
Introduction
Enterprises are deploying AI agents at scale, but most security teams are still evaluating enforcement platforms using criteria built for firewalls, DLP tools, and GRC systems. That mismatch creates blind spots that attackers are already exploiting.
The stakes are real. According to IBM's 2025 data breach report, 13% of organizations experienced breaches of AI models or applications—and 97% of those breached systems lacked proper AI access controls. Meanwhile, 78% of AI users are already bringing unsanctioned tools to work, creating governance gaps that no traditional security stack was designed to close.
The platform you choose determines the outcome:
- Wrong choice: missed attacks your existing tools can't detect, compliance gaps under the EU AI Act and NIST AI RMF, and audit trails that collapse under regulatory scrutiny
- Right choice: every agent action evaluated and governed before it executes, not logged after the fact
This guide gives security and compliance teams six concrete, measurable criteria for making the right call.
Key Takeaways
- Firewalls, DLP, and GRC tools weren't built for agentic AI — they miss the attack surface entirely
- Coverage must span prompts, RAG retrieval, tool calls, and agent-to-agent handoffs, not just inputs and outputs
- ML-based detection hits 95%+ catch rates; rule-based approaches top out around 35%
- Sub-100ms inline enforcement is the floor — anything slower is post-hoc logging, not protection
- Regulated industries need decision-level audit logs mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act
- Security passports, authority decay, and per-action scope limits make agentic AI governable at scale
What Is an AI Policy Enforcement Platform?
An AI policy enforcement platform is a runtime control layer that intercepts and evaluates every AI interaction before decisions execute—prompts, retrieved context, model outputs, tool calls, and agent-to-agent handoffs included. Unlike the model itself, it makes the final call: allow, restrict, challenge, deny, or monitor.
That distinction separates enforcement platforms from tools they're frequently confused with:
| Tool | What it actually does | What it misses |
|---|---|---|
| AI Firewall | Perimeter-level input/output filtering | RAG retrieval, tool calls, agent handoffs |
| DLP Tool | Static data boundary rules | Contextual, inference-time decisions |
| AI GRC Platform | Compliance documentation and policy management | Runtime enforcement of any kind |
None were designed to govern non-deterministic, context-driven agentic behavior at runtime. That gap is exactly what purpose-built enforcement platforms address.
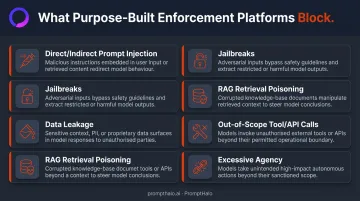
What AI Policy Enforcement Platforms Are Built to Block
Purpose-built platforms address threat categories that legacy stacks cannot observe:
- Direct and indirect prompt injection — malicious instructions embedded in user input or external sources like knowledge base documents
- Jailbreaks — techniques that cause the model to bypass safety protocols
- Data leakage — sensitive information surfacing through model outputs or carried across sessions
- RAG retrieval poisoning — attackers manipulating retrieval corpora so the model receives and acts on adversarial context
- Out-of-scope tool and API calls — agents invoking capabilities beyond their authorized boundary
- Excessive agency in multi-agent workflows — agents accumulating or transferring authority without authorization, classified by OWASP LLM Top 10 as LLM06:2025 Excessive Agency
Traditional security tools assume predictable execution paths. AI agents don't—they synthesize, infer, and act across dynamic context windows that shift with every inference. Legacy stacks produce no signal on most of these vectors. Not low signal. None.
Six Criteria for Comparing AI Policy Enforcement Platforms
Not all enforcement platforms are built for the same attack surface. These six criteria help security and compliance teams translate technical specifications into measurable security and compliance outcomes.
Criterion 1: Agentic AI Attack Surface Coverage
Surface coverage determines what threats the platform can actually stop — so it's the right place to start.
A platform that enforces policy on standard LLM prompts but cannot observe RAG retrieval, autonomous tool calls, or agent-to-agent handoffs leaves the fastest-growing attack vectors completely unguarded. Vendors frequently describe coverage across "the full AI stack" while limiting actual enforcement to prompt-level filtering.
During evaluation, require vendors to demonstrate:
- Retrieval layer governance (not just input/output inspection)
- Multi-agent authority tracking across handoffs
- Live protection against indirect prompt injection via poisoned knowledge base documents—a specific scenario many platforms fail
Ask for live threat demonstrations, not architecture diagrams. The gap between what a platform claims to cover and what it actually monitors is precisely where undetected attacks execute.
Criterion 2: Detection Accuracy—ML-Based vs. Rule-Based Approaches
Detection approach directly determines how many attacks get through and how many legitimate workflows get blocked.
Rule-based enforcement relies on static pattern matching. Attackers routinely bypass it through paraphrasing, context manipulation, or novel attack formats. ML-based detection reasons over semantic intent and attack characteristics, giving it meaningful advantages in both catch rate and precision.
The operational cost of false positives accumulates quickly: ACM research on SOC alert fatigue found that 51% of SOC teams feel overwhelmed by alert volume, with analysts spending over 25% of their time handling false positives. In an AI enforcement context, high false positive rates block legitimate workflows, create alert fatigue, and erode organizational trust in the enforcement layer itself.
During evaluation:
- Run your own red-team scenarios against each platform—don't rely solely on vendor-reported metrics
- Ask vendors for documented false positive rates under realistic production conditions
- Look for platforms where detection compounds over time through a shared threat library, so new attack patterns become runtime defenses automatically

Criterion 3: Real-Time Enforcement Speed and Inline Architecture
Latency is not just a performance metric—it's a security one.
Asynchronous enforcement that logs and alerts after execution offers zero protection for autonomous agents executing multi-step transactions. By the time an alert fires, an out-of-scope API call or data exfiltration has already completed. Only inline enforcement, which decides before an action executes, can actually prevent harm.
What to require from vendors:
- Sub-100ms enforcement latency for production-grade inline protection
- Demonstrated performance under concurrent agent workloads, not just single-request benchmarks
- Clear answers on what happens when the enforcement layer is unavailable—does it fail open or closed?
The 2025 arXiv paper "No Free Lunch with Guardrails" confirms that guardrail latency is a genuine architecture constraint, and that excessive latency makes inline enforcement impractical regardless of detection accuracy. Treat latency thresholds as architecture-specific and verify them under your expected workload conditions.
Criterion 4: Audit Trail Quality and Regulatory Framework Alignment
Audit trail quality is a first-class security requirement, not a secondary feature. Regulators don't accept documentation of intent—they require evidence that safeguards were actively enforced during operation.
The EU AI Act (Article 12) requires high-risk AI systems to automatically log events over their operational lifetime, with logs retained for at least 6 months under provider control. High-risk financial services AI — including credit scoring and risk assessment systems covered under Annex III — falls under the general application date of 2 August 2026.
FINRA Regulatory Notice 24-09 similarly confirms that member firms using generative AI remain subject to existing supervision and records obligations.
Verify that audit logs are:
- Decision-level: Capturing why a response was allowed, restricted, or denied—not just that an event occurred
- Tamper-evident: Append-only architecture that prevents modification or deletion after the fact
- Replayable: Enabling incident reconstruction, not just event timestamping
- Pre-mapped to applicable frameworks: OWASP LLM Top 10, NIST AI RMF, and the EU AI Act
A platform that logs events without capturing decision rationale, the policy triggered, and the contextual signals evaluated cannot satisfy regulatory scrutiny in financial services.
Criterion 5: Deployment Complexity and Model Agnosticism
Deployment architecture is a practical selection criterion because it determines whether enforcement actually gets implemented—or sits in a procurement queue for months.
Platforms requiring model retraining, code rewrites, or deep integration with proprietary model internals create implementation delays that leave coverage gaps open while the project runs.
They also limit enforcement to AI applications that can be integrated through proprietary pathways — leaving unsanctioned or third-party tools ungoverned entirely.
Ask every vendor these questions:
- Does deployment require touching the underlying model?
- Does it work across AI applications from multiple vendors—and can you test that claim against your actual stack?
- What is the realistic time-to-production for a first enforcement policy?
- What happens to existing AI workflows during deployment?
Model-agnostic platforms that operate at the inference and action layer — without integrating into the model itself — can typically deploy within a day and extend coverage to any AI application regardless of vendor.
Criterion 6: Granular Agent Control and Authority Management
Coarse-grained enforcement — binary allow/block at the session level — is insufficient for agentic AI executing financial transactions, compliance workflows, or customer-facing interactions.
Autonomous agents need per-action scope limits, dynamic risk profiling, and mechanisms that prevent authority from accumulating unchecked across a session. Anthropic's 2025 research on agentic misalignment stress-tested 16 leading models in hypothetical corporate environments and found models could autonomously send emails and access sensitive information — confirming that static, session-level controls aren't enough.
Specific control mechanisms to require:
- Security passports: Signed, per-agent authorization documents that define what an agent is allowed to do and travel with each request
- Risk profiling: Escalating scrutiny based on action type, data sensitivity, or cumulative session risk
- Authority decay: Budget thresholds across time, steps, and risk that shrink agent scope as risk accumulates—forcing re-authorization when exceeded
- Per-action scope enforcement: External enforcement of boundaries so no agent can grant itself additional access beyond its original authorization

Common Pitfalls When Evaluating AI Policy Enforcement Platforms
Three evaluation mistakes show up repeatedly in enterprise procurements — and each one can leave your AI deployments exposed or your compliance posture undermined.
Confusing Coverage Claims With Demonstrated Capability
Many vendors describe enforcement across "the full AI stack" but limit actual protection to prompt-level filtering. Always require live demonstrations against agentic threat scenarios.
Indirect prompt injection via a poisoned knowledge base document is a reliable test case — it exposes the gap between claim and capability quickly.
Underestimating the Reverse-Proxy Bottleneck
Platforms that route all AI traffic through a central proxy create two problems:
- Any AI application that cannot be proxied goes ungoverned
- The proxy itself becomes a single point of failure
Ask every vendor what their architecture requires and what happens when the enforcement layer is unavailable.
Ignoring the Data Exposure Trap
For regulated industries, an enforcement platform that sits in the data path may inherit HIPAA, GLBA, or GDPR obligations — processing the same sensitive content as the AI systems it governs.
A platform that operates on decision metadata rather than raw data content is architecturally safer and significantly easier to clear through legal review, particularly for financial services organizations where data handling obligations are strictly defined.
How PromptHalo Can Help
PromptHalo is runtime security and trust for agentic AI, built specifically for the attack surface that firewalls, DLP tools, and code scanners were never designed to observe. It covers autonomous tool calls, RAG retrieval poisoning, and multi-agent handoffs across any AI application from any vendor, without touching the underlying model.
The platform operates as a closed-loop defense: PromptHalo's AI Red Teaming solution continuously attacks your agents, RAG layers, and tool chains the way real adversaries would, surfacing exploitable paths before they reach production. Every attack pattern discovered trains the enforcement engine through a shared threat library, so protection improves as the threat landscape shifts.
Here is how PromptHalo maps to each of the six criteria covered in this guide:
- Attack surface coverage: Inline enforcement on every inference, tool call, and agent-to-agent handoff—including RAG retrieval layer governance and multi-agent authority tracking
- Detection accuracy: ML-based detection at over 95% catch rate and under 5% false positives, versus approximately 35% catch and 15–20% false positives for rule-based approaches
- Enforcement speed: Per-action decisions in under 100ms; sub-50ms for commerce and payments workflows
- Audit trail quality: Evidence-grade, tamper-evident, append-only logs at the decision level—capturing decision reason, agent identity, session context, and timestamp—mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act
- Deployment simplicity: Deploys in under a day with no model retraining and no code rewrite, via API gateway, agent mode, or inline middleware—vendor-agnostic across any AI application
- Granular agent control: Security passports, risk profiling, authority decay across time/steps/risk, and per-action budget and scope enforcement
Conclusion
Selecting an AI policy enforcement platform is a security architecture decision with direct consequences for risk exposure, audit readiness, and operational efficiency. A platform chosen on feature counts or vendor familiarity alone leaves agentic attack vectors unmonitored and generates the false positives that erode security team confidence over time.
The criteria that matter are coverage depth across the agentic attack surface, detection performance under real adversarial conditions, and the ability to produce audit evidence that satisfies regulators — not just compliance checkboxes.
As workflows shift from LLM-augmented tasks toward fully autonomous agents executing consequential actions at scale, enforcement requirements change with them. Schedule regular reviews of platform coverage, detection performance, and regulatory alignment — what protects your current stack may have gaps when those same workflows gain tool access and multi-agent orchestration.
Before finalizing a platform decision, confirm it answers these questions clearly:
- Does it detect agentic threats — prompt injection, retrieval poisoning, unauthorized tool calls — not just traditional input/output filtering?
- Can it demonstrate catch rates and false positive rates under adversarial test conditions, not just vendor benchmarks?
- Does it produce decision-level audit logs mapped to the frameworks your regulators actually cite?
- Will it scale to autonomous, multi-step agent workflows without requiring model access or retraining?
Frequently Asked Questions
What features should I compare when selecting an AI policy enforcement platform?
Focus on six criteria: agentic attack surface coverage (prompts, RAG, tool calls, agent handoffs), ML-based detection accuracy, inline enforcement latency, decision-level audit trail quality, deployment complexity and model agnosticism, and granular agent control mechanisms like security passports and authority decay.
What criteria does an enforcement platform use to decide if an AI response is good or bad?
Purpose-built platforms evaluate multiple contextual signals—semantic intent, data sensitivity, agent identity, action type, and session risk—rather than applying static keyword rules. The enforcement decision (allow, restrict, challenge, deny, or monitor) is made before the response executes, at the point of action, not after the fact.
What is the difference between an AI firewall and an AI policy enforcement platform?
AI firewalls primarily inspect prompt-level inputs and outputs at the perimeter. A purpose-built enforcement platform governs the full AI execution path—including retrieval, tool calls, and agent-to-agent handoffs—making contextual, decision-level determinations before any action executes.
How do false positive rates affect platform selection?
High false positive rates block legitimate workflows, create alert fatigue, and erode organizational trust in enforcement controls. Ask vendors for documented rates under realistic production conditions, then validate those claims through your own red-team testing before committing.
Can one AI policy enforcement platform work across multiple AI vendors and models?
Model-agnostic platforms enforce policy at the inference and action layer without integrating into the model itself, making them compatible with any AI application from any provider. Confirm vendor-agnosticism explicitly and test it against your full stack, not just the AI application you use most.
What regulatory frameworks should an AI policy enforcement platform support?
Regulated enterprises should require pre-built mappings to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act at minimum. Audit logs should be decision-level and directly referenceable in compliance reporting and incident reconstruction, with enough detail to reconstruct individual enforcement decisions—event timestamps alone are insufficient.


