
Introduction
Most enterprises have written AI policies. Almost none of them are enforcing those policies where it matters—at the moment an agent takes an action, a prompt is processed, or a tool call executes.
The gap is not philosophical. According to IBM's 2025 Cost of a Data Breach Report, **97% of organizations that experienced AI-related breaches lacked proper access controls**, and shadow AI added an average of $670,000 to breach costs.
That exposure is only growing. Gartner forecasts that 40% of enterprise applications will include task-specific AI agents by end of 2026, up from less than 5% in 2025. The attack surface is expanding faster than most security teams can track.
This article focuses on the technical enforcement layer—not governance documentation, not frameworks, not acceptable use policies. Specifically, it covers:
- Why legacy tools fail at this problem
- What the agentic AI attack surface actually looks like
- What effective real-time enforcement architectures require
Key Takeaways
- AI policy enforcement translates written governance rules into runtime decisions — on every inference, tool call, and agent handoff
- Legacy DLP, firewalls, and SIEM tools cannot see, parse, or intercept agentic AI interactions
- Effective real-time enforcement spans prompt injection, jailbreaks, RAG poisoning, data leakage, and multi-agent handoff manipulation
- ML-based intent classification, per-action controls, and sub-100ms decision latency are non-negotiable for operational viability
- Decision-level, tamper-evident audit logs give regulators and security teams the evidence trail they require
What Is AI Policy Enforcement in Real Time?
AI policy enforcement is the operational machinery that translates governance rules into technical controls—evaluating every AI action at the moment it occurs, before it executes. A written policy defines intent; an enforcement engine acts on it, in production, on every request.
Governance vs. Enforcement: Not the Same Thing
Frameworks like NIST AI RMF, the EU AI Act, and internal acceptable use policies establish what is permitted. Enforcement is the mechanism that applies those rules in production, on every action, in real time. Without enforcement, policy is aspiration.
PromptHalo's Policy Enforcement Engine makes this concrete: a configurable runtime layer where enterprises define custom rules that flag, log, or block AI responses per action across AI workflows. Each decision—allow, restrict, challenge, deny, or monitor—is recorded with full context before the response is delivered.
That timing guarantee matters. Here's what "real time" actually requires in practice—and what separates inline enforcement from monitoring tools that observe after the fact.
What "Real Time" Actually Means
Inline enforcement decisions must happen before an agent executes a tool call, before a response is returned, before a retrieved result is injected into context. That means:
- Decisions measured in milliseconds, not seconds
- Enforcement sitting in the decision path, not observing from outside it
- Full protection without degrading user or agent experience
PromptHalo's Runtime Security solution makes per-action decisions in under 100ms, operating on input and output streams without touching the underlying model.
Why Legacy Security Tools Fail at AI Policy Enforcement
DLP, firewalls, and SIEM tools were built to inspect files, network packets, and static artifacts. That architecture made sense for the threats they were designed to catch. AI interactions are conversational, contextual, transient, and often encrypted within application layers — none of which those tools were built to handle.
The Visibility Gap
Legacy tools cannot inspect:
- What a user typed into an LLM prompt
- What context was retrieved from a RAG pipeline
- What parameters an agent passed to an external API
- What another agent returned during a multi-agent handoff
None of these interactions produce an inspectable artifact for traditional scanners to evaluate. By the time a legacy tool could act, the exchange is already gone.
The Context Problem
Even when a legacy tool detects an AI interaction, it cannot assess intent. A legal associate pasting contract clauses and a sales rep pasting a customer list into a prompt generator may trigger identical keyword patterns—but carry entirely different risk profiles. Without intent-based classification, enforcement either over-blocks legitimate work or under-blocks actual risk.
The Binary Enforcement Problem
Binary block-or-allow controls create constant friction. Most AI interactions exist on a risk spectrum: some are clearly safe, some clearly dangerous, and many fall in between — requiring a warning, a redirect, or a step-up challenge. Binary controls push employees toward unsanctioned tools.
The behavioral consequence is measurable. According to UpGuard's 2025 State of Shadow AI report, 81% of employees and 88% of security leaders reported using unapproved AI tools, and 45% of workers found workarounds to restricted applications. Restrictive enforcement doesn't eliminate shadow AI — it accelerates it.

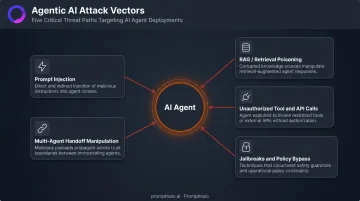
The Agentic AI Attack Surface
Agentic AI creates a fundamentally larger attack surface than human-AI chat tools. Autonomous agents make decisions, call external APIs, read from and write to datastores, spawn sub-agents, and execute multi-step workflows, often without any human in the loop. Each action is a potential enforcement point that legacy tools cannot see.
Prompt Injection
OWASP LLM01:2025 defines prompt injection as attacks where user prompts or external content the model processes alter LLM behavior in unintended ways. In agentic systems with broad tool access, a successful injection can trigger consequential real-world actions: emails sent, files deleted, APIs called.
PromptHalo's detection covers two injection paths, using embedding-based detection scored against a shared Threat Library rather than static rules:
- Direct injection: malicious user input that rewrites agent instructions mid-session
- Indirect injection: poisoned retrieved content carrying hidden instructions into the agent's context window
Retrieval Poisoning (RAG Manipulation)
OWASP LLM08:2025 maps vector and embedding weaknesses to harmful content injection and output manipulation through RAG systems. Adversarial content injected into a knowledge base causes the agent to surface false or policy-violating information as legitimate retrieved context.
This attack vector is invisible to tools that only inspect prompts and responses. It originates upstream, in the retrieval layer.
Unauthorized Tool and API Calls
OWASP LLM09:2025 identifies excessive agency as a core risk: agents performing damaging actions due to unexpected, ambiguous, or manipulated outputs, rooted in excessive functionality, permissions, or autonomy.
PromptHalo addresses this through external authority scoping per action: an agent cannot grant itself more access than it was originally authorized to have. Agent security passports carry policy, budget, and authority decay, forcing re-authorization when operational envelopes are exceeded.
Jailbreaks and Policy Bypass
Adversaries craft prompts designed to cause agents to override safety instructions, reveal system prompts, or produce policy-violating outputs. Jailbreak techniques evolve continuously; rule-based detection cannot keep pace with novel variations. ML-based classification catches behavioral intent rather than surface patterns, which is why PromptHalo's Septa enforcement engine applies trained models updated continuously through a shared Threat Library.
Multi-Agent Handoff Manipulation
In multi-agent architectures, one agent passes context, instructions, or partial results to another. An attacker who compromises an upstream agent can inject malicious instructions that propagate through the pipeline. Microsoft's AI Red Team taxonomy identifies this as agent compromise, injection, impersonation, and flow manipulation.
Enforcement must operate at each handoff point, not just at the user-facing input layer. PromptHalo sits inline on every agent-to-agent handoff, issuing signed security passports that travel with each request and applying authority decay across the entire workflow.
What Real-Time AI Policy Enforcement Actually Requires
Real-time AI policy enforcement fails when it treats all actions the same way. Effective enforcement needs two things working together: intelligence (classifying the intent behind an action) and granularity (applying the right policy to the right agent, role, or specific action). Drop either, and you get either too many blocked legitimate actions or too many threats that slip through.
ML-Based Intent Classification
Classifying behavioral intent at runtime — not matching keywords or static patterns — is the baseline requirement. PromptHalo's ML-based detection combines Threat Library signatures with classifier-based risk scoring, achieving a catch rate above 95% at under 5% false positives. Rule-based approaches, by contrast, land at roughly 35% catch rate with 15-20% false positives.
The closed-loop architecture compounds that advantage: red teaming encodes discovered attack patterns directly into the Threat Library, so newly identified techniques become runtime defenses without waiting for a release cycle.
Granular Per-Action Control
Session-level or application-level enforcement isn't granular enough for agentic systems. PromptHalo operates at the individual action layer through four mechanisms:
- Security passports — signed credentials encoding agent identity, authority level, and operational context
- Risk profiling — per-action risk assessment against configured thresholds
- Authority decay — budgets across time, steps, and risk that diminish as an agent operates, forcing re-authorization when envelopes are exceeded
- Scope enforcement — external authority scoping that prevents agents from granting themselves permissions beyond what they were issued
When an agent executes dozens of consequential actions per session, each one needs its own decision — not a blanket ruling on the session as a whole.
The Five-Outcome Decision Spectrum
Rather than block-or-allow, effective enforcement requires a multi-outcome model:
| Decision | When Applied |
|---|---|
| Allow | Low-risk action; proceed with logging |
| Restrict | Partial permission; limit scope of execution |
| Challenge | Require step-up confirmation before proceeding |
| Deny | High-risk action; block before execution |
| Monitor | Flag for security team review without blocking |
PromptHalo's Runtime Security solution delivers one of these five decisions per action in under 100ms — keeping legitimate workflows moving while blocking genuine threats before they execute.

Vendor and Model Agnosticism
That per-action decision framework only works if enforcement isn't locked to a specific model or vendor. Most enterprise deployments span multiple providers — and model-tied enforcement leaves gaps wherever it doesn't have native access.
PromptHalo sits at the action layer, monitoring input and output streams regardless of what's underneath. It deploys via API gateway, agent mode, or inline middleware, and works across any AI application from any provider — no model access, no retraining, no code rewrites required.
Turning Policy into Runtime Controls: Implementation Essentials
Define Machine-Readable Policies
Effective runtime enforcement starts by converting governance requirements into technical rules the enforcement engine can evaluate on every action. Policies should be layered:
- Organization-wide baselines (e.g., "no PII to external models")
- Team-level differentiation (e.g., legal team has broader document access)
- Individual-level exceptions where warranted
- Per-model controls for different risk profiles
PromptHalo's Policy Enforcement Engine lets enterprises encode these rules directly rather than relying on defaults, with each decision recorded for later review.
Deploy in Phases
Start with observe/monitor mode: flag violations without blocking. This validates detection accuracy and tunes false positive rates before enforcement takes consequential actions. Once detection confidence is high, you shift to active enforcement — reducing operational risk by not blocking actions until the system has proven itself against your real traffic patterns.
A phased approach gives security teams visibility before control, which matters when AI is embedded in production workflows.
Integration Requirements
Real-time enforcement must be inline—sitting in the decision path between the agent and its tools, APIs, and downstream agents. PromptHalo's three deployment paths all feed into the same inspection and enforcement pipeline:
- API gateway — intercepts requests between your application and external AI APIs
- Agent mode — connects with orchestration platforms and agent frameworks
- Inline middleware — embeds inside agentic frameworks and custom applications
All three paths deploy in under a day — no model retraining, no code rewrite required.
Compliance, Audit Trails, and Regulatory Alignment
Real-time enforcement and regulatory compliance are inseparable. Frameworks require organizations to demonstrate, not just claim, that AI systems operate within defined risk parameters.
- NIST AI 600-1 mandates continuous monitoring of generative AI system impacts, real-time monitoring processes for generated content, and post-deployment monitoring
- EU AI Act Articles 12, 14, and 72 require automatic event logging over system lifetime, effective human oversight capabilities, and post-market monitoring systems for high-risk AI
- OWASP LLM Top 10 (2025) maps LLM01, LLM06, and LLM08 directly to prompt injection, excessive agency, and vector/embedding weaknesses requiring runtime controls

Summary logs and session-level reports don't satisfy these requirements. Regulators need decision-level evidence.
What a Useful Audit Log Must Contain
Each enforcement decision log should capture:
- The enforcement outcome (allow, restrict, challenge, deny, monitor)
- The specific action evaluated
- The policy rule triggered
- The agent identity (via security passport)
- Session and tenant context
- Timestamp at decision time
PromptHalo's audit logs are append-only and tamper-evident—once written, events cannot be modified or removed. This creates a replayable evidence trail for debugging, compliance export, and post-incident investigation.
That same evidence trail has operational value beyond satisfying regulators. Security teams can replay enforcement decisions, trace attack paths across multi-step workflows, and identify how threats actually propagate through agentic systems—turning the audit log into a diagnostic tool for real incidents.
Frequently Asked Questions
What is AI policy enforcement?
AI policy enforcement is the technical layer that translates written governance rules into runtime controls, evaluating every AI action—prompt, inference, tool call, agent handoff—at the moment it occurs and determining whether to allow, restrict, or block it before execution. Unlike a governance document, enforcement operates inline and takes consequential action.
What are the six pillars of an AI policy?
Common AI policy pillars include permitted use cases, approved tools and models, data handling and classification rules, access controls by role, incident response procedures, and audit and accountability requirements. Real-time enforcement operationalizes all six at runtime, converting documented intent into technical controls applied per action.
How does real-time AI policy enforcement differ from DLP or firewalls?
Legacy tools were designed for file transfers, network packets, and static artifacts—not conversational AI interactions, agentic tool calls, or RAG retrievals. Real-time AI enforcement evaluates intent, context, and scope at the action layer, where DLP and firewalls have no visibility.
What specific threats does real-time enforcement protect against?
The primary threat categories are prompt injection (direct and indirect), jailbreaks, retrieval and RAG poisoning, unauthorized tool and API calls, data leakage, and multi-agent handoff manipulation.
How quickly must enforcement decisions be made?
Inline enforcement decisions must execute in milliseconds—under 100ms—to avoid degrading user experience or agent performance. This latency requirement is why ML-based detection, not human review or slow rule processing, must power the enforcement engine.
Does real-time enforcement require changes to underlying AI models?
No. Effective enforcement operates at the action layer, not the model layer—requiring no model retraining, no access to proprietary weights, and no code rewrites. PromptHalo deploys in under one day and works across any AI application from any vendor.


