injection.
Two practical examples illustrate the exposure: an agent processing a malicious PDF that contains an injected instruction to forward CRM records to an external endpoint, and an agent granted broad API permissions that retrieves data well beyond the scope of what the original request required.
What Happens If LLM Data Leakage Is Ignored
Regulatory and Financial Exposure
GDPR, HIPAA, PCI DSS, and the EU AI Act all impose penalties for unauthorized exposure of personal or regulated data:
- GDPR Articles 32–34 require security of processing, supervisory-authority notification, and data-subject communication for high-risk breaches
- HIPAA Security Rule mandates technical safeguards protecting electronic PHI; the Privacy Rule governs how PHI can be used and disclosed
- EU AI Act Article 15 covers accuracy, robustness, and cybersecurity for high-risk AI systems
- PCI DSS issued 2025 guidance specifically on integrating AI into assessments while maintaining payment card security standards
IBM puts the global average breach cost at $4.4M in 2025. That figure doesn't include regulatory fines or litigation — both of which compound the exposure for organizations in regulated industries.
Longer-Term Business Damage
Regulatory penalties are recoverable. The competitive and reputational fallout often isn't:
- Exposed IP — trade secrets or source code handed to competitors create a lasting advantage that no fine can reverse
- Eroded customer trust — public disclosure triggers secondary attacks that exploit leaked information, accelerating the damage
- AI-specific reputational risk — incidents tied to AI deployments draw disproportionate scrutiny, given the pressure enterprises already face to demonstrate responsible AI use
Warning Signs You Are Already Experiencing LLM Data Leakage
Watch for these indicators:
- Unexpectedly specific outputs — the model returns system file paths, user tokens, API endpoints, or internal project codenames that were not part of the original query
- Retrieval anomalies — access logs show documents returned outside expected permission boundaries, or spikes in retrieval volume for sensitive document categories from specific sessions
- Adversarial prompt patterns — repeated role-playing instructions, "ignore previous instructions" queries, or structured inputs that probe the model's knowledge of its own configuration
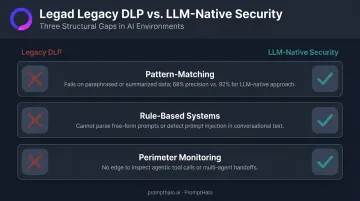
Why Traditional DLP Falls Short for LLMs
Legacy DLP tools were built to intercept structured data at defined perimeter points: email gateways, USB ports, cloud upload events. LLMs generate and expose data through language, inside inference pipelines, with no fixed perimeter to guard.
Three structural gaps make traditional DLP insufficient:
1. Pattern-matching can't catch paraphrased or summarized data A model can describe a customer's financial profile without triggering a single regex rule. A SafeGPT research baseline achieved only 68% precision with 24% false positives — compared to 92% precision and under 12% false positives for a purpose-built LLM security approach.
2. Rule-based systems can't parse free-form prompts A prompt injection attempt buried in conversational text looks nothing like an outbound file transfer — and rule-based systems have no framework for telling them apart.
3. Agentic pipelines have no edge to monitor When an AI agent exfiltrates data through a tool call or passes sensitive context during a multi-agent handoff, there's no outbound file to inspect. The leakage happens inside the inference layer — invisible to anything watching the network edge.
How to Prevent Data Leakage in LLMs
Effective LLM data leakage prevention requires multiple controls working together across every stage of the interaction lifecycle. No single tool covers the full attack surface — the controls below are designed to stack.
Input Sanitization and Prompt Filtering
Implement pre-inference filtering that validates and sanitizes all user inputs before they reach the model. This means detecting and redacting PII, credentials, API keys, and proprietary identifiers using pattern matching, contextual named entity recognition, and semantic risk scoring.
This intercepts prompt injection attempts and accidental employee data pasting at the earliest possible point — before sensitive content is ever transmitted to the model. Deploy it as the baseline at initial LLM rollout, before any LLM touches users or internal data sources.
Least-Privilege Access Controls and RAG Scoping
Apply role-based access control (RBAC) to all knowledge base retrieval. The RAG pipeline should only surface documents within the querying user's or agent's authorized permission scope — enforced at the retrieval layer, not just at the application layer.
A correctly scoped retrieval system cannot return restricted documents regardless of how the query is constructed. This is the primary defense against RAG pipeline leakage. Put it in place before connecting any LLM to an internal knowledge base, and apply it retroactively to existing RAG deployments that lack document-level permission enforcement.
Output Monitoring and Response Guardrails
Screen all LLM-generated responses for sensitive data patterns before output reaches the user. Semantic-level classifiers — not pattern-only rules — are required here to catch paraphrased or structurally transformed leakage.
This layer catches what input filters miss: model memorization leakage and policy-violating outputs that originate from training data rather than the user's prompt. It's critical for customer-facing deployments and any LLM trained on real user or organizational records. Run it in tandem with input controls from day one.
Runtime Enforcement Across Inference and Tool Calls
Deploy a real-time, inline security layer that intercepts every inference, tool call, and agent-to-agent handoff before execution. Each action gets an individual risk decision — allow, restrict, challenge, deny, or monitor — before it runs.
This covers the full agentic attack surface: autonomous tool calls, indirect prompt injection through retrieved documents, and multi-agent handoffs. These are vectors that perimeter-based tools and pattern matchers were never designed to see. PromptHalo's Runtime Security operates at this layer, making per-action decisions in under 100ms across any AI application from any vendor, without touching the underlying model.
This control is essential for agentic AI deployments, regulated environments (financial services, healthcare, legal), and any application where tool calls or external API access are in scope.

Tips for Long-Term Prevention and Control
Prevention is not a one-time deployment. These four practices determine whether controls hold over time:
1. Continuous monitoring with threshold-based alerting Track LLM access logs, retrieval patterns, tool call histories, and output anomalies in real time. Maintain decision-level, tamper-evident audit trails mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act to support regulatory reporting and incident reconstruction.
PromptHalo's audit logs are append-only and tamper-evident: once an event is written, it cannot be modified or removed, creating a replayable evidence trail for compliance export and post-incident investigation.
2. Periodic adversarial testing (LLM red-teaming) Identify exploitable data leakage paths before attackers do. Test prompt injection resilience, RAG permission boundaries, and agentic tool call scope across the full attack surface. NIST AI 600-1 recommends AI red-teaming specifically to assess training data extraction, model extraction, and membership inference risks.
3. Employee training on secure AI usage Train employees and LLM operators on what data categories should never appear in prompts, how to recognize potentially adversarial outputs, and how to report suspected leakage events. Most accidental leakage traces back to well-intentioned employees pasting sensitive data—PII, internal financials, or credentials—directly into chat interfaces.
4. Regular review of data classification and system prompts Update data classification policies and LLM system prompts to reflect changes in your data landscape, new regulatory requirements, and newly discovered attack patterns. Schedule quarterly reviews at minimum: new model versions, expanded tool integrations, and shifting regulatory guidance all create fresh exposure that static configurations won't catch.
Conclusion
LLM data leakage has identifiable causes—prompt injection, model memorization, RAG miscoping, and agentic tool abuse—and each is preventable with the right controls applied at the right layer.
Each of those attack vectors has a corresponding control layer. Input sanitization stops the most common attacks early; access controls contain retrieval risk; output guardrails catch what slips through; runtime enforcement closes the agentic gap that legacy DLP cannot see.
The organizations that close that gap fastest are the ones treating every inference, tool call, and agent handoff as an enforcement point — not a trust assumption. That's the operational shift PromptHalo is built around: red-teaming your AI to find exploitable paths before attackers do, then enforcing trust on every agent decision at runtime, across any model or vendor, without touching your underlying stack.
Frequently Asked Questions
What is LLM leakage?
LLM leakage is the unintended exposure of sensitive information—PII, credentials, proprietary data, or internal system details—through any LLM interaction channel, including prompts, model outputs, retrieval results, or autonomous agent actions. It can occur even when the underlying data itself remains intact and undamaged.
Is DLP obsolete?
Traditional DLP is not obsolete, but it's no longer sufficient on its own. Legacy tools can't handle unstructured prompts, semantic transformations, or agentic data flows, so modern AI deployments require LLM-specific runtime enforcement layered on top of existing DLP programs.
What is the difference between data leakage and data loss in LLMs?
Data loss means data becomes permanently unavailable through deletion or corruption. Data leakage means sensitive data is exposed to unauthorized parties—the underlying data stays intact, but the LLM's outputs or agent actions have disclosed it to someone who shouldn't see it.
Can prompt injection cause data leakage in LLMs?
Prompt injection is one of the most direct causes of LLM data leakage. Attackers craft inputs that override system instructions, coercing the model into revealing credentials, system architecture, or user data it was configured to protect. OWASP ranks it as the top LLM risk.
What types of sensitive data are most at risk from LLM leakage?
The highest-risk categories include:
- Personally identifiable information (PII)
- Authentication credentials and API keys
- Proprietary source code and intellectual property
- Internal business logic and system architecture
- Regulated data subject to GDPR, HIPAA, or PCI DSS
What regulations apply to LLM data leakage?
GDPR, HIPAA, PCI DSS, and the EU AI Act all have provisions triggered by LLM data leakage incidents involving personal, health, financial, or high-risk AI system data. Organizations must demonstrate controls and produce audit evidence—not just report incidents after they occur.


