
That assumption is the exposure gap. And it is exactly where AI-native attacks happen.
According to Cisco's 2024 Data Privacy Benchmark Study, 48% of respondents entered non-public company information into generative AI tools, and 62% entered internal process information—across a sample of 2,600 security and privacy professionals. This is not a fringe behavior. It is standard enterprise practice, occurring largely outside the visibility of traditional security tools.
This article covers what an AI policy enforcement platform actually is, where traditional tools structurally fail, the core capabilities that matter, why agentic AI requires a categorically different enforcement approach, and how to evaluate platforms against your actual risk profile.
Key Takeaways
- AI policy enforcement platforms convert written policies into technical controls enforced on every inference, tool call, and agent handoff in real time.
- Traditional DLP and CASB tools cannot understand conversational context, detect intent, or intercept agent decision chains.
- Effective enforcement requires layered, role-aware policies that apply different controls based on user role and data sensitivity.
- PromptHalo's ML-based detection reaches over 95% catch rate with under 5% false positives, outperforming rule-based alternatives by a wide margin.
- Audit trails must be decision-level and replayable, not just access logs, to satisfy regulators and incident reviewers.
What Is an AI Policy Enforcement Platform?
An AI policy enforcement platform translates written AI governance rules into runtime technical controls that apply to every interaction between users, AI models, agents, and the data they touch.
That separates it from adjacent tools with overlapping names:
- DLP tools scan files, transfers, and email attachments for sensitive data patterns
- AI governance platforms document risk, policies, and accountability frameworks
- MLOps tools manage model pipelines, versioning, and deployment workflows
AI policy enforcement platforms act inline, before an interaction executes—not after.
The Two Dimensions That Define Effective Enforcement
Granularity determines who a policy applies to. Effective enforcement operates at multiple levels simultaneously: organization-wide baselines, team-level differentiation by function, individual-level exceptions, and per-model controls that account for different AI providers having different data handling characteristics.
Intelligence determines whether the platform understands why an interaction is happening, not just what data patterns it contains. A static regex rule cannot distinguish a privacy officer analyzing tokenization procedures from a sales rep uploading a customer list to the same AI tool. Both interactions may contain similar keywords. Only one carries serious risk.
What Enforcement Actions Look Like
PromptHalo's enforcement engine makes per-action decisions in under 100ms, applying one of five outcomes to every inference, tool call, and agent handoff:
- Allow — with a full evidence-grade audit trail
- Restrict — permitting interaction with conditions applied
- Challenge — requiring additional verification before proceeding
- Deny — blocking execution before it occurs
- Monitor — logging for review without interrupting the workflow

Most real-world enforcement happens somewhere in that spectrum. Platforms that only support binary block-or-allow force administrators into a choice that serves neither security nor productivity.
Why Traditional Security Tools Fall Short for AI Data Protection
Traditional security tools were not designed for AI. The gap is architectural—and no amount of configuration closes it.
The Visibility Gap
Legacy DLP was built to inspect inspectable artifacts: files, email attachments, data transfers across network boundaries. AI interactions are conversational, often transient, and frequently cross network boundaries through API calls to third-party model providers.
Netskope's 2024 enterprise telemetry found 96% of organizations had users accessing generative AI applications, with GenAI user counts tripling over the prior 12 months. Meanwhile, Microsoft and LinkedIn's 2024 Work Trend Index—surveying 31,000 people across 31 countries—found 78% of AI users bring their own AI tools to work. Much of that usage occurs through browser-based interfaces and personal accounts that sit entirely outside traditional DLP and CASB scope.
The Context Blindness Problem
Static keyword matching and regex rules enforce against data patterns, not intent. They cannot determine whether a request containing customer account numbers is a legitimate compliance audit or an unauthorized data export.
The consequence is predictable: false positives frustrate legitimate users and push them toward unsanctioned tools, while false negatives let actual risks through. Both outcomes undermine the policy.
The Binary Enforcement Trap
Tools that only block or allow create a predictable problem. Block too aggressively, and employees route around approved tools. Block too loosely, and sensitive data reaches unauthorized models. Either path produces shadow AI—employees using unsanctioned tools outside any governance perimeter.
PromptHalo's five-outcome enforcement model exists specifically to break this trap. Graduated enforcement—restrict, challenge, monitor—gives security teams control that doesn't force employees to choose between compliance and productivity.
The Agentic Attack Surface
Traditional security tools were designed for human-initiated requests to deterministic systems. AI agents make autonomous decisions, chain tool calls, access retrieval systems, and hand off context to other agents—without a human reviewing any individual step.
A firewall or DLP scanner has no mechanism to intercept a multi-step agent action before it executes. Securing agentic AI requires inline enforcement at the decision level—before each action runs, not after.
The Rule-Based Detection Quality Problem
AI-native attacks—prompt injection, jailbreaks, retrieval poisoning—do not match static patterns. They are semantically variable and context-dependent.
A peer-reviewed MDPI Algorithms study reported 97.7% accuracy and 0.977 F1 for ML-based indirect prompt injection detection using embedding-plus-classification approaches. Rule-based systems, by contrast, struggle with zero-day prompt injection variants and indirect injection embedded in external documents retrieved by an agent.

When evaluating AI policy enforcement platforms, treat detection accuracy as a primary criterion—not an assumed baseline. The difference between ML-based and rule-based detection is the difference between catching novel attacks and logging them after the fact.
Core Capabilities Every Enterprise AI Policy Enforcement Platform Needs
Real-Time Inline Enforcement Across Every Interaction
Enforcement must be inline and pre-execution. If a data leakage event or prompt injection executes before enforcement catches it, the damage is already done.
Inline enforcement must cover:
- Every inference request
- Every tool call made by an agent
- Every agent-to-agent handoff in multi-step workflows
Latency matters operationally. PromptHalo's runtime enforcement operates in under 100ms per action, designed to avoid the friction that pushes users toward unapproved platforms. Detection runs in milliseconds, catching risky prompts and responses on the wire before delivery.
Granular, Role-Aware Policy Layers
One-size-fits-all policy is a governance failure waiting to happen. Effective enforcement requires policies that operate at multiple levels simultaneously:
- Organization-wide baselines that every user inherits
- Team-level differentiation by function—legal, engineering, finance, customer service
- Individual-level exceptions for specific roles with documented justification
- Per-model controls that account for different AI providers having different data handling postures
A fintech compliance team reviewing regulatory documents and a marketing team drafting campaign copy both need AI access. They should not operate under identical policy constraints. A platform that cannot make this distinction will either over-block legitimate work or under-protect sensitive workflows.
Defining those policy layers sets the scope. What enforces them against active threats is a different problem — one that requires ML-based detection, not static rules.
ML-Based Threat Detection for AI-Native Attacks
The attack categories that enforcement platforms must detect:
- Prompt injection (direct and indirect, including injection embedded in retrieved documents)
- Jailbreaks and instruction overrides
- Data leakage through model outputs and cross-session context carry
- Retrieval poisoning in RAG pipelines
- Out-of-scope tool and API calls by autonomous agents
Static rules cannot catch zero-day prompt injection variants or indirect injection embedded in external documents retrieved by an agent. ML-based detection handles these by scoring interactions against embedding-based threat models — a fundamentally different approach from pattern matching against a fixed list of known signatures.
PromptHalo's detection combines Threat Library signatures with classifier-based risk scoring, achieving a catch rate above 95% at under 5% false positives. For comparison, rule-based approaches typically land around 35% catch rates with 15–20% false positives. That gap determines how much alert fatigue security teams absorb — and how many real threats clear the filter undetected.

Bidirectional Input and Output Coverage
Enforcement must apply in both directions:
Input-side enforcement catches:
- Direct and indirect prompt injection attempts
- Jailbreaks and instruction overrides
- Unauthorized data sharing before it reaches the model
- Out-of-scope requests from agents
Output-side enforcement catches:
- Sensitive information in model responses before it reaches the user
- Data leakage carried across conversations or sessions
- Content safety violations in generated outputs
Organizations that invest in input filtering while neglecting output filtering discover that attacks simply route around the single enforcement point. PromptHalo's bidirectional inspection applies through the same inline pipeline, enforcing policy at the point of action rather than reviewing outputs after the fact.
The Agentic AI Enforcement Gap: Why Agents Require a Different Approach
What Makes Agentic Enforcement Categorically Harder
Autonomous agents do not wait for human review between decisions. A customer-facing financial agent might query account history, initiate a transaction, generate a confirmation, and log the interaction—all from a single user prompt, with no human checkpoint between steps. Each of those steps represents a potential enforcement failure point that traditional tools were not designed to reach.
Gartner predicts that 40% of enterprise applications will feature task-specific AI agents by end of 2026, up from less than 5% in 2025. That is an eight-fold expansion of the agentic attack surface within 18 months.
Agentic Enforcement Primitives
Purpose-built agentic enforcement requires controls that general AI policy tools do not provide:
- Verify agent identity through signed security passports that establish authorization context on every request
- Scope tool-use permissions per action so agents cannot invoke external APIs beyond their initial authorization
- Cap per-action budgets that decay across time, steps, and risk accumulation — keeping blast radius contained
- Trigger re-authorization when an agent exceeds its authorization envelope, blocking permission accumulation across a session
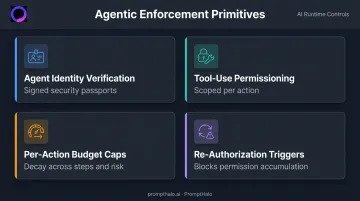
PromptHalo enforces all of these inline, at runtime, before any action executes.
The Multi-Agent Handoff Problem
When one AI agent passes context to another, sensitive data, instructions, or injected adversarial content travels with it. Indirect prompt injection embedded in retrieved content can propagate through an entire agent chain before any output reaches a human reviewer.
Enforcement must apply at each handoff point, not just at the entry point. PromptHalo's runtime security sits inline on every agent-to-agent handoff, applying the same per-action decision logic: allow, restrict, challenge, deny, or monitor. Each decision is recorded in the tamper-evident audit trail.
In regulated environments like financial services, individual transactions and workflow steps carry compliance obligations regardless of the overall session outcome — which means handoff-level enforcement is not optional.
Compliance, Audit Trails, and Regulatory Alignment
Access Logs vs. Decision-Level Audit Trails
Access logs record that a request happened. Decision-level audit trails record what the system evaluated, what policy applied, what action was taken, and why.
Regulators and security teams investigating incidents need the latter. PromptHalo's audit logs are append-only and tamper-evident, capturing for each decision:
- The decision and its reason
- The acting agent or passport identity
- The session and tenant context
- A timestamp
This creates a replayable evidence trail suitable for post-incident forensics and regulatory examination—not just a record that an event occurred.
Regulatory Framework Requirements
Key frameworks that specifically require AI audit documentation:
| Framework | Core Requirement |
|---|---|
| OWASP LLM Top 10 | Prompt injection defenses, least privilege, constrained agent permissions, monitoring and logging |
| NIST AI RMF / AI 600-1 | Govern, map, measure, and manage AI risks continuously; incident response documentation |
| EU AI Act Article 12 | Automatic recording of events over high-risk AI system lifetime |
| EU AI Act Article 17 | Quality management system covering risk management, technical documentation, record keeping |
| HIPAA 45 CFR 164.312(b) | Audit controls for systems containing or using ePHI |
| SOC 2 | Controls covering monitoring, confidentiality, privacy, and system processing integrity |

These frameworks share a common thread: none accept passive logging as sufficient. The financial exposure for falling short is concrete. Under EU AI Act Article 99, violations of prohibited AI practices carry fines up to €35 million or 7% of total worldwide annual turnover, whichever is higher. Other specified non-compliance carries fines up to €15 million or 3%. The regulation is fully applicable from August 2, 2026.
PromptHalo's decision-level audit trail is mapped directly to OWASP LLM Top 10, NIST AI RMF, and EU AI Act requirements—so security teams have the pre-execution control records and continuous monitoring evidence these frameworks demand, not just timestamps showing an event occurred.
How to Evaluate and Select an AI Policy Enforcement Platform
Start with your actual AI deployment profile, not a generic feature checklist.
Three questions to answer before evaluating platforms:
- What types of AI are in use—traditional ML models, LLM applications, or autonomous agents?
- What data sensitivity classification applies to the workflows AI touches?
- What regulatory frameworks apply given your industry and geography?
A financial services firm deploying customer-facing agents has different enforcement requirements than a technology company deploying an internal code review tool. The platform must match your specific attack surface and compliance exposure.
Technical Evaluation Criteria
| Criterion | What to Evaluate | What to Request |
|---|---|---|
| Enforcement latency | Can it intercept requests inline without degrading UX? | Benchmark data for sub-100ms performance |
| Detection quality | What catch rate and false positive rate does it achieve? | ML vs. rule-based comparison; catch rate evidence |
| Vendor agnosticism | Does enforcement require model integration, or does it work across any provider? | Supported deployment modes and integration paths |
| Deployment complexity | How long from procurement to active protection? | Documented onboarding timeline and prerequisites |
On the deployment complexity criterion specifically, look for platforms that activate without model retraining or code rewrites — slow onboarding often signals deeper integration friction down the line. PromptHalo, for instance, deploys in under a day across any AI application via API gateway, agent mode, or inline middleware, with no changes to the underlying model.
Integration and Scalability Considerations
Three questions that determine whether enforcement holds as AI adoption grows:
- Does the platform integrate with your existing identity and access management systems?
- Does it connect to your SIEM for audit log forwarding?
- Does performance scale linearly as model counts, user volumes, and agent deployments increase, or does it create architectural bottlenecks?
Gartner's forecast that task-specific AI agents will appear in 40% of enterprise applications by end of 2026—up from less than 5% today—means platforms selected for today's footprint may face a entirely different enforcement challenge within 18 months. A platform that handles 10 models today should be evaluated on whether it can govern 200 agents without architectural rework.
Frequently Asked Questions
Which AI policy enforcement platforms are best for global enterprises?
Global enterprises should prioritize model- and vendor-agnostic platforms that enforce policy across distributed teams and geographies without requiring model retraining or provider-specific integration. Regulatory alignment across the EU AI Act, NIST AI RMF, GDPR, and HIPAA should be built into the enforcement layer, not bolted on afterward.
What is AI policy enforcement in enterprise AI security?
AI policy enforcement is the operational layer that turns written AI governance rules into runtime technical controls, applied to every inference, tool call, and agent action before it executes. It is distinct from governance documentation, DLP scanning, and MLOps pipelines, none of which provide inline enforcement.
How do AI policy enforcement platforms differ from traditional DLP tools?
Traditional DLP tools scan inspectable artifacts like files and email for sensitive data patterns but cannot understand conversational AI context, detect intent, or intercept autonomous agent actions. AI policy enforcement platforms operate inline across AI-specific attack surfaces—prompt injection, retrieval poisoning, agent tool calls—that DLP tools were never designed to see.
How do AI policy enforcement platforms handle agentic AI and autonomous agents?
Purpose-built platforms enforce trust on each agent action through identity registration, tool-use permissioning, per-action scope limits, and multi-agent handoff interception, all applied before execution. PromptHalo issues agent security passports with built-in authority decay and budget enforcement, making per-action decisions in under 100ms across every inference, tool call, and agent-to-agent handoff.
What regulatory frameworks do AI policy enforcement platforms need to support?
Primary frameworks include OWASP LLM Top 10 for AI-specific vulnerability coverage, NIST AI RMF for continuous risk management documentation, the EU AI Act for high-risk AI system obligations (fully applicable August 2026), and industry-specific standards like SOC 2 and HIPAA. Enforcement platforms should map every policy decision to these frameworks in audit logs, not just reference them in documentation.


