
The problem isn't that employees are careless. It's that AI tools have become genuinely useful, productivity pressure is real, and most organizations haven't built the visibility or controls to keep up. Standard firewalls and DLP tools weren't designed to inspect inference calls or agent tool executions — so the leakage surface is largely invisible.
This guide covers the root causes of generative AI data leakage, how to monitor AI use across your organization, and the prevention measures that let teams keep using AI without creating compliance and legal liabilities.
Key Takeaways
- 39.7% of enterprise AI interactions involve sensitive data, making AI prompts a primary leakage channel that demands active monitoring
- Shadow AI accounts, not hacked networks, are the most common leakage path
- Traditional DLP tools cannot see inside inference calls, RAG retrievals, or agent-to-agent handoffs
- Effective prevention requires governance policies, least-privilege access, runtime enforcement, and enterprise-grade AI contracts together
- Tamper-evident, decision-level audit logs are increasingly required for regulatory compliance under GDPR, HIPAA, and the EU AI Act
What Causes Generative AI Data Leakage
AI data leakage rarely originates from an external network intrusion. It typically emerges from how employees interact with AI tools and how organizations configure — or fail to configure — AI systems. Four root causes account for the vast majority of incidents.
Shadow AI Usage by Employees
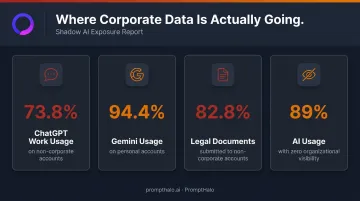
When employees face productivity pressure, they reach for the fastest tool available. That often means personal accounts on consumer AI platforms. Cyberhaven's 2024 analysis found 73.8% of ChatGPT usage at work occurred through non-corporate accounts. For Gemini, that figure was 94.4%.
The consequences compound quickly:
- 82.8% of legal documents entered into AI tools went to non-corporate accounts
- ~50% of source code submissions went to personal accounts
- ~55% of R&D materials went to non-corporate accounts
Consumer-tier accounts for most platforms default to using prompt history for model training — meaning corporate data can resurface in responses served to completely unrelated users. LayerX's 2025 Enterprise GenAI Security Report found organizations had zero visibility into 89% of AI usage.
Default Vendor Training Settings and Misconfigured Workspaces
Not all AI plans behave the same way:
| Account Type | Training Default |
|---|---|
| OpenAI ChatGPT Free/Plus/Pro | Data sharing enabled by default (user opt-out available) |
| OpenAI ChatGPT Enterprise/API | Not trained on by default |
| Anthropic Claude (consumer) | Permission-based (user opt-in) |
| Anthropic Claude Enterprise/API | Not trained on by default |
| Microsoft Copilot for M365 | Not used to train foundation LLMs |
| Google Gemini for Workspace | Not used to train without permission |
Organizations that deploy AI productivity tools at scale without reviewing these defaults — or without migrating users from free-tier to enterprise accounts — turn internal knowledge into model training material. Enterprise contracts reduce this risk, but they don't solve it on their own if most usage is happening through personal accounts anyway.
Over-Privileged AI Agents and Agentic Workflows
Autonomous AI agents introduce a leakage surface that's qualitatively different from standard AI tools. Unlike human employees, agents can process and transmit large volumes of data at machine speed with no human checkpoint.
The specific risk: an agent scoped to a marketing workflow but granted broad read permissions can inadvertently retrieve HR payroll records or confidential deal data. It then surfaces that information in a public-facing output — or passes it downstream to another agent with fewer guardrails.
OWASP LLM06:2025 (Excessive Agency) defines this formally as a vulnerability where LLM systems can perform damaging actions due to excessive functionality, permissions, or autonomy. The EchoLeak vulnerability, a zero-click prompt injection path in Microsoft 365 Copilot, demonstrated this in a production environment in 2025.
Prompt Injection Attacks and RAG Retrieval Vulnerabilities
Two technical vectors deserve specific attention:
Indirect prompt injection: A threat actor embeds malicious instructions inside an external document, email, or web page that an AI agent reads. When the agent processes the content, the hidden instruction overrides its guardrails, forcing it to exfiltrate sensitive data or API keys. Greshake et al. (2023) first demonstrated this attack class systematically; real-world variants have grown more targeted since.
RAG misconfiguration: When internal knowledge bases lack proper access controls, a low-privilege user can ask a cleverly framed question that causes an AI chatbot to surface restricted financial, HR, or legal data it was never authorized to return. This falls under OWASP LLM08:2025 (Vector and Embedding Weaknesses) and is a known architectural risk in any retrieval-augmented deployment.
What Happens When AI Data Leakage Goes Unchecked
The consequences span four distinct dimensions:
- IP and competitive loss — proprietary algorithms, product roadmaps, and source code exposed to competitors or embedded in vendor training data
- Regulatory exposure — unauthorized transfer of PII or PHI violates GDPR, HIPAA, and CCPA; the Italian data protection authority fined OpenAI €15 million in a ChatGPT investigation, and the EDPB has since established a dedicated ChatGPT task force
- Contractual and legal liability — NDA violations from client data entering unapproved AI tools, with legal counsel costs that dwarf proactive prevention budgets
- Remediation costs — forensic investigations, PR damage control, and mandatory audits; IBM's 2024 data breach analysis puts the average financial-sector breach at $6.08 million per incident

For financial services and regulated industries, the reputational risk is especially acute — client trust is core to the business model, not just a PR concern.
These costs don't announce themselves — they compound quietly until an incident forces the issue. Here are three signals your organization may already be exposed:
Warning Signs Your Organization May Already Have a Problem
- Employees on personal AI accounts — Corporate networks carry sessions IT can't see. With no visibility into what's being submitted, data classification rules can't be enforced on personal-tier sessions.
- Restricted data appearing in AI outputs — If AI-generated content includes information that should only exist in internal systems, RAG retrieval controls or agent access permissions are too permissive.
- No agent activity logs — If your organization can't answer "what data did this agent read, what tools did it call, and what did it output?" you have no basis for detecting or responding to a leakage event.
How to Monitor Generative AI Use Across Your Organization
You cannot enforce policies on AI interactions you cannot see. Effective monitoring needs to cover three distinct surfaces: employee-facing AI interactions, internal AI agent behavior, and data movement triggered by AI.
Map Your Total AI Footprint First
Before you can monitor anything, you need to know what's actually in use. An AI inventory audit should scan for:
- AI web applications accessed from corporate networks
- Browser extensions with AI capabilities
- IDE plugins (GitHub Copilot, Cursor, Tabnine)
- Local models running on employee devices
- API integrations built into internal applications
Once discovered, categorize tools by risk level: approved, under review, or blocked. This baseline determines your monitoring scope and access policies — and reveals the shadow AI problem in concrete terms rather than as an assumption.
Monitor Employee AI Interactions
At the employee layer, monitoring focuses on:
- Which AI applications are being accessed
- Whether sessions are through corporate or personal accounts
- What data classifications are present in file uploads submitted to external AI endpoints
The account distinction matters enormously. Enterprise contracts typically include zero data retention guarantees. Consumer accounts do not. An employee using their personal ChatGPT Plus account on a corporate device is operating completely outside your contractual protections, regardless of your enterprise subscription.
Monitor AI Agent Behavior, Tool Calls, and Handoffs
Agentic AI requires a monitoring surface that traditional tools weren't built for. Each autonomous tool call, API request, RAG retrieval, and context handoff between agents is a potential leakage event that happens at machine speed.
Effective agent monitoring logs:
- Each inference with its full inputs and outputs
- Tool invocations and the data each one accessed
- Data sources retrieved during RAG or retrieval steps
- Agent-to-agent handoffs with complete context preserved
- The full reasoning chain, reconstructable after any incident

Purpose-built solutions for this surface operate inline, making per-action decisions at machine speed. PromptHalo's runtime security layer, for example, evaluates each inference, tool call, and agent handoff in under 100ms — capturing the acting agent's identity, session context, and timestamp with each decision (allow, restrict, challenge, deny, or monitor) into an append-only audit trail.
Generate Decision-Level Audit Logs
There's a meaningful difference between basic access logs and decision-level audit trails. Access logs tell you what happened. Decision-level logs tell you:
- What data was involved
- What action the system took (allow, restrict, deny)
- Why that decision was made
- Which agent or user triggered it
This granularity is what makes logs usable for both incident response and regulatory reporting. For regulated industries, audit logs should be tamper-evident — append-only, unmodifiable once written — and mappable to frameworks including OWASP LLM Top 10, NIST AI RMF, and the EU AI Act's Article 12 record-keeping requirements. This is now a compliance expectation, not just a best practice.
How to Prevent Generative AI Data Leakage
Prevention is a layered strategy. No single measure is sufficient on its own. The four layers that matter are: governance policies, access control, runtime enforcement, and vendor management.
Establish a Practical AI Acceptable Use Policy
An effective policy must specify:
- Which platforms are approved vs. prohibited
- What data classifications are off-limits for AI prompts (source code, customer PII, unreleased financials, health records)
- Whether employees should use corporate accounts specifically
- What to do when AI assistance is needed with sensitive tasks
The policy fails if employees can't follow it without re-reading the full document. Make it actionable:
- Short reference guides by job function (a developer's guide looks different from a sales rep's)
- Browser notifications at the point of use — when someone navigates to a blocked AI tool, explain why and offer the approved alternative
- A clear escalation path for edge cases, so "I wasn't sure" doesn't become a leakage excuse
Enforce Least-Privilege Access for AI Systems and Agents
Apply identity and access management (IAM) and role-based access controls (RBAC) to AI agents with the same rigor applied to human users. An agent scoped to marketing workflows should never hold read permissions on HR or finance data, regardless of what it can technically reach.
For agentic workflows specifically, implement authority decay: permissions should be granted for the minimum scope needed for the current task and should expire or require re-authorization as context changes. This prevents privilege creep across multi-step operations, which becomes critical when agents chain tasks across extended sessions.
PromptHalo implements this through agent security passports — signed credentials with authority decay built in:
- Policy, budget, and scope constraints travel with every agent request
- Budgets decay across time, steps, and cumulative risk exposure
- When a budget envelope is exceeded, the system requires re-authorization rather than letting the agent continue on stale permissions
Deploy Runtime AI Security and Inline Enforcement
Traditional DLP tools monitor email, USB transfers, and cloud uploads. They were not built to intercept inference calls, tool invocations, or agent-to-agent context passing. A significant portion of the AI leakage surface is invisible to standard DLP.
Purpose-built runtime AI security operates at the AI layer itself, evaluating each prompt, retrieval, and output before it executes. Effective capabilities include:
- Inline prompt injection detection — catches adversarial instructions embedded in documents, emails, or web pages before they alter agent behavior
- RAG retrieval enforcement — prevents retrieved content from surfacing restricted data to unauthorized users
- Output inspection — blocks sensitive information from responses before they reach the user
- Per-action policy enforcement — granular decisions at the inference and tool-call level, not at the network perimeter
PromptHalo provides this kind of runtime enforcement across any AI application from any vendor, deploying in under a day with no model retraining required. Its ML-based detection achieves over 95% catch rate at under 5% false positives — compared to roughly 35% catch rate and 15-20% false positives for rule-based approaches.

Transition to Enterprise AI Subscriptions with Zero Data Retention
The simplest leakage vector — corporate data entering vendor training pipelines — is preventable with the right contracts. Enterprise agreements and dedicated API access typically guarantee that prompts, file uploads, and conversations are not used to train public models.
Implementation steps:
- Audit which AI tools are actively in use across the organization
- Identify which are running on personal or free-tier accounts
- Migrate those workflows to enterprise contracts or private-hosted deployments
- Verify contractual data protection guarantees before rollout, not after
This step eliminates the most common and preventable training-data exposure path. It does not address agent-layer or RAG risks — those require the runtime enforcement and access controls covered above.
Long-Term Control Strategies for AI Security
Protecting against AI data leakage isn't a one-time project. As tools evolve and new AI enters the organization, controls have to keep up. Four practices that hold up over time:
Quarterly AI security reviews — Reassess which tools are in use, whether access controls are still appropriately scoped, and whether new attack techniques require policy updates. Gartner found that organizations performing regular AI system assessments were over 3x more likely to achieve high GenAI value. Security rigor and business value aren't at odds.
Role-specific training, not just onboarding — Show employees real examples of how AI leakage happens. Practical prompt hygiene — knowing what not to paste into an AI tool — is trainable and reduces risk measurably.
Simulated log testing — Run periodic incident simulations to confirm your audit logs capture what they're supposed to. Log completeness is an assumption until you test it.
Alignment to recognized frameworks — Map controls to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act. Gaps get identified systematically, and compliance evidence stays audit-ready rather than assembled under pressure.
Frequently Asked Questions
What controls are recommended to prevent data leakage through generative AI applications?
The core control layers are: an AI acceptable use policy specifying approved platforms and prohibited data types, least-privilege access controls for both users and AI agents, real-time enforcement at the inference layer, and enterprise-grade AI subscriptions with contractual zero data retention guarantees. No single layer is sufficient — each addresses gaps the others leave exposed.
What are the key data privacy risks when using generative AI tools?
The primary risks are vendor training data ingestion, unauthorized submission of PII or PHI in violation of GDPR, HIPAA, or CCPA, and AI outputs surfacing restricted information from misconfigured retrieval systems. Shadow AI accounts amplify all three by bypassing enterprise contract protections.
Does standard DLP software protect against generative AI data leakage?
Traditional DLP tools monitor email, USB transfers, and file uploads — but weren't built to intercept inference calls, agent tool executions, or RAG retrievals. Without additional AI-specific controls operating at the inference layer, a significant portion of the AI leakage surface remains invisible to standard DLP deployments.
What is shadow AI and why does it create data leakage risk?
Shadow AI refers to unapproved, consumer-grade AI tools employees use without IT oversight. These tools typically lack enterprise data protection agreements and may use submitted data for model training — meaning corporate data submitted through personal accounts falls outside organizational controls, regardless of enterprise subscription status elsewhere.
How do AI agents increase data leakage risk compared to standard AI tools?
Agents operate autonomously across tool calls, file systems, APIs, and other agents — processing and transmitting data at machine speed with no human checkpoint. A misconfigured or compromised agent can exfiltrate far more data, far faster, than a human employee could, and without generating the behavioral signals that human activity would trigger.
What should be included in a generative AI acceptable use policy?
A complete policy covers approved and prohibited platforms, data classification rules (PII, source code, financial records, health data), guidance on enterprise versus personal accounts, and a reporting process for unsanctioned tool usage. It should be role-specific and actionable at the point of use — not a one-time onboarding document.


