Introduction
Generative AI is no longer a pilot program sitting in a sandbox. It's embedded in financial workflows, customer-facing applications, code pipelines, and legal processes—making real decisions, executing real actions, and touching sensitive data at scale. The security perimeter built around deterministic software was never designed to handle any of it.
The stakes are concrete: Gartner projects that by 2027, more than 40% of AI-related data breaches will stem from improper cross-border GenAI use. Organizations deploying AI without dedicated security controls aren't just accepting technical risk—they're accepting regulatory and business exposure they may not yet be able to quantify.
This guide defines generative AI security, breaks down the most consequential threats, makes the case for why adoption is unavoidable, and provides actionable best practices and a runtime enforcement model for agentic AI deployments.
Key Takeaways
- Prompt injection, retrieval poisoning, and rogue agent behavior bypass firewalls, DLP tools, and code scanners entirely
- The attack surface extends to RAG pipelines, multi-agent handoffs, tool calls, and ungoverned shadow AI
- Pre-deployment red-teaming and runtime enforcement are both required — neither alone is sufficient
- Agentic AI is the fastest-growing and highest-risk attack surface, demanding purpose-built controls
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act define what documented AI governance must demonstrate
What Is Generative AI Security?
Generative AI security is the practice of protecting LLM-based systems—their inputs, outputs, retrieved data, and downstream autonomous actions—from misuse, manipulation, and unintended behavior. This covers both enterprise use of third-party AI services like ChatGPT and Microsoft Copilot, and internally developed AI applications and agents.
The distinction from traditional application security matters. AppSec validates code and infrastructure. GenAI security must also govern what a model is instructed to do at the prompt layer, what data it retrieves, and what real-world actions it can execute autonomously. Firewalls, endpoint agents, and static code analysis cannot inspect any of those layers.
McKinsey's 2024 Global Survey found 65% of organizations were regularly using GenAI—nearly double the prior year—with overall AI adoption reaching 72%. GenAI is fully operational at enterprise scale, and the attack surface has expanded faster than most security programs can track.
That expanded surface maps to three distinct layers, each exposing risks that traditional security tools were never built to address:
- Prompt layer — what users and systems instruct the model to do
- Retrieval layer — what data the model pulls from knowledge bases, documents, and APIs
- Action layer — what the model executes autonomously through tool calls and agent handoffs

Major Generative AI Security Risks and Threats
Prompt Injection and Jailbreaks
Prompt injection is classified as LLM01:2025 in the OWASP Top 10 for LLM Applications. The attack works by crafting inputs that override a model's system instructions—causing it to leak data, ignore safety policies, or execute unauthorized commands.
Two variants:
- Direct prompt injection — malicious input from a user interacting with the model
- Indirect prompt injection — adversarial content embedded in documents, emails, or web pages that an agent retrieves and processes, without recognizing the content as weaponized
A real-world example: EchoLeak (CVE-2025-32711) was a zero-click prompt injection exploit in Microsoft 365 Copilot that enabled remote, unauthenticated data exfiltration through a crafted email. No user action was required beyond receiving it.
Jailbreaks are related but distinct: carefully engineered prompts that exploit a model's own reasoning patterns to bypass safety guardrails. Rule-based filters can't catch either attack type, because both exploit language understanding rather than syntactic signatures — which means detection has to happen at the semantic layer, not the perimeter.
Data Leakage and Sensitive Information Disclosure
LLMs can surface confidential data through overfitting to training data, over-permissive retrieval in RAG pipelines, or insufficient output filtering. A user asking a cleverly framed question may receive another employee's salary data, internal legal documents, or API credentials. In most cases, the model wasn't hacked. Access controls were simply never enforced at the retrieval or response layer.
IBM found that 97% of organizations that experienced AI model breaches lacked proper AI access controls. Separately, Netskope reported that proprietary source code accounted for 46% of all data policy violations involving GenAI applications.
Retrieval Poisoning and AI Supply Chain Vulnerabilities
Two related threats operate below the application layer, where most security controls don't reach:
- Retrieval poisoning: When an agent pulls documents from an external knowledge base, adversarial content embedded in those documents can hijack its reasoning and actions. This is indirect prompt injection at the data layer. Research under PoisonedRAG showed that injecting a small number of poisoned texts into a knowledge base is enough to manipulate generated answers at scale.
- Supply chain backdoors: Open-source model checkpoints and third-party datasets can carry malicious payloads before a single line of custom code is written. JFrog Security Research identified models on Hugging Face — including a PyTorch model that executed a payload on load — creating a silent backdoor in any environment that imported it. Vulnerabilities inherited from model provenance are invisible to application-layer controls.
Rogue Agent Behavior and Out-of-Scope Tool Calls
Single-turn LLM interactions carry limited autonomous risk. Agentic AI is a different threat category entirely. Agents chain tool calls, query databases, access external APIs, hand off tasks to other agents, and complete multi-step workflows, often without human checkpoints at each step.
Gartner predicts that 40% of enterprise applications will feature task-specific AI agents by end of 2026, up from less than 5% in 2025. Without per-action scope enforcement, a compromised or over-permissioned agent can exfiltrate data, modify records, trigger financial transactions, or pivot across systems in ways that are invisible to network or endpoint monitoring.
Shadow AI and Compliance Exposure
Shadow AI is one of the fastest-growing compliance risks in enterprise security. Employees using unauthorized, free-tier, or ungoverned AI tools pass client records, financial models, source code, and PII to services outside organizational control and outside data processing agreements.
Recent research puts the exposure in concrete terms:
- 78% of AI users bring their own AI tools to work, per Microsoft and LinkedIn research
- 83% of European IT professionals believed employees were using AI, while only 31% of organizations had a formal, comprehensive AI policy (ISACA)
- Shadow AI was responsible for breaches in 20% of organizations and added an average $670,000 to breach costs, per IBM's 2025 Cost of a Data Breach Report

Every unauthorized AI tool interaction is a potential GDPR, CCPA, or HIPAA violation — and a data residency risk that grows with every new user.
The Business Case for Generative AI Despite the Risks
Security teams do not get to veto AI adoption. The business has already decided. The correct question is how to govern it safely.
The productivity case is real. McKinsey estimates GenAI could add $2.6 to $4.4 trillion annually across analyzed use cases. An NBER working paper found a GenAI assistant increased customer-support agent productivity by 14% on average, with larger gains for less-experienced workers.
That advantage cuts both ways. Organizations using security AI and automation extensively saw measurably better breach outcomes:
| Metric | Extensive AI Use | No AI Use |
|---|---|---|
| Average breach cost | $3.84M | $5.72M |
| Breach lifecycle | 194 days | 292 days |
| Prevention workflow savings | $2.22M saved | — |
Source: IBM Cost of a Data Breach Report 2024
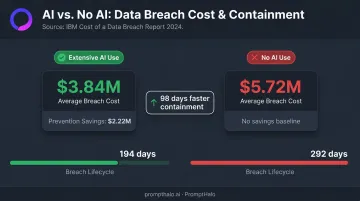
Those cost gaps are a function of speed. Security teams using AI-powered anomaly detection, behavioral analysis, and automated response contain breaches nearly 100 days faster than teams relying on manual workflows. Adversaries using AI-powered phishing, malware generation, and social engineering are not waiting. Refusing AI adoption hands them that speed advantage while doing nothing to shrink the attack surface.
Generative AI Security Best Practices
Enforce Least Privilege on AI Agents and RAG Pipelines
Every agent and retrieval pipeline should operate under the minimum permissions required for its defined task. Before an agent calls an external tool, queries a database, or retrieves a document, an authorization check should verify that the action is within scope—and reject anything outside that boundary.
This matters because a compromised or jailbroken agent becomes a pivot point. If it holds credentials to five systems, it can touch five systems. Scope enforcement at the action level limits blast radius regardless of how the compromise occurs.
Implement Runtime Input and Output Guardrails
Deploy inline inspection on every inference:
- Inputs — validate and scan for prompt injection patterns, encoded payloads, and jailbreak attempts before the model processes them
- Outputs — filter to detect sensitive data disclosure, policy violations, and off-topic responses before they reach users or downstream systems
Guardrails must operate at sub-100ms latency to avoid degrading user experience in production. Inspection that runs after the response has been delivered is not enforcement—it's logging.
Red-Team AI Systems Before Deployment
Structured adversarial testing against LLMs and agentic workflows before production reveals structural vulnerabilities in a controlled environment. Effective red-teaming probes for prompt injection, jailbreak scenarios, data extraction, and tool misuse across multi-step, multi-agent workflows.
Pre-deployment testing is necessary but not sufficient. It cannot anticipate every adversarial input that emerges in real-world use. Runtime enforcement must follow—without it, red-teaming only validates what was true at the time of the test, not what your AI faces in production.
Maintain an AI Inventory and AI Bill of Materials
Without a living inventory of every AI model, third-party API integration, RAG data source, agent, and AI-enabled SaaS application—including shadow AI tools—security teams cannot assess exposure, attribute incidents, or meet compliance obligations.
An AI Bill of Materials (AI-BOM) should capture:
- Model provenance and version
- Training data sources
- Access relationships and permissions
- Third-party dependencies
CISA and partners published minimum-elements guidance for AI-BOMs in November 2023, covering data provenance, training taxonomies, and model architecture details—a baseline worth mapping your inventory against as regulatory expectations continue to tighten.
Map Controls to Regulatory Frameworks and Maintain Audit Trails
Align controls to established frameworks:
- OWASP LLM Top 10 — taxonomy of LLM-specific vulnerabilities (prompt injection, sensitive disclosure, supply chain, excessive agency, vector/embedding weaknesses)
- NIST AI RMF — governance structure with Govern, Map, Measure, and Manage functions
- EU AI Act — mandatory risk classification, technical documentation (Article 11), logging (Article 12), and conformity assessment (Article 43) for high-risk AI applications. Fully applicable August 2, 2026.
Implement decision-level audit logging that captures every inference, tool call, and agent action with enough context for regulatory reporting, forensic investigation, and incident replay. Application logs that lack AI-specific context will not satisfy regulatory scrutiny.
Govern Employee AI Usage with Clear Acceptable Use Policies
Establish and communicate which AI tools are approved, what data categories may be used in prompts, and how outputs should be reviewed before use. Without technical controls backing them, usage policies function as guidance documents—not guardrails.
Pair usage guidelines with controls that detect and alert on policy violations in real time. At minimum, your policy framework should cover:
- Which AI tools are sanctioned for internal use
- What data classifications are permitted in prompts
- How outputs must be reviewed before acting on them
- How violations are reported and escalated
Training should run on the same cadence as your threat model updates—because the attack techniques targeting your employees' AI usage are not standing still.
Securing Agentic AI at Runtime: Why the Stakes Are Higher
Autonomous agents don't wait for human approval at each step. They reason over retrieved context, invoke external tools, hand off tasks to other agents, and complete multi-step workflows in real time. The attack surface spans every inference, every retrieval call, every tool invocation, and every handoff across a pipeline that may run dozens of actions deep.
Traditional perimeter controls, DLP systems, and application firewalls cannot inspect these behaviors. They were designed for deterministic software, not probabilistic reasoning systems that change their behavior based on retrieved context.
What Effective Agentic Security Requires
Effective agentic AI security requires inline protection that intercepts and evaluates every agent action before it executes—not after. That means:
- Per-action authorization decisions that allow, restrict, challenge, deny, or monitor each tool call and agent-to-agent handoff
- ML-based detection capable of recognizing novel attack patterns, not just rules attackers have already learned to evade
- Sub-100ms enforcement, fast enough to operate in production without degrading user experience
- Decision-level audit records — tamper-evident, mapped to compliance frameworks, supporting both incident response and regulatory reporting
How PromptHalo Addresses This Problem
Each of those requirements maps directly to what PromptHalo is built to deliver. Its red-teaming capability probes AI systems for exploitable attack paths across autonomous tool calls, RAG retrieval, and multi-agent handoffs — the surface that firewalls, DLP, and code scanners were never designed to see. Its runtime enforcement engine then applies inline protection on every agent action, with ML-based detection achieving a catch rate above 95% at under 5% false positives.
Deployment takes under a day with no model retraining and no code rewrite. Operating at the application layer rather than the model layer, PromptHalo supports three integration paths — API gateway, agent mode, and inline middleware — all feeding into the same inspection and enforcement pipeline.
For agentic environments specifically, PromptHalo issues agent security passports—signed credentials with policy, budget, and authority decay built in—so that agent permissions don't persist indefinitely. As an agent operates, its authority decays across time, steps, and risk, forcing re-authorization when a threshold is exceeded. This enforces least privilege dynamically, not just at initialization.
The Closed-Loop Advantage
When a red-teaming engine and a runtime enforcement engine share a threat library, every attack discovered in testing improves production detection capability. PromptHalo encodes red-teaming discoveries directly into its shared Threat Library, so a newly identified attack pattern becomes a runtime defense without waiting for a new release cycle.
Protection compounds over time. Static, signature-based approaches degrade as attackers adapt — each evasion becomes a blind spot. In a closed-loop model, each discovered attack strengthens the next line of defense rather than exposing a gap in it.
Frequently Asked Questions
What are the top generative AI platforms for security teams?
The main categories are AI-SPM tools for cloud asset governance, LLM runtime guardrail platforms for prompt-layer protection, agentic security enforcement platforms, and automated red-teaming frameworks. The right fit depends on whether your priority is asset discovery, inference-time protection, or agentic runtime enforcement.
How can security teams use generative AI to improve their security posture?
Security teams can apply AI to automate threat detection and alert triage, accelerate incident investigation and summarization, identify anomalous user and agent behavior faster than manual analysis allows, and continuously red-team their own AI deployments to surface exploitable attack paths before adversaries find them.
What are the major enterprise generative AI agents?
The most widely deployed enterprise AI agents are built on OpenAI (GPT-4o), Anthropic (Claude), Google (Gemini), and Meta (Llama), each deployable through frameworks like LangChain, AutoGen, and vendor-native SDKs. All require the same runtime security controls regardless of the underlying model.
What is the difference between AI red-teaming and runtime security?
Red-teaming probes AI systems for exploitable attack paths before or during deployment in a controlled environment. Runtime security enforces protection on every live inference, tool call, and agent action in production. Both are required: red-teaming misses adversarial inputs that only emerge in production, while runtime enforcement has no visibility into structural vulnerabilities.
How does generative AI create compliance risks for regulated industries?
Sensitive financial or customer data entering unvetted AI services creates immediate data residency violations. The EU AI Act requires technical documentation and logging for high-risk AI applications, fully applicable by August 2026. Regulators are increasingly expecting evidence of governance—decision-level audit logs that demonstrate control over AI outputs—not just policy statements.