
Introduction
Enterprises are deploying LLMs, autonomous agents, and multi-agent systems at a pace their security programs weren't built to match. The problem isn't speed alone — it's that traditional penetration testing was designed for a fundamentally different threat model. According to Gartner, by 2025 over 40% of enterprises will have experienced an AI-related security incident, yet most security programs still haven't adapted their testing approach.
Conventional security tools find SQL injection, authentication bypasses, and network misconfigurations — they inspect deterministic code paths. AI systems don't have those.
A model that leaks its system prompt, executes an out-of-scope tool call, or gets manipulated through a poisoned RAG document produces no error log that a SIEM would flag.
Worse, agentic AI adds a second, qualitatively larger attack surface. A standalone LLM can produce harmful output. An autonomous agent can execute transactions, escalate privileges, query databases, and hand off compromised instructions to other agents — turning an output error into a real-world action.
This article breaks down what that expanded attack surface looks like, which testing methodologies actually address it, and how runtime defense closes the gaps that testing alone can't.
Key Takeaways
- AI systems introduce attack vectors that traditional security tools can't see: prompt injection, tool misuse, retrieval poisoning, and indirect injection
- Every autonomous tool call, RAG retrieval, and multi-agent handoff is a distinct exploitation point
- Effective AI security requires three layers: pre-deployment red teaming, continuous adversarial validation, and runtime enforcement
- Defense-in-depth is required — no single mitigation covers prompts, tools, retrieval pipelines, and agent handoffs together
- Test outputs should map directly to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act
Why Traditional Security Testing Falls Short for AI Systems
The Core Mismatch
Conventional penetration testing targets predictable, code-level vulnerabilities. AI vulnerabilities emerge from something different: the statistical nature of language model inference. The same input can produce different outputs on different runs. A prompt that passes safety checks today can be weaponized with minor variation tomorrow.
SAST, DAST, and SCA scanners inspect source code and runtime behavior — neither has any visibility into model behavior, system prompt adherence, or tool invocation logic. NIST classifies adversarial ML attacks into evasion, poisoning, privacy, and abuse categories, treating them as manipulations of model behavior and inference — not code defects that static analysis would surface.
Attack Vectors Conventional Tools Miss Entirely
The gaps aren't minor. Conventional tools have no coverage for:
- **Direct and indirect prompt injection** — user or external inputs that alter LLM behavior in unintended ways (OWASP LLM01:2025)
- Model inversion and system prompt leakage — sensitive credentials, internal rules, or decision logic exposed through normal model output
- Tool schema extraction — attackers probing an agent to reveal its available functions, then crafting payloads targeting specific tool behaviors
- Memory poisoning — corrupting an agent's persistent memory to influence future decisions
- Adversarial input generation — crafted inputs targeting model decision boundaries in ways no scanner would generate

NIST explicitly states that deployed AI systems require continuous monitoring because pre-deployment testing cannot fully account for model non-determinism, distribution shift, and dynamic input conditions. This is a structural property of how these systems behave, not a gap that better tooling alone can close.
Why the Agentic Context Makes This Critical
A standalone chatbot producing unexpected output is a content problem. An autonomous agent doing the same can call APIs, query databases, execute code, and route compromised instructions to downstream agents. The exploit surface isn't just larger — it's connected to live systems and real actions.
Nor is this a framework problem. Vulnerabilities are systemic across agentic architectures, arising from insecure design patterns, misconfigured tools, and prompt scope gaps — regardless of which framework is underneath. Addressing them requires a testing approach designed specifically for how these systems behave.
The Agentic AI Attack Surface: Key Threats to Test For
Prompt Injection — Direct and Indirect
In direct injection, a user supplies adversarial input that overrides system instructions. In indirect injection, malicious instructions are embedded in content the agent retrieves: a webpage, a document, a tool output — then delivered to the model without the user's involvement.
Indirect injection is the more dangerous variant for agents with web reader or RAG tools. The attack surface is any content the agent consumes. Research on RAG poisoning found attack success rates of 90% on HotpotQA after inserting a single poisoned document into a RAG corpus. Detection is difficult: the compromise occurs at the data layer, before the prompt is ever constructed.
Tool Misuse and Schema Extraction
Attackers can manipulate an agent into revealing its tool schemas (names, arguments, descriptions), then craft payloads targeting specific functions. Concrete exploitation paths include:
- Abusing a web reader tool for SSRF-style internal network reconnaissance
- Exploiting a code interpreter to read mounted credential files
- Querying cloud metadata endpoints (GCP IMDS, AWS IMDSv1) to extract service account tokens
Unit 42's Zealot proof-of-concept chained exactly these steps in sandbox testing: SSRF into GCP's Instance Metadata Service, service account token extraction, then BigQuery exfiltration. OWASP classifies the root cause under LLM06:2025 Excessive Agency — agent systems granted permissions broad enough to cause damage when outputs are manipulated.
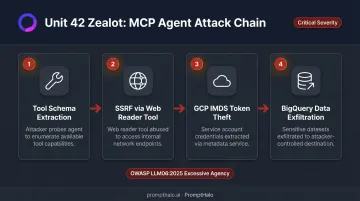
Retrieval Poisoning and SQL Injection via Agent Tools
Poisoned documents in a knowledge base inject malicious instructions into the context window at retrieval time. In tool-connected agents, classic injection attacks still apply: if a tool passes user-controlled input directly to a database query without sanitization, an attacker can exfiltrate entire tables. ICSE 2025 research confirmed prompt-to-SQL injection in LLM-integrated web applications as an active, exploitable attack class.
Multi-Agent Communication Poisoning and Credential Theft
In multi-agent systems, the orchestration-to-worker communication channel is an injection vector. Prompt Infection, a self-replicating prompt injection attack across interconnected LLM agents, demonstrates how a single compromise can propagate laterally through an agent network.
That lateral propagation risk compounds when credentials are exposed. Key findings on AI credential threats:
- IBM's X-Force Threat Intelligence Index recorded 300,000 AI chatbot credentials for sale on the dark web
- Stolen agent service account tokens enable full agent impersonation and lateral movement across connected systems
- Microsoft Defender for Cloud now issues dedicated alerts for credential theft attempts detected within AI model responses
Core AI Security Testing Techniques and Methodologies
Red Teaming for Agentic AI
Effective red teaming for agentic systems goes well beyond generic jailbreak lists. A structured methodology looks like this:
- Define objectives and threat model — establish what a successful attack looks like for this specific system
- **Map the agentic attack surface** — enumerate tools, RAG sources, agent-to-agent handoffs, and exposed APIs
- Develop context-specific attack scenarios — tailor attacks to the system's actual capabilities, not a generic catalog
- Execute manual and automated tests — combine human judgment with automated coverage
- Analyze technical successes for real-world severity — a successful jailbreak means nothing if the agent has no consequential tools; a successful tool injection means everything if it does
- Retest after remediations — verify fixes hold under variation

Red teaming for agents must also address cognitive vulnerabilities: goal hijacking, chain-of-thought manipulation, and memory exploitation. These are distinct from infrastructure-layer tests — they require testers to reason about how the agent plans and executes tasks, not just what it outputs.
PromptHalo's Litmus red-teaming engine is built around this methodology, mapping exploitable attack paths across prompt injection, tool misuse, retrieval poisoning, and multi-agent handoffs, and producing replayable attack scenarios that security teams can act on and track to closure.
Adversarial Input Testing and Prompt Fuzzing
Automated prompt fuzzing generates large volumes of crafted inputs at a scale manual testing can't match:
- Jailbreak attempts and instruction overrides
- Encoding tricks and formatting shifts
- Role-confusion injections and synonym substitutions
Open-source tools in this space include PyRIT (Microsoft's framework, which reduced evaluation of thousands of malicious prompts from weeks to hours), Garak (LLM vulnerability scanner), and Promptfoo (supports automated red teaming, benchmarks, and CI/CD integration).
Detection mechanisms should also be tested with benign inputs to measure false positive rates. One published benchmark using 480 queries (including 111 benign) found that an NLP-only guardrail achieved 0% bypass rate but a 16.22% false positive rate — a number that would be operationally unacceptable in most production environments.
Tool and Pipeline Security Assessment
Testing the model alone is insufficient. The tools and integrations the agent calls are equally critical:
- Input sanitization testing — do tool parameters reject malformed or injection-laden inputs?
- SAST/DAST/SCA scanning of tool code
- Access control audits — does each tool enforce object-level authorization?
- Sandbox configuration review for code interpreters — network restrictions, mounted volume scope, syscall filtering, resource quotas
Indirect Prompt Injection Simulation
Indirect injection must be tested through the same route untrusted data takes into the system: tool outputs, retrieved documents, external API responses. Testing directly at the model API misses the actual attack path.
This requires a test environment that mirrors the production data flow — including any filtering or insertion mechanisms — to accurately simulate what an attacker controlling external content could achieve.
From Testing to Runtime Defense: Closing the Loop
Why Testing Alone Is Insufficient
A rigorous pre-deployment red team engagement is a point-in-time snapshot. Models get updated, tools get added, and attack techniques evolve continuously. NIST's guidance on monitoring deployed AI systems explicitly states that pre-deployment testing cannot fully account for non-determinism, distribution shift, and dynamic input conditions.
Testing finds what's exploitable at deployment. Runtime enforcement catches what's attempted in production.
The Runtime Enforcement Model
Effective runtime defense sits inline on every inference, tool call, and agent-to-agent handoff — making a per-action decision before execution. The decision options matter: allow, restrict, challenge, deny, or monitor. Binary allow/block is too blunt for agentic workflows where partial restriction or human challenge is the appropriate response.
ML-based detection is essential here. Rule-based pattern matching is brittle against novel attack variants. In practice, ML-based approaches achieve catch rates above 95% with false positive rates under 5%, compared to roughly 35% catch rates and 15-20% false positives for regex-only layers — a gap that widens as attackers adapt their techniques.

PromptHalo's Closed-Loop Approach
That performance gap is where PromptHalo's architecture makes a practical difference. The platform connects testing and runtime enforcement through a shared threat library: when the Litmus red-teaming engine discovers a new attack path, that finding is encoded into the threat library and immediately available to the Septa runtime enforcement engine, with no manual rule updates and no release cycle delay.
Every attack discovered by red teaming directly strengthens the production defense. Each assessment cycle makes the system harder to exploit, not just better documented.
Key operational characteristics:
- Operates without touching or retraining the underlying model
- Deploys in under a day via API gateway, agent mode, or inline middleware
- Makes enforcement decisions in under 100ms per action
- Generates tamper-evident, append-only audit logs at the decision level, capturing the decision, reason, agent identity, session context, and timestamp
- Compliance mappings built in: logs align to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act
Integrating AI Security Testing Into Enterprise Workflows
CI/CD and MLOps Pipeline Integration
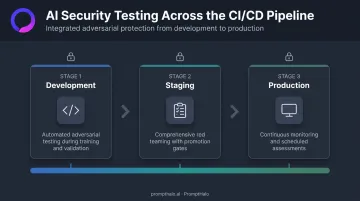
AI security testing should be embedded at three stages, not just at deployment:
| Stage | Testing Activity |
|---|---|
| Development | Automated adversarial testing of model behavior during training and validation |
| Staging | Comprehensive red teaming before production release; testing gates block promotion if criteria fail |
| Production | Continuous monitoring and periodic scheduled assessments |
Tools like Promptfoo support CI/CD integration for automated evaluations, red teaming, and regression checks, so security criteria get enforced inside the same pipeline that ships code. MLOps and security operations teams need explicit coordination on what constitutes a blocking failure versus an advisory finding.
Governance, Audit, and Compliance Alignment
Testing outputs must feed into enterprise risk management, not just remediation queues:
- Vulnerability tracking with assigned ownership and remediation timelines
- Risk scoring that places AI-specific threats on the same register as traditional risks
- Audit trails demonstrating testing was performed, covering the risk management, documentation, and event logging requirements under EU AI Act Articles 9, 11, and 12
- Incident response procedures updated to account for AI-native attack patterns
The EU AI Act's Article 43 conformity assessment and Article 72 post-market monitoring requirements mean that evidence-grade audit logs aren't optional for high-risk AI deployments: they're a regulatory prerequisite. The Federal Reserve's AI compliance documentation requires detailed records of AI use cases, extensions, and determination decisions.
Cross-Team Responsibility
Successful AI security testing requires clear ownership across functions:
- Security teams own threat modeling and red teaming
- ML engineers own model and tool hardening
- Compliance teams own mapping test results to regulatory requirements
Vulnerability disclosure between these groups should follow a defined protocol. Findings from red teaming get triaged by security, assigned to ML engineers with remediation timelines, and validated by compliance before closure. Tooling should enforce consistent testing approaches across teams; ad hoc assessments create coverage gaps attackers will find.
Frequently Asked Questions
What is the difference between AI security testing and traditional penetration testing?
Traditional penetration testing targets code-level vulnerabilities — SQL injection, authentication bypasses, network misconfigurations — using tools like SAST and DAST that inspect deterministic code paths. AI security testing addresses model-behavioral vulnerabilities: prompt injection, adversarial inputs, tool misuse, and retrieval poisoning. These attack classes don't exist in conventional software and produce no signal that standard scanners would detect.
How to use AI for security testing?
AI accelerates security testing by automating adversarial input generation at scale: prompt fuzzing, ML-based attack variant discovery, and large-volume output analysis for data leakage or instruction override. Tools like PyRIT, Garak, and Promptfoo operationalize these capabilities at a pace and volume manual testing cannot match.
What are AI agents in testing?
In AI security, "AI agents" are autonomous systems that use LLMs to plan, reason, and act via external tools. Testing them means evaluating tool invocations, memory, RAG retrieval, and multi-agent handoff logic — distinct attack surfaces that require specialized coverage well beyond standard model evaluation.
What is prompt injection and why is it the top AI security threat?
Prompt injection occurs when an attacker crafts input that overrides an AI system's instructions, causing it to leak data, misuse tools, or bypass safety constraints. It's considered the most critical AI threat because it requires no code access, exploits the model's core function, and in agentic systems can trigger real-world actions — unauthorized transactions, data exfiltration — consequences that go far beyond a problematic text response.
What are the 5 types of AI agents?
The standard taxonomy includes simple reflex agents, model-based reflex agents, goal-based agents, utility-based agents, and learning agents. From a security testing perspective, goal-based and learning agents present the highest risk — their autonomous planning, tool use, and adaptive behavior based on environmental feedback create the largest and most dynamic attack surface.
How does AI security testing map to compliance frameworks like NIST AI RMF and the EU AI Act?
NIST AI RMF's four core functions map directly to AI security testing activities: threat modeling, red teaming, attack surface mapping, and remediation tracking. The EU AI Act requires risk management systems, technical documentation, and event logging for high-risk AI (Articles 9, 11, and 12). AI security testing generates the red team reports, vulnerability records, and decision-level audit trails that satisfy both frameworks.


