
Key Takeaways
- Async telemetry eliminates synchronous trace ingestion, removing monitoring latency from the critical path
- Monitor step count, tool call authorization, and TTFT inline; defer quality scoring and full trace capture to async pipelines
- Inline enforcement decisions must complete under 100ms to avoid user-perceived latency
- ML-based detection dramatically outperforms rule-based approaches on both catch rate and false positive rate
- PromptHalo makes inline blocking decisions without model access or code rewrites
Why Standard Monitoring Creates a Performance Tax on AI Agents
Picture this: a security engineer rolls out an observability layer on a production AI agent, and within hours the P95 latency dashboard climbs 30%. Nothing changed in the model or the agent logic. The culprit is the monitoring itself — a pattern that's showing up across more engineering teams as agentic AI moves into production.
Traditional APM tools weren't designed for this workload. A typical HTTP transaction emits a handful of spans: method, status code, response time. An agent running a five-step RAG retrieval with three tool calls emits token counts, model identifiers, tool sequences, prompt events, completion events, and nested spans for each reasoning step. That's a categorically different telemetry volume per request, and it compounds with every step the agent takes.
Four overhead sources stack on top of each other in agentic systems:
- Synchronous trace ingestion that blocks the execution thread waiting for the observability backend to acknowledge a write
- LLM-as-Judge evaluation adding token cost and latency to every request it runs on
- Per-step logging that multiplies linearly as agent step count grows
- Alert evaluation loops that fire on normal behavioral variance, creating noise without insight
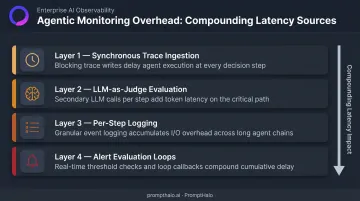
Each of these sources compounds the others — and the problem is scaling industry-wide. Gartner predicts 40% of organizations deploying AI will use dedicated AI observability tools by 2028, yet most teams adopting these tools are retrofitting general-purpose stacks onto non-deterministic, variable-depth workloads they weren't built to handle.
Low-performance-impact monitoring isn't a configuration problem — it's a design problem. The gap is between what general-purpose observability captures and what agentic workloads actually require.
Prioritizing Behavioral Signals That Actually Matter
Instrumenting everything creates overhead and noise. Instrumenting the wrong things leaves real problems invisible. The goal is a minimal set of signals with high diagnostic yield — catching the most consequential failures at the lowest instrumentation cost.
Signal 1: Agent Step Count and Loop Detection
Step count is the earliest and cheapest anomaly signal available. Research from a 2025 arXiv study on production agent behavior found that 68% of production agents execute at most 10 steps before requiring human intervention. That's your calibration baseline.
LangChain's AgentExecutor.max_iterations defaults to 15; setting it to None risks an infinite loop. OpenAI's Agents SDK raises MaxTurnsExceeded when turn limits are breached. Both frameworks treat iteration ceilings as a first-class concern — your monitoring layer should too.
A pattern check for repeated tool calls with identical parameters catches runaway behavior before it becomes a token cost problem. An arXiv catalog of 63 confirmed LLM-agent budget-overrun incidents across 18 ecosystems documented losses including approximately $2,150 over a single incident — the kind of exposure that a step-count ceiling and loop detector would prevent.
Signal 2: Tool and API Call Authorization
Every external tool call is a decision boundary where agent behavior can diverge from intent. Logging which tools were called, in what sequence, and with what parameters is lightweight relative to capturing full reasoning chains. Yet it catches the most operationally dangerous failure modes:
- Unauthorized API access
- Out-of-scope data retrieval
- Privilege escalation
OWASP LLM06:2025 explicitly recommends complete mediation and logging of all agent extension activity. Tool call logs belong on every request, not in a sampled pipeline.
Signal 3: Time-to-First-Token (TTFT)
TTFT captures user-perceived delay independently of task complexity. It's measurable with a single timestamp, adds negligible overhead, and degrades before aggregate P95 latency does, which makes it a leading indicator rather than a lagging one.
Longer prompts increase TTFT because prefill time grows with context length. Track it per step, not just at the session level, so you can isolate which step in a multi-step chain is degrading.
What to Defer or Sample
Not everything needs to run on every request:
| Signal | Frequency |
|---|---|
| Tool call logs | 100% of requests |
| Step count / loop detection | 100% of requests |
| TTFT and per-step latency | 100% of requests |
| Cost attribution tags | 100% of requests |
| LLM-as-Judge quality scoring | 10–20% sample |
| Full reasoning trace capture | Anomaly-triggered |
| RAG context precision scoring | Sampled / async |

Together, these three always-on signals give security and engineering teams the visibility they need to act — without the overhead that makes monitoring itself a liability.
Lightweight Instrumentation Techniques for Minimum Overhead
Async-First Telemetry
Synchronous trace ingestion — waiting for the observability platform to acknowledge a write before the agent continues — adds predictable latency on every step. Async, fire-and-forget telemetry emission — buffered locally and flushed in batches — eliminates that wait entirely.
MLflow's production tracing is async by default, using 10 worker threads and a queue of up to 1,000 traces. Their documentation states that asynchronous logging can reduce performance overhead by about 80% for typical workloads. LangSmith handles tracing in a background thread for the same reason.
The tradeoff: a small risk of telemetry loss on hard crashes. That's acceptable for operational metrics but not for security audit logs, which need synchronous, tamper-evident writes.
Risk-Proportional Sampling
Not every agent session requires full telemetry. A practical sampling strategy:
- Full tracing for sessions exceeding 2× the P90 cost baseline
- 10% sampled tracing for normal sessions
- 100% tracing for sessions that trigger a security signal
MLflow's MLFLOW_TRACE_SAMPLING_RATIO supports endpoint-level overrides — 0.1 for high-volume endpoints, 1.0 for critical transactions. Tag sessions with cost metadata at session start so the sampling decision can be made before trace capture begins.
Structured Metadata Over Verbose Logging
Attach structured metadata — user_id, session_id, task_id, model tier, tool sequence — to every LLM call instead of capturing raw prompt/response content. OpenTelemetry's GenAI conventions explicitly warn that gen_ai.input.messages and gen_ai.output.messages likely contain PII, recommending filtering and truncation.
Downstream aggregation and alerting on metadata dimensions costs a fraction of storing full payloads on the critical path — which matters when the tiered evaluation model below determines how much runs inline.
Tiered Evaluation Model
| Tier | What Runs | When | Mode |
|---|---|---|---|
| Tier 1 | Format validation, step count, TTFT thresholds | 100% of requests | Inline |
| Tier 2 | LLM-as-Judge quality scoring | 10–20% sample | Async |
| Tier 3 | Human review queue | Anomaly-triggered | Async |
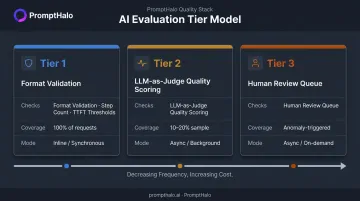
Only Tier 1 runs inline. Tiers 2 and 3 are fully async, keeping per-request overhead low without sacrificing quality visibility.
PromptHalo's Runtime Security layer takes a different approach entirely: it enforces trust on every inference, tool call, and agent-to-agent handoff — making allow/restrict/deny decisions in under 100ms, without model access or code rewrites. Teams that need inline control without the overhead of a general-purpose observability stack get enforcement that was designed for that constraint from the start.
Inline vs. Asynchronous Monitoring: Choosing the Right Mode
The fundamental tradeoff: inline monitoring runs synchronously in the agent's execution path — it can block or modify actions but adds latency. Async monitoring runs out-of-band — near-zero latency impact, but it can only observe and alert, not prevent.
Most teams need both, mapped to different signal types.
When to Run Inline
Inline is appropriate when the monitoring action must be able to prevent execution:
- Input sanitization and prompt injection detection
- Out-of-scope tool call blocking
- PII redaction before data leaves the system
- Agent-to-agent handoff authorization
The engineering constraint: inline checks must stay within a defined latency budget. Meta's Llama Prompt Guard 2 benchmarks at 19.3ms for the 22M model and 92.4ms for the 86M model on an A100 — both well within a sub-100ms budget on appropriate hardware, showing ML-based inline detection is operationally viable.
OpenAI's Agents SDK guardrails support parallel execution with the LLM call to minimize latency, with the option to set runInParallel: false when the check must block token spend before it starts.
Where inline earns its latency cost through enforcement, async earns its place through volume — handling everything that doesn't need to block execution.
When to Run Async
Async is appropriate when blocking execution provides no value:
- Cost aggregation and billing attribution
- LLM-as-Judge quality scoring
- Audit log writes for operational metrics
- Anomaly alerting that triggers human review
Moving these signals out of the critical path typically cuts monitoring-induced latency more than any other architectural change — and requires no tradeoff in observability.
Behavioral Security Monitoring Without the Latency Penalty
Security monitoring for AI agents — detecting prompt injection, jailbreak attempts, data leakage, retrieval poisoning, and unauthorized tool calls — must run inline to block threats, not just observe them. That creates the hardest engineering tradeoff in agentic security: fast enough not to degrade the user experience, thorough enough to catch real attacks.
Rule-based checks are fast but brittle. A Palo Alto Unit 42 evaluation of three major cloud guardrail platforms found input false positive rates of 0.1%, 0.6%, and 13.1% across the three systems — and the lowest false-positive platform also failed to block 51 of 123 malicious prompts, with 5 producing explicitly harmful content. High false positive rates drive alert fatigue; low catch rates leave organizations exposed. Rules force a tradeoff that ML-based detection doesn't.

An arXiv study on prompt injection defenses for LLM tutors quantified this tradeoff directly: NeMo Guardrails achieved 0% bypass at a 16.22% false positive rate with roughly 1.5 seconds of latency; a lightweight rule pipeline hit 46.34% bypass at 0% false positives in 2.5ms. Neither end of that spectrum is acceptable for production agentic systems.
PromptHalo's Runtime Security layer runs ML-based detection inline at the inference level, evaluating every prompt, tool call, and agent-to-agent handoff, with a stated catch rate above 95% at under 5% false positives. It deploys in under a day with no model retraining and no code rewrites.
The platform enforces agent security passports with authority decay: an agent's permissions automatically narrow as it operates, forcing re-authorization when risk or step thresholds are exceeded. This is structurally different from routing requests through a general-purpose API gateway that treats LLM inference as undifferentiated HTTP traffic.
That enforcement posture aligns directly with the threat model. OWASP LLM01:2025 on prompt injection notes that adversarial inputs can be imperceptible to humans and can force a model to pass compromised data to other system components — exactly the threat class that observational monitoring, by definition, catches too late.
Frequently Asked Questions
What is the performance overhead of behavior monitoring for AI agents?
Overhead depends on whether monitoring runs inline or async, and which signals are captured. For most production systems, the right baseline is async metadata tagging with sampled quality evaluation. MLflow's async tracing documentation reports roughly 80% overhead reduction compared to synchronous full-trace logging.
How is AI agent behavior monitoring different from traditional application monitoring?
Traditional monitoring tracks deterministic code paths with fixed metrics like request latency and error rate. AI agent monitoring must capture non-deterministic reasoning steps, tool call sequences, and probabilistic outputs that don't map to standard APM spans. One user request can also produce dozens of nested agent steps, each requiring its own telemetry.
Which agent behaviors are the highest priority to monitor in production?
Three signals belong on every request: tool and API call authorization (what the agent did externally), agent step count and loop detection (is it running away?), and time-to-first-token (is user experience degrading?). Everything else — quality scoring, full trace capture, RAG precision — can be sampled or deferred to async pipelines.
Can behavioral monitoring catch security threats like prompt injection in real time?
Yes, but only if the monitoring layer runs inline in the agent's execution path. Out-of-band monitoring can alert after the fact but cannot block execution. Purpose-built inline enforcement engines are required for real-time threat prevention, and they must complete checks within a sub-100ms latency budget to avoid visible degradation.
How do you reduce false positives in AI agent monitoring without missing real threats?
Risk-proportional sampling, ML-based detection rather than rigid rule thresholds, and alert baselines calibrated to normal session behavior all reduce false positive rates. Feeding confirmed incidents back into detection models continuously improves accuracy, which is the principle behind PromptHalo's closed-loop approach connecting red-teaming discovery to runtime enforcement.
What is the difference between inline and asynchronous monitoring for AI agents?
Inline monitoring runs in the agent's execution path and can block or modify actions — used for security enforcement where prevention is the goal. Async monitoring runs out-of-band with no latency impact but can only observe and alert, not prevent. Production systems need both: inline for authorization and injection detection, async for cost aggregation, quality scoring, and audit logging.


