
Introduction
Most AI incidents don't happen at deployment — they happen months later, after data has shifted, user behavior has changed, and threat actors have had time to probe for weaknesses that didn't exist during testing. Without a structured monitoring approach, teams typically find out something went wrong only after the damage is visible.
The numbers reflect this gap clearly. According to IBM's 2025 Cost of a Data Breach Report, 97% of organizations that experienced an AI-related security incident lacked proper AI access controls, and 63% had no AI governance policies in place at all.
This guide covers why continuous monitoring is critical, what the four monitoring layers look like in practice, which warning signs demand immediate attention, and how to build a monitoring cadence that matches your risk profile.
Key Takeaways
- Continuous AI monitoring keeps deployed models accurate, secure, and compliant — it's an operational requirement, not an optional add-on
- Effective monitoring spans four layers: model performance, data quality, runtime security, and compliance audit trails
- Model drift, anomalous outputs, and AI-native attacks each require distinct detection approaches
- A structured cadence — real-time for security, daily for performance, monthly for compliance — reduces both risk and remediation cost
- Tamper-evident audit logs are a regulatory requirement under NIST AI RMF, OWASP LLM Top 10, and the EU AI Act
Why Continuous AI Monitoring Is Non-Negotiable
RAND research estimates that more than 80% of AI projects fail — roughly twice the failure rate of conventional IT projects. A significant share of those failures happen not at launch, but after deployment, when models encounter data they weren't built for and nobody notices until users start complaining.
Unlike traditional software, AI systems are probabilistic. The same input can produce different outputs across sessions. Behavior shifts as real-world data evolves. And failure modes are often gradual — a slow drift in accuracy or a subtle change in output tone — rather than the hard crashes that conventional monitoring tools are designed to catch.
This creates three problems that passive monitoring cannot solve:
- Invisible degradation — model accuracy can decline for weeks before it becomes visible in user-facing metrics
- Adversarial exploitation — prompt injection and retrieval poisoning attacks succeed silently, with no error logs to trigger an alert
- Compliance exposure — without continuous evidence collection, regulatory audits produce gaps that are expensive to explain and impossible to retroactively fill
For organizations in regulated sectors like financial services, the stakes extend beyond operational risk. A 2024 study published in Finance Research Letters found that AI incidents at banks and financial firms were associated with an average short-term stock return loss of -21.04% around the event window. That's not a monitoring problem — it's a board-level risk event.
The rest of this guide covers what to monitor, how to build detection that catches each failure mode early, and what good evidence looks like when a regulator or incident response team comes asking.
Types of AI System Monitoring
No single monitoring approach covers the full risk surface. Enterprise AI systems require overlapping layers that address the model itself, the data flowing through it, the runtime environment, and the compliance record.
Model Performance Monitoring
This layer tracks whether the model is still producing accurate, reliable, and appropriately confident outputs over time. Key metrics to watch:
- Accuracy and precision/recall — the most direct signal of output quality degradation
- Inference latency — sudden spikes typically point to infrastructure issues or model bloat
- Confidence score distributions — a shift toward lower-confidence predictions frequently precedes measurable accuracy drops
- Feature attribution changes — Google's engineering team used feature-attribution monitoring to catch a production issue caused by an infrastructure migration before it affected accuracy in a service used by billions of users

When these metrics degrade, the root cause is usually one of two things: the model needs retraining, or something upstream in the data pipeline has changed. Identifying which requires the next layer.
Data Quality Monitoring
Two drift types drive most data-related failures:
- Data drift — the statistical distribution of input features changes from what the model was trained on
- Concept drift — the relationship between inputs and the correct output shifts, even if the inputs look similar
NIST's AI Risk Management Framework flags both as reasons AI systems may require more frequent corrective maintenance than conventional software. Monitoring input feature distributions against training baselines and flagging schema anomalies in upstream pipelines is the first line of defense — catching problems before they degrade model outputs.
Security and Runtime Monitoring
Data quality monitoring addresses what flows into your model. Security monitoring addresses what your model does with it — and that's where conventional tools, built for deterministic software, fall short. They weren't designed to detect prompt injection, jailbreaks, retrieval poisoning, or an autonomous agent invoking tools outside its defined scope.
OWASP ranks prompt injection as LLM01:2025, describing it as capable of causing unauthorized access, data breaches, and compromised decision-making. Lab research has demonstrated attack success rates reaching 95% in some test conditions — a number that illustrates technical feasibility, even if production prevalence varies.
For agentic AI systems that execute real-world actions (file writes, API calls, financial transactions), the risk profile is fundamentally different from a static chatbot. Logging what happened after an agent transferred funds or modified a record does nothing to stop the damage. Enforcement has to happen before the action executes, at the decision level.
PromptHalo is built specifically for this layer. It sits inline on every inference, tool call, and agent-to-agent handoff, with each action receiving a per-action decision in under 100ms. Decisions follow a five-option enforcement model:
- Allow — action proceeds normally
- Restrict — action executes with reduced scope
- Challenge — user or system verification required
- Deny — action blocked before execution
- Monitor — action logged for review without blocking
No model access or code rewrite required. The platform integrates across any AI application from any vendor through API gateway, agent mode, or inline middleware deployment.
Compliance and Audit Monitoring
This layer translates monitoring activity into evidence. Specifically, it produces:
- Decision-level logs that capture what the model output and what input triggered it
- Model version histories and data access records
- Incident timelines with policy context attached
- Replayable records suitable for auditor submission
The EU AI Act sets a concrete bar: under Article 26, deployers of high-risk AI systems must retain logs under their control for at least six months. Raw telemetry exports don't satisfy this requirement — logs must be structured, tamper-evident, and traceable to specific decisions and applicable controls.
PromptHalo's audit logs are append-only and tamper-evident. Each entry captures the decision, the reason, the acting agent identity, session and tenant context, and a timestamp — making them replayable for incident reconstruction and regulatory reporting without requiring any retroactive reconstruction.
Warning Signs Your AI System Needs Attention
Performance or Output Degradation
- Rising error rates or declining user satisfaction scores
- A spike in low-confidence predictions
- Outputs that are technically valid but contextually wrong — for example, a customer service model giving answers that are accurate but irrelevant to the actual question
- Increasing frequency of users rephrasing the same question hoping for a better answer
These signals typically indicate concept drift or upstream data quality issues. They warrant a model review cycle, not just a dashboard refresh.
Unusual or Erratic System Behavior
Watch for:
- Agents invoking tools they weren't instructed to use
- Outputs that contradict the model's defined scope
- Repeated failed attempts at a task with no error surfaced to the user
- Inconsistent responses to the same prompt across sessions
In agentic systems, these aren't model quirks — they can be early indicators of prompt injection or adversarial manipulation. The absence of a hard error does not mean the system is operating correctly.
Security and Access Anomalies
These are distinct from performance issues and require a security response, not a model retrain:
- Abnormal inference volumes from a single identity
- Attempts to extract sensitive context from a retrieval system
- Unexpected escalation of tool permissions
- Outputs containing PII or fragments of confidential data
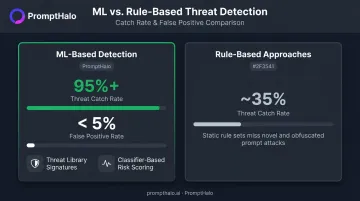
PromptHalo's ML-based detection, which combines Threat Library signatures with classifier-based risk scoring, identifies these patterns in milliseconds — achieving a catch rate above 95% at under 5% false positives, compared to roughly 35% for rule-based approaches alone.
Recurring Failures and Manual Workarounds
When users or downstream systems routinely correct AI outputs, apply manual overrides, or escalate AI decisions to humans more frequently than normal, that's a systemic signal. Not an edge case. It points to one of three root causes:
- Monitoring thresholds are misconfigured
- Coverage gaps left key behaviors unobserved
- The model has drifted past the point where earlier alerting would have caught it
AI Monitoring Best Practices
1. Establish real-time, continuous monitoring as the baseline. Periodic checks and dashboard reviews are not sufficient for production AI systems. Automated monitoring should run across all four layers at all times, with threshold-based alerts that route to the right team without requiring manual review cycles.
2. Define KPIs tied to actual business outcomes and risk tolerance. A fraud detection model needs false negative rates and decision latency tracked alongside accuracy. A customer-facing LLM needs output relevance and refusal rate monitoring. The right metrics vary by use case — and they should be revisited as the business evolves.
3. Monitor the entire AI stack, not just model output. Data pipelines, retrieval systems, tool integrations, and agent-to-agent communication channels all require coverage. Monitoring only model output leaves upstream failures invisible: the degraded output surfaces, but its origin — a poisoned retrieval result, a misconfigured pipeline, a rogue tool call — does not.
4. Implement anomaly detection with automated response workflows. Set statistical baselines for normal behavior. When deviations occur, automated responses reduce mean time to respond: session restriction, scope enforcement, or fallback routing can all trigger without waiting for a manual review cycle. PromptHalo's per-action enforcement applies allow/restrict/challenge/deny decisions inline, before the action completes, rather than logging events after the fact.
5. Maintain tamper-evident, decision-level audit logs. Logs should capture what the model returned, what input triggered it, what actions an agent took, and what policy applied at each step. This makes them replayable for incident review and suitable for auditor submission — not just raw telemetry exports.
6. Build feedback loops and a documented incident response plan. User-flagged outputs, downstream system failures, and security near-misses should feed directly into model improvement cycles. Pre-defined severity tiers, designated response owners, and structured post-incident reviews keep incidents contained and create a documented record regulators can actually use.
AI Monitoring Schedule and Cadence Guidelines
Monitoring cadence should match both the frequency of model use and the risk profile of the decisions being made. An autonomous agent executing compliance workflows requires different treatment than a low-stakes content recommendation system.
| Cadence | Monitoring Tasks |
|---|---|
| Real-time / Continuous | Security event monitoring (prompt injection, unauthorized tool calls, data leakage), inference anomaly detection, latency and error rate tracking |
| Daily | Performance metric summaries, alert triage, data pipeline integrity checks, review of flagged outputs |
| Weekly | Model drift trend analysis, user feedback review, threshold calibration, access control audit for AI system permissions |
| Monthly | Formal performance review against baselines, compliance log export for regulatory records, third-party integration security review |
| Quarterly / Annually | Full model audit including bias and fairness assessment, external validation, documentation update, incident retrospective |

For high-risk deployments — agentic systems in fintech, healthcare, or legal environments — continuous security enforcement applies to every action, not just during scheduled review windows. Platforms built for this use case, like PromptHalo, enforce this at the infrastructure level: every inference, tool call, and agent handoff passes through inline enforcement with no sampled or batched modes — so coverage gaps don't appear between review windows.
Frequently Asked Questions
What is continuous monitoring in AI?
Continuous monitoring means tracking AI system behavior, performance, and security in real time so that model drift, anomalous outputs, and adversarial attacks are caught before they cause user-facing harm or compliance failures. Unlike scheduled reviews, detection happens as events occur — not after a review cycle begins.
What are the best practices for continuous monitoring?
Core practices include:
- Define outcome-aligned KPIs before deployment
- Monitor all four layers: model performance, data quality, runtime security, and compliance
- Automate anomaly detection and alerting with layer-specific thresholds
- Maintain tamper-evident audit logs
- Build feedback loops that route monitoring signals back into model improvement cycles
How does AI monitoring differ from traditional software monitoring?
Traditional software is deterministic, so threshold-based alerting is sufficient. AI systems are probabilistic, degrade gradually, and can be manipulated through adversarial inputs in ways that never trigger a conventional alert. Threats like prompt injection require purpose-built detection — not repurposed infrastructure monitoring.
What is model drift and how do you detect it?
Model drift occurs when input distributions change (data drift) or when the relationship between inputs and correct outputs shifts (concept drift). Both cause predictions to erode in accuracy over time. Detection means continuously comparing live input distributions and output confidence patterns against baselines established at training and initial deployment.
How often should AI systems be formally reviewed or retrained?
Review frequency should be driven by drift detection signals, business changes, and regulatory requirements — not a fixed calendar. High-risk or high-volume systems may need monthly reviews; lower-risk deployments can run on quarterly cycles. Retraining should be threshold-triggered, not date-triggered.


