Introduction
Enterprise AI agents have moved well past the chatbot phase. They now provision access, query databases, execute transactions, and orchestrate other agents — often completing entire workflows before a human reviews a single step.
That operational reality has outpaced the security controls designed to contain it. IAM systems were built assuming a human sits behind every authenticated request. DLP tools were built assuming a human decides to send data somewhere. AI agents violate both assumptions at once.
The result: bypass paths that appear fully authorized, generate no alerts, and leave audit trails too thin to support investigation.
Gartner forecasts that 33% of enterprise software applications will include agentic AI by 2028, up from less than 1% in 2024. They also predict 15% of day-to-day work decisions will be made autonomously by agents within that same window. This article breaks down exactly how agents slip past IAM and DLP controls, why existing tools fail to catch it, and what a purpose-built detection layer needs to address.
Key Takeaways
- AI agents authenticate under their own service account — user-level IAM restrictions don't apply when the agent executes the request
- Traditional DLP monitors human-initiated channels; agents exfiltrate through MCP tool arguments, WebSocket frames, and encoded payloads that DLP never reaches
- Prompt injection weaponizes both gaps at once, hijacking an agent's authorized tools to execute attacker instructions
- Audit logs attributed to an agent identity — not the requesting user — break compliance reporting and stall incident investigation
- Effective defense requires per-action enforcement at runtime, not just perimeter authentication checks
The Structural Reason AI Agents Bypass IAM
Agents Are Not User Accounts
Most enterprise agents are deployed as shared resources serving dozens of users, roles, and workflows from a single identity. Microsoft confirms that agent identities are specialized service principals representing software systems, not human beings. That distinction has a direct security consequence: when an agent authenticates to a downstream system, IAM evaluates the agent's credentials — not the credentials of whoever sent the request.
Agents typically hold broad permissions because they need to handle the full range of tasks any user might ask. That design choice is operationally reasonable. It is also the mechanism that creates the bypass.
The Identity Laundering Pattern
Consider a concrete example. A support analyst with read-only CRM access asks an agent to "pull the full account history for this customer." The agent holds broad CRM access because it serves the entire support organization. It returns the complete record. The analyst receives data they could never retrieve directly — and no policy was violated, because IAM evaluated the agent's credentials, not the analyst's.
This is identity laundering: the agent's broader permissions substitute for the requesting user's actual entitlements, invisibly.
How Multi-Agent Pipelines Compound the Problem
When agents call other agents — orchestrator dispatching to specialized subagents — each handoff can maintain or expand the active permission scope. The core problem:
- No native mechanism exists to decay authority down the chain
- Each subagent handoff inherits or widens the prior scope
- A request that starts with a narrow mandate can, by the fourth handoff, execute under credentials far broader than the original user warranted
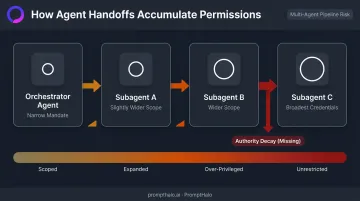
Authority decay — shrinking permissions at each handoff to match the minimum needed — is absent from most agentic frameworks by default.
OWASP's LLM06:2025 — Excessive Agency specifically names this risk: excessive permissions and excessive autonomy in LLM systems that call tools, functions, and plugins represent a documented and categorized threat, not a theoretical edge case.
Why Traditional IAM Controls Fail for Agentic AI
Standard IAM enforces permissions at authentication time, against whoever presents credentials. When an agent is the credential holder, three specific failures follow:
Attribution loss. Every action logs under the agent's service account. Security teams cannot determine which human user triggered a given action — making it impossible to enforce least privilege by user, detect misuse, or investigate anomalies.
No runtime intent verification. IAM grants or denies at the authentication boundary. It has no mechanism to evaluate whether an action the agent is about to take falls within what the requesting user was authorized to request. Once authenticated, what the agent does next is outside IAM's scope entirely.
Static credentials with no fast revocation path. Datadog reports that 59% of AWS IAM users have active access keys older than one year, and 40% of Microsoft Entra ID application credentials exceed one year in age. For autonomous systems that can complete a destructive sequence in seconds, a credential rotation cycle measured in days or weeks is not a meaningful control. By the time a compromised token is rotated, the agent may have already finished the destructive sequence.
How AI Agents Circumvent DLP Controls
What DLP Was Built to See
Traditional DLP was designed for a specific threat model: a human decides to send data somewhere, and that data moves through recognizable channels — email attachments, file uploads, USB transfers, known SaaS endpoints — in human-readable form. AI agents violate every one of those assumptions.
The Primary Exfiltration Channels
Elastic Security Labs documents multiple MCP-specific exfiltration paths that DLP tools weren't designed to inspect:
- HTTP request bodies and API parameters — sensitive data embedded in POST payloads through legitimate code paths, sometimes via prompt-injected instructions
- MCP tool call arguments — credentials or PII forwarded as JSON-RPC parameters to third-party MCP servers in context or sidenote fields
- Encoded payloads — Base64 and hex encoding used to obscure commands from keyword-based filters; DLP systems matching against plaintext patterns miss every encoded variant
- WebSocket frames — streaming exfiltration in small fragments; Zscaler notes that traditional tools see connections and domains but cannot inspect fragmented streaming payloads or multi-turn agent actions
- Tool response paths — a fetched document contains injected instructions that redirect the agent to exfiltrate through its next legitimate-looking tool call

Zscaler also documents a keyword DLP failure specific to agents: when sensitive content is paraphrased or spread across multiple conversation turns, pattern-matching fails. That failure mode connects directly to how prompt injection turns authorized agent capabilities into the exfiltration mechanism itself.
Prompt Injection as the Bridge Between IAM and DLP Failure
Microsoft MSRC documents how indirect prompt injection works: malicious instructions embedded in external content — a webpage the agent fetches, a document it reads, a tool response — are misinterpreted as valid commands. Microsoft MSRC documents how indirect prompt injection works: malicious instructions embedded in external content — a webpage the agent fetches, a document it reads, a tool response — are misinterpreted as valid commands. The agent then uses its legitimate, IAM-authorized tools to execute those instructions, exfiltrating data through channels DLP wasn't inspecting.
The credentials the agent holds are real. The tool calls it makes are authorized. Nothing in that chain looks like an attack to conventional controls.
Microsoft assigned CVE-2025-32711 to exactly this pattern in M365 Copilot. The attack required no user interaction. The agent's own authorized capabilities became the exfiltration mechanism.
The timing problem makes containment harder still. DLP was built for "block and notify" workflows that fit human-speed decisions. Agents make tool calls in milliseconds — effective protection must make an allow/deny decision inline, before the egress request completes, not after the data has already left.
The Compliance and Audit Trail Blind Spot
The same attribution gap that breaks IAM enforcement also breaks regulatory compliance. When every action logs under an agent's service account, organizations cannot produce user-level audit trails for GDPR data access requests, SOC 2 access reviews, or financial compliance investigations.
The data was accessed. The log cannot say by whom.
For incident response, this is worse than a gap. Investigators reconstructing a security event need to know who authorized what, in what sequence, and with what intent. Agent-mediated workflows collapse that chain. Multi-agent pipelines with several handoffs make reconstruction essentially impossible without decision-level logging at every step — and most current agent deployments don't produce it.
Regulatory frameworks are catching up to this exposure:
| Framework | Relevant Requirement |
|---|---|
| EU AI Act, Article 12 | High-risk AI systems must technically allow automatic event logging over the system's lifetime |
| EU AI Act, Article 19 | Providers must retain automatically generated logs for at least six months |
| NIST AI RMF, MEASURE 2.4 | AI system functionality and behavior must be monitored in production |
| NIST AI RMF, MANAGE 4.1 | Post-deployment monitoring plans must be implemented, including incident response |
| OWASP LLM06:2025 | Excessive Agency requires downstream authorization enforcement, not just LLM-level controls |
Each of these frameworks demands the same thing: evidence at the decision level, tied to user context. For organizations in fintech, healthcare, or critical infrastructure, the inability to produce that evidence isn't just an audit problem — it's a regulatory liability that accrues with every agent action that goes unattributed.
What Effective AI Agent Security Requires
Securing AI agents requires moving the enforcement boundary from the authentication perimeter to the per-action level. The agent's service account being valid is not sufficient. What matters is whether the specific action being taken falls within what the requesting user was actually authorized to trigger.
The required capabilities:
- Issue scoped, short-lived credentials with authority decay parameters — not broad persistent access
- Evaluate the requesting user's permissions against each specific action, not just the agent's credentials
- Prevent downstream agents from inheriting more access than the original request warranted
- Enforce DLP inline at the inference, tool call, and egress layer — not only at the network perimeter
- Capture user context, agent identity, action rationale, and timestamp in tamper-evident audit logs
PromptHalo is built specifically for this enforcement model. Its Runtime Security solution sits inline on every inference, tool call, and agent-to-agent handoff — making a per-action allow/restrict/challenge/deny decision in under 100ms.
The platform issues signed agent security passports that travel with each request and carry embedded policy, budget, and authority decay parameters, so agent authority diminishes across handoffs rather than accumulating.
Runtime enforcement covers prompt injection, data leakage, unauthorized tool and API calls, and agent-to-agent handoffs. The Red Teaming solution continuously attacks agents, RAG layers, and tool chains to surface exploitable paths, with discoveries fed into a shared Threat Library that trains the runtime detection engine. That closed-loop architecture means newly discovered attack patterns become runtime defenses without waiting for a release cycle.
The platform deploys in under a day via API gateway, agent mode, or inline middleware — no model retraining, no code rewrite, no access to the underlying model required.
Audit logs are append-only, tamper-evident, and structured for regulatory reporting aligned with OWASP LLM Top 10, NIST AI RMF, and the EU AI Act.
Frequently Asked Questions
What are the 4 pillars of AI agents?
The four pillars are perception (ingesting inputs), reasoning (LLM-driven planning), action (executing tool calls or API requests), and memory (retaining context across steps). For security teams, action and memory are the critical risk surfaces: action executes under the agent's credentials, and memory allows injected instructions to persist across conversation turns.
How do AI agents handle user permissions?
Most agents don't enforce user-level permissions at all. They authenticate using their own service account or API key and execute every request under that credential, regardless of who issued it. User-level permission enforcement only exists if the security team explicitly built per-user scope checks into the agent's design — which is uncommon in current enterprise deployments.
What are the top security pitfalls to avoid with AI agents?
The most consequential pitfalls include:
- Over-privileged agent credentials scoped to the broadest possible access
- Long-lived static API keys with no fast revocation path
- No per-action authorization checks against the requesting user's actual permissions
- Failure to inspect tool responses for injected instructions
- Agent logs that record only agent identity, with no user attribution
Can traditional DLP tools detect AI agent data exfiltration?
Traditional DLP cannot monitor agent exfiltration. It covers human-initiated channels like email and file upload, but does not inspect MCP tool call arguments or fragmented WebSocket payloads, lacks normalization to catch Base64 or hex-encoded data, and operates on block-and-notify workflows too slow to match agent execution speed.
How can organizations enforce least privilege for AI agents?
Start with scoped, short-lived credentials tied to specific task types — not broad service accounts. Enforce per-action authorization checks against the requesting user's actual permissions, and implement authority decay in multi-agent pipelines so downstream agents cannot inherit more access than the original request warranted. Provisioning-time controls aren't enough; continuous behavioral monitoring in production is required.