
That gap is no longer theoretical. A zero-click indirect prompt injection in Microsoft 365 Copilot (EchoLeak, CVE-2025-32711) enabled sensitive data exfiltration through a crafted email before it was patched in May 2025. Research on agentic coding assistants found attack success rates exceeding 85% using adaptive injection strategies. These aren't edge cases — they're the current baseline.
A new discipline has emerged to close this gap: agentic AI pentesting. This guide defines what it is, maps the attack surface it targets, explains how testing works in practice, and distinguishes it from both traditional pentesting and the separate concept of using AI tools to scan conventional infrastructure.
Key Takeaways
- Agentic AI pentesting targets AI agent systems — their reasoning, tool calls, memory, and multi-agent handoffs — not traditional code or infrastructure
- The agentic attack surface (prompt injection, jailbreaks, RAG poisoning, out-of-scope tool calls) is invisible to firewalls, DLP, and DAST scanners
- Effective testing mirrors real attackers: probing inputs, retrieval pipelines, tool invocations, and agent-to-agent trust
- Findings must drive runtime enforcement across every live inference, tool call, and agent handoff — not just sit in a report
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act now require demonstrable AI-specific security testing
What Is Agentic AI Pentesting?
Agentic AI pentesting is the discipline of probing AI agent systems for exploitable vulnerabilities — covering the agent's reasoning pipeline, tool use, memory, retrieval mechanisms, and multi-agent coordination — with the goal of discovering attack paths before adversaries do.
This is distinct from using AI-powered agents to conduct penetration testing of traditional web apps or infrastructure — which is what most mainstream "agentic pentesting" content covers. The distinction matters. One tests AI systems. The other uses AI to test non-AI systems.
What Makes an AI System "Agentic"
NIST describes AI agents as systems capable of planning multi-step tasks and autonomously taking actions, including using tools and searching databases. An agentic system doesn't just respond to a single prompt — it:
- Plans across multiple steps toward a goal
- Calls external tools and APIs to take real-world actions
- Observes outcomes and updates its state or memory
- Delegates tasks to other specialized agents
This autonomy creates business value. It also creates an attack surface that didn't exist in traditional software — one where a malicious document retrieved from a knowledge base can redirect an agent's tool calls, or a poisoned memory entry can persist across sessions.
What Agentic AI Pentesting Actually Tests
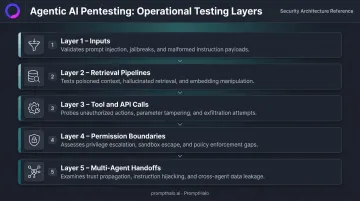
The scope covers five operational layers:
- Inputs — direct user prompts and indirect inputs from documents, emails, or retrieved content
- Retrieval pipelines — what the agent pulls from vector stores or knowledge bases
- Tool and API calls — which external systems the agent can invoke and under what conditions
- Permission boundaries — whether authority is properly scoped and whether it decays appropriately
- Multi-agent handoffs — how trust and authorization flow between agents
This is not about finding SQL injection in a backend database. It's about determining whether the AI itself can be manipulated into unsafe behavior.
Compliance frameworks are now driving adoption. The OWASP LLM Top 10 (2025 edition) and NIST AI 600-1 both identify red-teaming and structured pre-deployment testing as core requirements. The EU AI Act (Articles 9 and 15) separately requires high-risk AI systems to be tested for accuracy, robustness, and cybersecurity before deployment. For regulated industries, that means pentesting is no longer a discretionary exercise — it's the evidence regulators will ask for.
The Unique Agentic AI Attack Surface
The agentic attack surface lives in the model's reasoning, not in the code. Entry points aren't HTTP endpoints; they're inputs, context windows, retrieval results, tool permissions, and inter-agent messages. Conventional scanners see none of this.
Prompt Injection and Jailbreaks
Adversaries embed instructions in user inputs, documents, or retrieved content that override the agent's intended behavior. OWASP LLM01:2025 covers two variants:
- Direct injection — a user submits a crafted prompt that overrides system instructions
- Indirect injection — malicious instructions are hidden in external content (emails, files, web pages) that the agent retrieves and processes later
Google's security team reported a 32% relative increase in malicious prompt-injection detections on the public web between November 2025 and February 2026, based on sweeps of 2–3 billion English-language pages monthly. The attack surface is growing faster than defenses.
RAG and Retrieval Poisoning
Agents using retrieval-augmented generation pull context from vector stores or knowledge bases. An attacker who can influence what gets retrieved can steer the agent's responses — or trigger harmful tool calls — without touching the model directly.
Research on PoisonedRAG demonstrated that injecting a small number of poisoned texts into a knowledge database is sufficient to manipulate outputs for targeted queries. OWASP LLM08:2025 (Vector and Embedding Weaknesses) addresses this class of risk explicitly.
Out-of-Scope Tool and API Calls
Agents with access to external tools — code execution, database queries, payment APIs, email — are vulnerable to manipulation that causes them to invoke those tools beyond their intended permissions. OWASP LLM06:2025 (Excessive Agency) identifies three risk drivers:
- Excessive functionality (the agent has access to tools it shouldn't need)
- Excessive permissions (granted more access than required)
- Excessive autonomy (takes consequential actions without human confirmation)
Each driver opens a distinct path: data exfiltration, unauthorized transactions, or lateral movement across connected systems.

Multi-Agent Trust Exploitation
In systems where one agent delegates tasks to another, trust assumptions between agents become a target. A compromised orchestrator can instruct downstream agents to take actions the original user never authorized. OWASP's Top 10 for Agentic Applications (2026), developed with input from over 100 experts, identifies autonomous and multi-agent trust risks as a primary concern.
PromptHalo addresses this by treating every agent-to-agent handoff as an enforcement point. Each request carries a security passport encoding policy, budget, and authority decay — and receives an allow, restrict, challenge, deny, or monitor decision in under 100ms, backed by a tamper-evident audit trail.
Data Leakage and Scope Violations
Agents handling sensitive data can be probed to surface protected information through crafted queries, or by chaining retrieval with summarization across multi-step interactions. In financial services, a single session may touch account data, transaction history, and compliance records — making cumulative exposure a practical risk, not a theoretical one.
Common leakage vectors include:
- Summarization chains that progressively expose PII across multiple turns
- Retrieval queries crafted to surface documents outside the user's authorization scope
- Cross-session context bleed in stateful agents with shared memory stores
How Agentic AI Pentesting Works
Effective agentic AI pentesting starts with reconnaissance before any probing begins. Testers map the agent's full operational profile:
- What inputs does the agent accept (structured, unstructured, from which channels)?
- What does it retrieve and from which sources?
- Which tools and APIs can it invoke, and what are the permission boundaries?
- How does it interact with other agents or downstream systems?
This mapping defines the real attack surface — not one built from generic threat models.
Adversarial Probing
This phase involves crafting prompts, malicious documents, and poisoned retrieval content designed to override agent instructions, escalate privileges, or trigger unintended tool invocations. Unlike traditional fuzzing — which throws random or malformed inputs at code — effective AI pentesting requires a different kind of knowledge:
- Which guardrails are structurally weakest in the model
- What instruction formats the model is most likely to follow without challenge
- How the agent behaves when inputs are ambiguous, conflicting, or partially poisoned
PromptHalo's AI Red Teaming covers adversarial task chains across multi-step, multi-agent workflows, along with prompt injection, jailbreak, poisoning, and data-leakage probes — attacking agents, RAG layers, and tool chains the way a real adversary would.
Tool Call and API Boundary Testing
The goal here is to cause the agent to invoke out-of-scope tools, bypass per-action budgets, or call APIs with credentials it shouldn't have access to. A critical test is authority decay — whether an agent that acquires elevated permissions through normal workflow retains those permissions beyond their intended scope.
Specific checks include:
- Whether scope boundaries hold when an agent transitions between task phases
- Whether per-action budgets can be circumvented through chained or parallel requests
- Whether credential context leaks across tool invocations
PromptHalo enforces authority decay explicitly: budgets across time, steps, and risk decay as an agent operates, forcing re-authorization when an envelope is exceeded. Each test probes whether this mechanism holds under adversarial conditions.
Multi-Agent Handoff Testing
Tool-call boundaries only tell part of the story. When agents communicate with each other, a separate trust problem emerges: downstream agents often treat messages from upstream agents as implicitly authorized.
This phase checks whether a manipulated handoff can cause a subordinate agent to take actions outside the original user's scope — and whether the receiving agent has any mechanism to verify the instruction's origin or legitimacy. In most systems today, it doesn't.
Validation and Evidence Requirements
A finding is only actionable if it meets three criteria:
- The attack can be triggered reliably, not just once
- A real state change occurred — data accessed, a tool invoked, or an instruction overridden
- The full attack chain is documented, from initial input to exploited outcome
PromptHalo delivers results as risk-scenario-mapped reports with prioritized, actionable fixes. Findings are encoded into a shared Threat Library, where a newly discovered attack pattern becomes a runtime defense without waiting for a new release cycle.
Why Traditional Security Tools Fall Short
The mismatch is fundamental. Firewalls inspect network traffic. DLP tools match known data patterns. SAST and DAST scanners analyze code and HTTP responses. None of these can:
- Observe an agent's reasoning process
- Intercept a poisoned retrieval result before it influences a decision
- Detect that a prompt caused the model to invoke a tool it shouldn't have called
The attack surface is invisible to the existing stack.
The Detection Performance Gap
Rule-based detection — the foundation of most conventional security tools — fails when applied to natural language inputs and model outputs. It produces high false positive rates on normal inputs and misses novel attack vectors entirely, because those vectors were never written into the rules.
PromptHalo's ML-based detection combines Threat Library signatures with classifier-based risk scoring, reaching above 95% catch rate at under 5% false positives. Rule-based approaches land at roughly 35% catch rates with 15–20% false positive rates on AI-specific threats — generating alert fatigue while still missing most attacks.

The Compliance Gap
Regulators and auditors increasingly require evidence that AI systems have been tested against the vulnerabilities in OWASP LLM Top 10 and aligned frameworks. A conventional penetration testing report maps to web application vulnerabilities — SQL injection, XSS, authentication flaws. It says nothing about prompt injection, jailbreaks, or retrieval poisoning.
The EU AI Act imposes specific obligations for high-risk AI systems:
- Article 9 — risk management and testing
- Article 15 — cybersecurity and robustness
- Article 72 — post-market monitoring
A generic web-app pentest doesn't satisfy any of these for AI-specific risks, leaving organizations with a compliance gap they may not discover until an audit.
From Pentesting to Runtime Defense
Discovering a vulnerability during a pentest is only useful if something prevents that same attack from succeeding in production.
Agentic AI systems interact with live users, tools, and data in real time. Static remediations — patching code, updating rules — are often insufficient. The attack surface shifts with every new input, and novel prompt injection variants will always emerge. Runtime enforcement is the necessary second half of the security program.
What Runtime Enforcement Looks Like
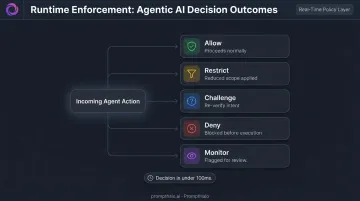
An effective enforcement layer sits inline, evaluating every inference, tool call, and agent-to-agent handoff in real time before it executes. For each action, it makes one of five decisions:
- Allow — action proceeds as normal
- Restrict — action executes with reduced scope or permissions
- Challenge — agent is prompted to re-verify intent or authority
- Deny — action is blocked before execution
- Monitor — action proceeds but is flagged for review
PromptHalo's runtime enforcement operates this way — making per-action decisions in under 100ms with no model retraining and no code rewrite required. The closed-loop architecture means every attack the red teaming phase discovers trains the runtime detection engine through a shared Threat Library. The result: detection accuracy improves continuously without manual rule updates or redeployment cycles.
Audit Trail Requirements
Runtime enforcement decisions are only as useful as your ability to prove them. In regulated environments, system logs aren't enough. Organizations need decision-level, tamper-evident logs showing what each agent did, why, and under what authority.
PromptHalo's audit logs capture every decision along with its reason, the acting agent or passport identity, the session and tenant context, and a timestamp. The log is append-only and tamper-evident — once written, it cannot be modified or removed. This creates a replayable evidence trail that satisfies both internal security teams and external regulators in financial services and other regulated industries.
Frequently Asked Questions
What is the difference between agentic AI pentesting and traditional penetration testing?
Traditional pentesting targets code vulnerabilities, network misconfigurations, and web application flaws. Agentic AI pentesting targets the AI system's reasoning, tool invocations, retrieval pipelines, and multi-agent trust relationships. That requires an entirely different methodology, because the attack surface lives in model behavior, not in code.
What attack vectors are unique to agentic AI systems?
The primary vectors are prompt injection (direct and indirect), jailbreaks, RAG and retrieval poisoning, out-of-scope tool and API calls, multi-agent trust exploitation, and data leakage through chained reasoning. None of these are detectable by firewalls, DLP tools, or DAST scanners.
Can existing security tools protect agentic AI systems?
Conventional tools cannot observe an agent's reasoning or intercept manipulation at the prompt or retrieval level. Protecting agentic AI requires purpose-built testing to find exploitable paths and inline runtime enforcement to block those paths on every live agent decision.
How often should organizations test their agentic AI systems?
Test whenever models are updated, new tools or APIs are connected, retrieval pipelines change, or agent logic is revised. Change-triggered testing is the right model. Point-in-time quarterly audits cannot keep pace with how frequently agentic systems evolve.
What compliance frameworks apply to agentic AI security testing?
OWASP LLM Top 10, NIST AI RMF (AI 600-1), and the EU AI Act are the primary frameworks auditors and regulators reference when evaluating AI system security. Evidence of AI-specific testing mapped to these frameworks is increasingly required, not optional.
What should organizations do after agentic AI pentesting identifies vulnerabilities?
Findings should drive two parallel actions: targeted remediation of exploitable configurations and deployment of inline runtime controls that detect and block discovered attack patterns on every live agent decision. Patching configurations alone is not enough when model behavior shifts with every new input.


