GenAI risks live at the input/output boundary: what goes into the model and what comes out. Agentic AI risks live at the execution layer: what the agent does—autonomously, at machine speed, across APIs, databases, and other agents.
Treating agentic AI as "just more GenAI, but faster" is the security mistake most likely to result in a real-world incident. This article breaks down each paradigm's threat surface, compares them directly, and outlines what security and compliance teams need to prioritize before expanding deployments in regulated environments.
Key Takeaways
- GenAI risks center on data leakage through prompts, hallucinations influencing decisions, and IP/regulatory exposure in outputs
- Agentic AI adds an execution-layer attack surface—prompt injection, RAG poisoning, unauthorized tool calls, and multi-agent hijacking—that GenAI controls don't cover
- Firewalls, DLP, and code scanners cannot inspect autonomous reasoning chains or tool call sequences
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act apply to both—but agentic deployments also require runtime enforcement at the decision level
- Security teams must classify AI deployments by type and apply the right control model before granting production access
Agentic AI vs. Generative AI: Quick Security Comparison
| Dimension | Generative AI | Agentic AI |
|---|---|---|
| Primary Function | Generates content from prompts | Executes multi-step tasks and tool calls autonomously |
| Decision Autonomy | Reactive—requires human prompt | Goal-directed—acts independently across steps |
| Attack Surface Breadth | Input/output boundary | Execution layer: APIs, databases, code, other agents |
| Top Security Threats | Data leakage, hallucinations, jailbreaks, IP exposure | Prompt injection, RAG poisoning, unauthorized tool calls, agent hijacking |
| Human Oversight Required | Per-prompt | Per-workflow or per-action (real-time enforcement) |
| Compliance Complexity | Input/output data handling | Decision-level audit trails, action authorization, tool-call logging |
| Runtime Enforcement Needed | Prompt filtering, output scanning | Inline decision enforcement at every inference and tool call |

Note: This comparison assumes a production deployment context. Development and sandbox environments carry different risk profiles and may require less restrictive controls.
What Is Generative AI? Security Profile and Risks
Generative AI refers to LLM-based systems—ChatGPT, Claude, Gemini, and their enterprise equivalents—that produce text, code, images, or audio in response to a prompt. The model is reactive: it requires a human trigger and does not independently call external systems or execute actions. Input (the prompt) and output (the response) are the two surfaces where security controls apply.
Enterprise Use Cases
GenAI is now standard infrastructure across large organizations. Common deployments include:
- Content generation for marketing, documentation, and internal communications
- Code assistance and automated code review
- Customer-facing chatbots and virtual assistants
- Document summarization for legal, compliance, and research functions
- Data analysis and reporting with natural language interfaces
According to Gartner, more than 80% of enterprises will have used GenAI APIs or deployed GenAI-enabled applications by 2026, up from less than 5% in 2023. GenAI risk is a mainstream enterprise security problem security teams are managing now.
Security Risks of Generative AI
The four primary GenAI threat categories security teams need to address:
Sensitive data leakage via prompts — Users paste confidential information into third-party models. Samsung's ban after employees submitted proprietary source code and internal meeting notes to ChatGPT is the clearest precedent. Security teams must treat prompts as regulated data flows.
Hallucinations influencing decisions — GenAI generates false but confident outputs. Air Canada was held liable after its chatbot gave incorrect bereavement-fare information and a tribunal ordered compensation — a precedent with direct implications for any enterprise deploying GenAI in customer-facing or advisory roles.
Jailbreaking and prompt manipulation — OWASP LLM01 defines prompt injection as user prompts altering model behavior in unintended ways, including instructions invisible to humans but parsed by the model. Most content guardrails are brittle against creative manipulation and offer no reliable defense against indirect injection.
IP and regulatory exposure in outputs — Model-generated content may reproduce training data, creating copyright risk. Prompts containing personal or regulated data may be retained for model training, triggering GDPR, HIPAA, and CCPA obligations depending on what employees submit.

One boundary worth holding: GenAI does not independently call APIs, execute transactions, or chain multi-step workflows. Those capabilities — and the risks that come with them — are specific to agentic systems.
What Is Agentic AI? Security Profile and Risks
Agentic AI goes beyond content generation to autonomous, goal-directed action. These systems perceive their environment, plan multi-step responses, call external tools and APIs, coordinate with other agents, and execute real-world actions—all with minimal human intervention.
The architecture matters for security teams: an agentic system uses an LLM as a reasoning engine, combined with tool access (APIs, databases, code execution environments), memory (short- and long-term), and often a multi-agent orchestration layer. Each component is a potential attack vector.
Enterprise Use Cases
The fastest agentic AI adoption is in regulated industries:
- Autonomous financial transaction processing and fraud triage
- Multi-step compliance workflows with database read/write access
- AI-driven customer service that executes account changes in real time
- RAG-powered research agents querying live internal knowledge bases
- Software development agents with code execution and repository permissions
Gartner projects that 33% of enterprise software applications will include agentic AI by 2028, up from less than 1% in 2024, with at least 15% of day-to-day work decisions made autonomously by that date. The security controls enterprises deploy today will govern a much larger autonomous decision surface in three years.
Security Risks of Agentic AI
Prompt Injection via External Data
This is agentic AI's most dangerous and hardest-to-detect attack. Malicious instructions are embedded in external content an agent retrieves—emails, documents, web pages, tool results—and the agent acts on those instructions using its own legitimate permissions. No credential theft required.
Research from Greshake et al. showed that blurring the boundary between data and instructions is enough to compromise LLM-integrated applications at scale. The AgentDojo benchmark confirmed this across 97 realistic tasks and 629 security test cases spanning email, e-banking, and travel-booking workflows—environments where enterprise agentic deployments already operate.
RAG Poisoning
When agents retrieve information from knowledge bases to augment their responses, a poisoned corpus becomes a reliable manipulation channel. PoisonedRAG research found that injecting just five malicious texts into a RAG knowledge database produced a 90% attack success rate for target questions. RAG security depends on corpus integrity, not model safety.
Unauthorized Tool and API Calls
OWASP LLM06 (Excessive Agency) defines the risk: LLM systems granted extensions, tools, plugins, or agents can perform damaging actions when given excessive functionality, permissions, or autonomy. Agents sending emails they weren't authorized to send, modifying records outside their scope, or initiating payments without approval all fall under this category.
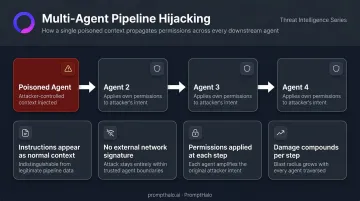
Multi-Agent Handoff Vulnerabilities
In a multi-agent pipeline, context and instructions pass from one agent to the next. A single poisoned agent can corrupt every downstream agent in the chain. Compromised instructions at handoff points don't trigger external alarms—the pipeline continues executing with the attacker's intent embedded in legitimate agent-to-agent communication.
The attack characteristics that make this especially difficult to contain:
- Instructions appear as normal inter-agent context, not external input
- No external network signature for perimeter tools to detect
- Each downstream agent applies its own permissions to the attacker's intent
- Damage compounds with each step in the pipeline
Agent Hijacking
If an attacker compromises the credentials an agentic system uses to authenticate its tools—API keys, OAuth tokens, service accounts—they gain an autonomous insider that can execute lateral movement and data exfiltration without issuing further external commands. The agent acts as the attacker's proxy, using its own legitimate authority.
A compromised agent doesn't wait. Unlike human-executed attacks, it can execute thousands of actions in seconds—file reads, API calls, data writes—before a monitoring alert fires. Reviewing logs after the fact doesn't undo those actions. Enforcement has to happen at the decision layer, before each action runs, not after.
Which Poses Greater Security Risk—and What to Do About It
The right question isn't which is more dangerous in the abstract. It's which control model matches the deployment's actual capabilities.
- GenAI-only deployments (content generation, summarization, assistive tooling with no external system access): Apply data-boundary controls—prompt filtering, output scanning, data classification at the model boundary.
- Agentic deployments (any system that calls APIs, executes code, retrieves from live databases, or coordinates sub-agents): Require runtime enforcement at the decision and action level before production access, especially where regulated data or financial transactions are involved.
Security Implications in Regulated Environments
Agentic AI in fintech, payments, and healthcare compounds compliance exposure in a way GenAI does not. Autonomous agent actions must be auditable, tamper-evident, and traceable to specific decisions to satisfy OWASP LLM Top 10, NIST AI RMF, and the EU AI Act's high-risk AI system obligations.
GenAI deployments in the same industries face input/output data handling requirements but generally do not require decision-level audit trails.
Illustrative risk scenario: A financial services AI agent processes loan applications autonomously, retrieving policy documents from an internal knowledge base. An attacker has poisoned one document with an embedded instruction. When the agent retrieves it, the instruction is interpreted as authoritative—triggering an out-of-scope action: accessing records beyond its intended scope or modifying application status in violation of policy.
No external credentials were stolen. No network anomaly fired. The agent used its own legitimate permissions, and the damage was done before any human reviewer could intervene.
This scenario maps directly to documented attack patterns in AgentDojo's e-banking workflows and PoisonedRAG's corpus manipulation research.
What Security Teams Should Do Now
Step 1: Inventory AI Applications by Type
Classify every AI deployment as GenAI or agentic, then map what external systems each can access. The classification determines the control model. A summarization tool with no external system access is a different risk object than a compliance agent with database read/write permissions and email-sending authority.
Step 2: Apply the Right Control Framework
| Deployment Type | Control Model |
|---|---|
| GenAI (no external access) | Data classification, prompt filtering, output scanning, DLP at the model boundary |
| Agentic (any external access) | Runtime decision enforcement, tool-call authorization, authority decay, tamper-evident action logs |
Step 3: Map to Compliance Frameworks Before Expanding
Before any agentic deployment moves to production in a regulated environment, security teams should validate against:
- OWASP LLM Top 10 — Attack taxonomy covering prompt injection, excessive agency, vector/embedding weaknesses, and sensitive information disclosure
- NIST AI RMF 1.0 — Govern, Map, Measure, Manage structure for enterprise AI risk programs
- EU AI Act (Regulation 2024/1689) — Logging, human oversight, and risk management obligations for high-risk AI system contexts

Step 4: Acknowledge What Traditional Tools Cannot See
Firewalls inspect network traffic. DLP systems inspect files and data streams. Code scanners inspect static code. None of these was built to inspect autonomous reasoning chains, tool call sequences, or agent-to-agent handoffs.
The Samsung incident shows prompt leakage slipping past existing controls. OWASP LLM01 and LLM06 describe attack patterns that operate entirely within the inference and action layer — invisible to network-layer controls.
Runtime enforcement at the agent decision layer is the gap most enterprise security stacks have not closed yet. PromptHalo addresses this directly: enforcing trust on every agent action across tool calls, RAG retrieval, and multi-agent handoffs, without model retraining or code rewrites. Security passports, authority decay, and per-action scope enforcement ensure that compromised credentials cannot sustain persistent access.
Step 5: Require Decision-Level Audit Logs
Any agentic AI system in production should produce evidence-grade, tamper-evident audit logs at the decision level—capturing the action taken, the reasoning, the agent identity, session context, and timestamp. These logs must be append-only and mappable to regulatory frameworks to support incident response and regulatory reporting.
Conclusion
GenAI and agentic AI are not competing technologies. They are different layers of the same enterprise AI stack, each with a distinct risk profile that demands a distinct security posture.
Security teams that treat agentic AI as GenAI with more permissions will find their controls inadequate at the moments it matters most: when an agent executes an unauthorized transaction, exfiltrates data through a poisoned RAG pipeline, or passes compromised instructions down a multi-agent workflow.
As agentic deployments accelerate in regulated industries, the risk of a misconfigured or compromised agent causing real-world harm grows proportionally. Getting the control model right before scaling means your security posture grows with your AI deployment — not behind it.
See how PromptHalo enforces trust on every agent action at runtime — across any AI application, from any vendor. Explore PromptHalo
Frequently Asked Questions
Is there any difference between agentic AI and generative AI?
Generative AI creates content reactively in response to prompts—it requires a human trigger and does not independently take actions. Agentic AI acts autonomously to execute multi-step goals, calling tools, making decisions, and taking real-world actions without constant human direction. The key difference is agency: one generates, the other acts.
What are the biggest security risks of agentic AI compared to generative AI?
Agentic AI introduces a distinct attack surface—prompt injection via external data, RAG retrieval poisoning, unauthorized tool and API calls, and multi-agent pipeline hijacking. These risks don't exist in GenAI-only deployments, and traditional security controls were not designed to detect them.
What is prompt injection and why is it especially dangerous in agentic AI?
Prompt injection embeds malicious instructions in content an agent retrieves—emails, documents, web pages—causing the agent to execute those instructions using its own legitimate permissions. No credential theft is required, the attack leaves no obvious external signature, and it is one of the hardest agentic AI threats to detect and block without inline runtime enforcement.
Can generative AI and agentic AI be deployed together securely?
Yes—GenAI frequently serves as the reasoning engine inside an agentic system. But security controls must match the deployment's actual capabilities. As soon as a system can take external actions, agentic-specific runtime enforcement becomes mandatory, regardless of whether the underlying model is the same.
What compliance frameworks apply to agentic AI security?
The three primary frameworks are OWASP LLM Top 10 (attack taxonomy), NIST AI RMF (risk management structure), and the EU AI Act (logging and human oversight obligations)—most regulated-industry deployments need to satisfy all three, backed by decision-level audit trails.
How do I know if my current security stack can protect an agentic AI deployment?
Firewalls, DLP, and code scanners operate at the network and static-code layer—they cannot inspect autonomous reasoning chains, tool call sequences, or agent-to-agent handoffs. Protecting agentic deployments requires purpose-built runtime enforcement inline at the inference and action layer, where agentic threats actually occur.


