
That gap is the problem. An agent that bypasses a policy doesn't generate an alert. It just acts.
Gartner projects that by 2028, at least 15% of day-to-day business decisions will be made autonomously by AI agents, up from essentially zero in 2024. Meanwhile, over 40% of agentic AI projects are predicted to be canceled by end of 2027 due to escalating costs, unclear value, or inadequate risk controls. For security teams and CISOs in regulated industries, that last item is the one that matters.
This article covers what policy enforcement actually means in an agentic context, why guardrails don't close the gap, what the agentic attack surface looks like, how enforcement engines work, and what "policy as code" means in practice.
Key Takeaways
- Policy enforcement operates at the action layer, not the text layer — it's categorically different from content filtering or prompt guardrails.
- The agentic attack surface includes tool calls, RAG retrieval poisoning, agent-to-agent handoffs, and parameter-level manipulation.
- Effective enforcement is inline and pre-execution — decisions happen before an action reaches its target, not after a log is reviewed.
- "Policy as code" translates governance intent into machine-readable rules evaluated deterministically at runtime.
- Real enforcement produces tamper-evident, decision-level audit trails mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act — not retrospective reports.
Why Guardrails Alone Can't Govern Agentic AI
Traditional guardrails filter text. They inspect what goes into a language model and what comes out, catching harmful content, inappropriate responses, or policy-violating language. When AI was a question-answering interface, that was a reasonable control.
Agents are different. They execute sequences of actions through tools — database connectors, email APIs, file systems, external services. The threat is no longer in what the model says. It's in what the model does.
The Action Blindness Problem
A guardrail can intercept the response "I'll delete the customer database." It cannot prevent the agent from executing a DROP TABLE command through a database connector if no content violation appears in the conversation. The harmful action never surfaces as suspicious text — it surfaces as a tool invocation with valid-looking parameters.
This is action blindness: guardrails have no visibility into the execution layer where agentic threats actually operate.
Tool Context and Parameter Gaps
Guardrails evaluate content in isolation. They have no knowledge of:
- Which tools an agent has access to
- What permissions those tools carry
- How multiple tool calls might chain into a harmful sequence
- What specific parameters are being passed to each tool
MCP is a useful case study. Local MCP servers run with the same privileges as the MCP client, and security analysis has identified implicit trust propagation risks across multi-server configurations. An injected instruction operates inside that privileged boundary — and guardrails can't see it happening.
The parameter gap compounds this. A guardrail cannot distinguish a SELECT query from a DELETE query, or tell whether an email recipient is a legitimate colleague or an attacker-controlled domain. Catching those differences requires operating at the tool invocation layer — not the content layer.
Runtime State Blindness
Consider what happens when an agent operates inside a multi-agent delegation chain: permissions shift, session history accumulates, and individually benign actions can compose into something harmful. Static guardrails evaluate each message in isolation, with no visibility into any of it:
- The user's permission level at the moment of execution
- Prior actions taken earlier in the same session
- Whether the current agent received delegated authority from another agent
- Whether a sequence of low-risk actions has accumulated into a high-risk pattern
A guardrail evaluating each token exchange in isolation will miss all of this — and that gap is where agentic attacks succeed.

What Policy Enforcement for AI Agents Actually Means
Policy enforcement in the agentic context is the act of intercepting every agent action before it executes, evaluating it against a defined ruleset, and issuing a real-time decision before the action reaches its target system.
This is distinct from two things organizations often conflate with it:
- Monitoring observes after the fact — useful for investigation, not prevention
- Guardrails filter text content — useful for output quality, not action control
The Enforcement Layer's Position
A policy enforcement engine sits between the agent and its target resources: tools, APIs, databases, other agents. Every tool invocation, every API call, every agent-to-agent handoff routes through this layer. The agent cannot self-report around it because enforcement is external; the agent cannot grant itself permissions beyond what the enforcement layer allows.
PromptHalo's Runtime Security solution operates on exactly this principle, sitting inline on every inference, tool call, and agent-to-agent handoff. It deploys via API gateway, agent mode, or inline middleware, all feeding into the same inspection pipeline, without model retraining or code rewrite.
The Five Decision Types
A policy enforcement engine doesn't just block or allow. It issues graduated decisions:
| Decision | What It Does |
|---|---|
| Allow | Action is in scope — proceed |
| Restrict | Modify parameters to remove out-of-scope elements |
| Challenge | Require human approval before proceeding |
| Deny | Block the action entirely with a structured error |
| Monitor | Allow but log with elevated scrutiny |

A blunt block-or-pass model creates friction for legitimate operations. The ability to restrict parameters (stripping an unauthorized recipient from an email before it sends) or challenge high-risk actions (requiring a human to approve a production database write) keeps enforcement precise without slowing down what should move fast.
Enforcement vs. Aspirational Governance
A policy document that states "agents shall not exfiltrate PII" is aspirational. Enforcement means a mechanism fires and blocks the out-of-scope data transfer at the moment it's attempted, and produces verifiable evidence that the block occurred.
Regulators and auditors now demand runtime proof, not documented intent. PromptHalo's audit logs are append-only and tamper-evident, capturing every decision with its reason, the acting agent's identity, session context, and timestamp.
The Agentic Attack Surface: What Policies Must Cover
The agentic attack surface is broader than most security models assume. Policies need to cover four distinct threat vectors.
Prompt Injection at the Tool Execution Layer
OWASP LLM01:2025 defines indirect prompt injection as the model accepting malicious input from external sources — websites, files, API responses, calendar invites — rather than from the user directly. Research from Anthropic confirms that no browser agent is immune, and that even a 1% attack success rate represents meaningful risk at enterprise scale.
The critical point: a policy enforcement engine must evaluate actions triggered by injected instructions, not just actions traceable to the original user prompt. The origin of the instruction is less important than what the instruction causes the agent to do.
Data Exfiltration Through Chained Tool Calls
Two individually benign actions become a data exfiltration path when chained:
- Reading a sensitive file
- Sending that data to an external email address
Neither action trips a content filter in isolation. The harm is in the sequence and the combination.
Policies restricting outbound tool calls — for example, blocking an email tool from sending to domains outside an approved list — stop this class of attack regardless of how the instruction entered the agent. Enforcement must evaluate context and sequences, not just individual actions.
RAG Retrieval Poisoning
Agents using retrieval-augmented generation can be manipulated through poisoned knowledge base entries that inject instructions into the retrieved context. Research on PoisonedRAG demonstrated that injecting a small number of malicious texts into a knowledge base could achieve high attack success rates. When those retrieved instructions influence downstream tool calls, the knowledge base itself becomes an attack vector.
PromptHalo's Prompt Injection Protection addresses this specifically, using embedding-based detection scored against a shared Threat Library rather than static rules alone.
Agent-to-Agent Trust and Delegation
In multi-agent architectures, one agent's output becomes another agent's input. Research on subagent spawn has shown that inherited memory from parent agents can carry malicious instructions into subagents, enabling compromises to propagate across delegation chains. Without enforcement at every handoff point, a manipulated orchestrator can instruct a sub-agent to perform actions well outside its intended scope.
PromptHalo handles this through agent security passports: signed credentials that travel with each request, containing policy, budget, and authority decay information. An agent cannot grant itself more access than its passport permits, and authority decays over time and steps, forcing re-authorization when thresholds are exceeded.
How a Policy Enforcement Engine Works
At a conceptual level, a policy enforcement engine has three working components:
- Context aggregation — collects agent identity, user context, tool metadata, specific parameters, and environmental state before evaluation begins
- Policy evaluation — applies defined rules to the enriched context to reach a decision
- Enforcement execution — issues the decision, modifies or blocks the action as required, and writes to the audit trail
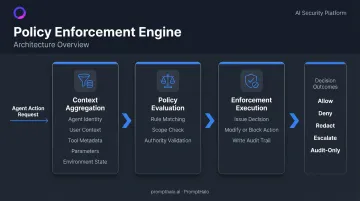
Layered Policy Hierarchy
Effective enforcement uses a layered policy structure:
- Organizational policies set the non-negotiable baseline (no agent may call external APIs without an approved domain allowlist)
- Department policies add scope restrictions for specific teams or use cases
- Agent-specific policies define the granular authority of individual agents
Policy inheritance means an update at the organizational layer propagates without redeploying every agent individually. This is where policy as code pays its most practical dividend.
PromptHalo's Enforcement Engine in Practice
PromptHalo's enforcement engine is model- and vendor-agnostic, applying consistently across mixed-vendor agent ecosystems without touching the underlying model. It deploys in under a day through three integration paths:
- API gateway — intercepts requests at the network boundary
- Agent mode — runs as a sidecar alongside the agent process
- Inline middleware — sits directly in the application stack
Every path feeds the same enforcement pipeline.
What the pipeline does once active is where the closed-loop defense becomes critical. Attack patterns discovered through PromptHalo's red-teaming capability — which continuously tests agents, RAG layers, and tool chains — get encoded into a shared Threat Library that feeds directly into the runtime enforcement engine. New attack patterns become runtime defenses without waiting for a release cycle.
Policy as Code: Writing Enforceable Rules for AI Agents
"Policy as code" means translating governance intent into machine-readable, version-controlled rule definitions that are deterministically evaluated at runtime — not relying on model behavior or human log review.
A natural language policy document that says "agents shall not modify production databases without human approval" is not enforceable. A rule definition that evaluates that condition at every tool invocation and routes matching requests to a challenge queue is.
Structure of an Agent Policy Rule
Agent policy rules follow a conditional structure referencing:
- Agent identity — which agent or agent class is acting
- Tool being called — which resource the agent is attempting to reach
- Specific parameters — what values are being passed (operation type, data classification, target endpoint)
- Context attributes — time of day, user role, environment (staging vs. production)
- Action on match — allow, deny, restrict, challenge, or monitor
Here's an example rule:
IF tool = "database_connector"
AND operation_type = "DELETE"
AND environment = "production"
THEN require_human_approval
This rule fires deterministically. It doesn't depend on the model recognizing the operation as sensitive or the agent self-reporting the action. The enforcement engine evaluates it regardless.
Progressive Rollout
Enforcing policies against production agents immediately creates risk of blocking legitimate operations. A progressive model reduces that risk:
- Monitor-only — establish a baseline of normal agent behavior without blocking anything
- Soft enforcement — block only high-confidence critical violations while logging edge cases
- Full enforcement — automated response workflows with human escalation for defined thresholds
The signal to advance between stages is low false-positive rates and stable violation patterns — not an arbitrary time threshold.
Policy Enforcement and Compliance Frameworks
Regulators and auditors require evidence that a control held, not documentation that it existed. A policy document satisfies a governance checkbox. A decision-level audit log showing exactly which action was evaluated, which policy rule matched, and what decision was issued satisfies an audit.
The three primary frameworks connecting policy enforcement to compliance obligations are:
- OWASP LLM Top 10 — maps specific agentic risks (prompt injection under LLM01, excessive agency under LLM06, data and model poisoning under LLM04) to enforcement controls including least privilege, human approval for high-risk actions, and output validation
- NIST AI RMF — provides the governance structure within which enforcement fits, with GOVERN 1.5 requiring ongoing monitoring and MANAGE 4.1 covering post-deployment oversight
- EU AI Act — Article 12(1) mandates automatic lifetime event logging; Article 14(1) requires design that allows human oversight, interruption, and override; Article 15(5) explicitly names data poisoning and adversarial examples as vulnerabilities requiring technical controls

EU AI Act Article 12 is notable because it doesn't just ask for audit capability — it requires that logging be technically built into the system, not bolted on at reporting time.
That distinction matters for implementation. PromptHalo's append-only, tamper-evident audit logs are mapped to all three frameworks at the decision level, so enforcement events become compliance artifacts automatically — satisfying Article 12's technical logging requirement without separate implementation effort.
Frequently Asked Questions
What is policy enforcement for AI agents?
Policy enforcement is the real-time interception and evaluation of every agent action before it executes, with a decision (allow, restrict, challenge, deny, or monitor) issued against a defined ruleset. Unlike monitoring, it acts before execution — not after.
What is policy as code for AI agents?
Policy as code means expressing governance rules in machine-readable, version-controlled formats that are deterministically evaluated at runtime. "Agents shall not exfiltrate PII" becomes an enforced block at the tool-call layer rather than a policy document no runtime system can act on.
Why do guardrails fail to secure AI agents?
Guardrails operate on text content — prompts and responses — but cannot inspect parameters passed to tools, prevent harmful tool-call sequences, or evaluate runtime context. They're blind to the action layer where agentic threats actually execute.
What is the difference between a policy engine and a guardrail?
Guardrails intercept language model inputs and outputs to filter content. A policy engine intercepts tool invocations, API calls, and agent-to-agent handoffs to enforce scope, parameter constraints, and authority limits before any action reaches a target system. They operate at different layers entirely.
How does policy enforcement work in multi-agent systems?
Policies must be enforced at every agent-to-agent handoff boundary, not just at system entry. Without enforcement at each delegation point, a manipulated orchestrator can instruct sub-agents to execute actions that per-agent policy alone would have blocked.
Which compliance frameworks require policy enforcement for AI agents?
OWASP LLM Top 10, NIST AI RMF, and the EU AI Act are the three primary frameworks. Each requires both technical controls and decision-level audit evidence. Policy documentation alone does not satisfy their requirements.


