
Introduction
Enterprises are deploying AI at scale, but the compliance frameworks and security stacks built for traditional software were never designed to handle autonomous agents, retrieval-augmented systems, or multi-model pipelines. That gap is no longer theoretical. It is where breaches happen and where regulators are starting to look.
Two failure modes define the current risk landscape. The first is an AI system that gets exploited: prompt injection redirects an agent's behavior, a poisoned knowledge base surfaces unauthorized data, an autonomous tool call exceeds its intended scope.
The second is an AI system that generates decisions regulators cannot trace or explain — no audit trail, no decision logic, no evidence that human oversight was ever in place.
Both failures are now business-critical. McKinsey's 2025 AI survey found that 88% of organizations report regular AI use, while nearly two-thirds have not begun scaling AI governance to match. Security concerns remain the top barrier to expanding agentic AI deployments.
This article covers what traditional tools miss, which regulatory frameworks apply, and what a compliance-ready AI security architecture looks like in practice.
Key Takeaways
- Traditional security tools — firewalls, DLP, SIEM — cannot inspect prompt semantics, agent tool calls, or retrieval pipelines
- Compliance-ready AI security requires pre-deployment red-teaming and runtime enforcement working together
- NIST AI RMF, OWASP LLM Top 10, and the EU AI Act form the core compliance mapping structure for regulated industries
- Audit trails must be decision-level, tamper-evident, and replayable — API-level logs do not satisfy regulators
- Build runtime enforcement early and you ship agentic AI faster — with audit-ready compliance that holds up under regulatory review
Why Traditional Security Tools Cannot Protect Enterprise AI
The enterprise security stack — firewalls, SIEM, DLP, endpoint agents, code scanners — was built for a static, deterministic attack surface. These tools inspect network packets, file hashes, and known malware signatures.
They were never designed to evaluate the semantic content of a prompt, the legitimacy of an autonomous tool call, or whether a retrieved document has been manipulated.
Structural Blind Spots in Conventional Security
When an enterprise AI agent calls an external API, the traffic looks like normal HTTPS. When it exfiltrates data through a model response, no file was transferred. When a retrieval pipeline returns a poisoned document, no signature matches anything in a threat feed.
OWASP confirms that prompt injection can manipulate model behavior even when applications use RAG or other grounding techniques — meaning the mitigation enterprises commonly rely on does not eliminate the threat. NIST's GenAI Profile adds that current testing processes "often fail to reflect real-world deployment contexts and longitudinal risks," leaving compliance teams with frameworks that assume detection capabilities that don't yet exist.
These attacks target prompt semantics, retrieved content, model behavior, and agent authority — objects that conventional network, endpoint, and DLP controls were never built to inspect.
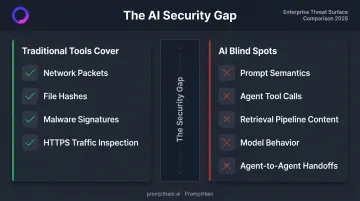
The Cost of Applying Legacy Frameworks to Agentic AI
When security teams try to retrofit existing controls to agentic AI, three operational problems emerge:
- Rule-based systems flag legitimate agent actions they cannot distinguish from misuse, burying analysts in false-positive noise
- Approved workflows get blocked because rules lack the context to understand what an agent is actually authorized to do
- Auditors require decision-level logs, but conventional systems capture only network-layer events — leaving compliance gaps that frameworks can't paper over
Multi-agent architectures expose a deeper gap. When one agent passes context or credentials to another, no existing firewall, DLP, or SIEM was designed to inspect or enforce trust at that handoff point — and that handoff is precisely where authority escalation and context poisoning attacks occur.
PromptHalo's ML-based detection operates at the semantic level — inline on every inference, tool call, and agent-to-agent handoff — delivering a 95%+ catch rate with under 5% false positives. Rule-based approaches, by contrast, generate far higher false alarm rates while leaving agentic behavior entirely uncovered.
The AI-Native Threat Landscape Compliance Teams Must Understand
Every threat category below is both a security failure and a compliance failure. Regulators are already asking about them — and compliance teams that don't understand the attack surface can't build systems to defend it.
Prompt Injection and Jailbreaks
Prompt injection occurs when attacker-controlled input redirects an agent's behavior by overriding its instructions. Jailbreaks use crafted inputs to bypass a model's operational guardrails. NIST defines prompt injection as "exploiting concatenation of untrusted input with a prompt built by a higher-trust party" — meaning the attack crosses trust boundaries inside the application itself.
If an agent executes an unauthorized action because its instructions were overridden, neither the organization nor the regulator can establish what the system actually did or why. Accountability breaks down — and with it, any audit trail regulators would need.
Research from the AgentDojo benchmark — which evaluated attacks across 97 realistic tasks and 629 security test cases — found that one defense reduced attack success rate to 8% in controlled testing. The gap between defended and undefended systems is significant, but undefended agentic workflows remain highly vulnerable.
Data Leakage and Retrieval Poisoning
Data leakage in AI differs from traditional exfiltration: sensitive information can be embedded directly in model responses without triggering standard DLP rules. No file transfer occurs. No signature matches.
Retrieval poisoning in RAG architectures adds another layer. PoisonedRAG research demonstrated that injecting five malicious texts per target question into a knowledge base with millions of entries achieved a 90% attack success rate — reaching 97% on Natural Questions and 99% on HotpotQA in black-box settings. Enterprise knowledge bases must be treated as security boundaries, not just data stores.
Unmonitored retrieval pipelines make it impossible to demonstrate data minimization or access controls to regulators under GDPR or the EU AI Act — two requirements that appear in nearly every enterprise AI compliance review.
Out-of-Scope Tool Calls and Agentic Overreach
Autonomous agents can execute tool calls or API interactions that fall outside their intended scope — an AI assistant with read access attempting a write operation, or an agent escalating its own permissions across a multi-agent handoff. OWASP categorizes this as Excessive Agency: damaging actions that result when systems have too much functionality, too many permissions, or too much autonomy relative to their defined role.
The failure is both technical and regulatory. Overreach violates least privilege, may constitute unauthorized data processing under GDPR or the EU AI Act, and leaves no explainable decision record for auditors or regulators to review.
Key Regulatory Frameworks Governing Enterprise AI Security
Enterprise AI now operates under multiple overlapping regulations, not a single unified standard. The common thread across all of them: transparency, explainability, human oversight, and documented risk management. Most security teams are managing three or more frameworks at once.
The Three Core Frameworks
| Framework | Core Requirement | Key Detail |
|---|---|---|
| NIST AI RMF | Risk governance across four functions | Govern, Map, Measure, Manage — the baseline most enterprise AI programs reference |
| OWASP LLM Top 10 | Technical threat taxonomy for LLM deployments | Covers Prompt Injection, Sensitive Information Disclosure, Data Poisoning, Excessive Agency — already referenced in auditor assessments |
| EU AI Act | Risk-tiered compliance with mandatory controls | High-risk systems must meet logging (Article 12), documentation, human oversight, and cybersecurity requirements; deployers must retain logs for at least six months (Article 26) |

The Multi-Framework Reality
Most enterprises subject to the EU AI Act also operate under GDPR, SOC 2, and sector-specific rules:
- DORA applies to financial institutions and requires a documented ICT risk management framework covering any AI-supported functions
- HIPAA applies when AI processes protected health information
- CCPA/CPRA now includes risk assessments and consumer rights for automated decision-making (California regulations adopted July 2025)
Compliance-ready AI security architecture needs to generate evidence that maps to all of these frameworks simultaneously, not rebuilt from scratch for each audit cycle.
Building a Compliance-Ready AI Security Architecture
Compliance-ready AI security operates in two distinct phases that must work together: pre-deployment red-teaming to find exploitable attack paths before production, and runtime enforcement to govern every agent decision, tool call, and handoff after deployment. Testing without runtime enforcement leaves live systems unprotected. Runtime enforcement without prior red-teaming misses architectural vulnerabilities baked in before deployment. Both are required.
Pre-Deployment Red-Teaming for AI Systems
NIST defines AI red-teaming as "a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with developers." In practice, this means systematically probing an AI application the way an attacker would.
Red-teaming for AI targets a different surface than traditional penetration testing:
- Prompt injection vectors across direct and indirect (retrieval-based) paths
- Jailbreak susceptibility across multi-turn conversations and instruction chaining
- Retrieval pipeline manipulation in RAG knowledge bases
- Agent authority boundaries across single-agent and multi-agent workflows
- Adversarial task chains across multi-step agentic processes
From a compliance perspective, the output of a red-team exercise should be a mapped inventory of exploitable attack paths, a risk classification of each finding against OWASP LLM Top 10 or NIST AI RMF, and a remediation plan that security teams and auditors can review. That evidence package is what regulators and enterprise customers increasingly expect before an AI system enters production.
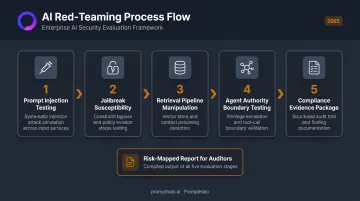
PromptHalo's red-teaming capability continuously attacks an organization's agents, RAG layers, and tool chains, delivering results as risk-mapped reports with prioritized, actionable fixes — not raw findings that leave interpretation to your team.
Red-teaming reveals what's exploitable. Runtime enforcement is what stops it from being exploited in production.
Runtime Enforcement Across the Agentic Stack
Runtime enforcement means inline inspection and policy enforcement on every inference, tool call, and agent-to-agent handoff, with the ability to allow, restrict, challenge, deny, or monitor in real time. Enforcement must operate at the semantic level, not just the network level.
Three specific controls form the core of a compliance-ready runtime enforcement layer:
- Per-action budget and scope limits: tracked across time, steps, and risk level, blocking requests that exceed configured thresholds before they execute
- Authority decay: permissions automatically diminish as an agent operates, forcing re-authorization when predefined envelopes are exceeded — preventing privilege accumulation across sessions and handoffs
- Security passports: cryptographically signed credentials that travel with each request, carrying the agent's identity, authorized scope, and policy constraints for verification at each decision point

These controls map directly to compliance requirements: least privilege, human oversight, and demonstrable access governance.
PromptHalo's runtime enforcement engine makes per-action decisions in under 100ms across every agent action and handoff. Every attack discovered during red-teaming feeds a shared threat library that trains the runtime detection engine, so each new attack pattern strengthens enforcement automatically.
Deployment takes under a day with no model retraining and no code rewrite, through API gateway integration, orchestration platform connection, or inline middleware embedding.
Audit Trails and Governance: Making Compliance Verifiable
Compliance is not demonstrated by having controls in place. It is demonstrated by showing, in detail, what happened, why, and what decision logic was applied. For AI systems, that requires audit trails captured at the agent action level, not just at the API call or user session level.
What Regulators and Auditors Actually Need to See
A compliance-grade AI audit trail must satisfy four characteristics:
| Requirement | What It Means |
|---|---|
| Decision-level | Captures each agent action and the context that produced it, not just input/output pairs at the API boundary |
| Tamper-evident | Logs are append-only and cannot be modified after the fact |
| Replayable | Auditors can reconstruct the full sequence of events across multi-step agent workflows |
| Framework-mapped | Each logged event can be referenced against OWASP LLM Top 10, NIST AI RMF, or EU AI Act requirements |
EU AI Act Article 12 explicitly requires high-risk AI systems to technically allow automatic event logging over their lifetime. Article 26 requires deployers to preserve logs for at least six months. Traditional application logs that capture only API-level input/output pairs do not meet these requirements.
PromptHalo generates tamper-evident, decision-level audit logs capturing the reason for each decision, the acting agent identity, session and tenant context, and timestamp. The result is a replayable evidence trail built for regulatory reporting and post-incident investigation.
The Governance Layer Above the Audit Trail
A technical audit trail only delivers value when a governance structure exists to act on what it reveals. Mature organizations maintain a cross-functional oversight function spanning security, legal, compliance, and AI operations. That function typically handles:
- Setting AI risk tolerance thresholds across the organization
- Reviewing high-impact use cases before deployment
- Conducting ongoing monitoring with defined criteria for human review
- Establishing clear ownership over what audit logs reveal and who responds
This structure maps directly to the NIST AI RMF Govern function, which applies across all AI risk management processes and procedures. Without it, even excellent audit logs sit in a system with no clear accountability for what they expose.
Frequently Asked Questions
What is the 30% rule for AI?
No authoritative regulatory source has verified a formal "30% rule" for AI-generated content or AI-assisted decisions. The term circulates as an informal internal policy threshold at some organizations. The EU AI Act instead uses risk-based human oversight requirements for high-risk systems, without specifying a percentage threshold.
Who offers compliance-ready AI data management tools?
Compliance-ready AI data management spans GRC platforms (IBM watsonx.governance, Centraleyes), AI governance tools (Credo AI, Holistic AI), and runtime security platforms like PromptHalo — each addressing a different layer, from policy workflows and data governance to real-time agent enforcement and decision-level audit logging.
What regulations apply to enterprise AI systems in the United States?
Key frameworks include NIST AI RMF, OWASP LLM Top 10, and sector-specific rules: DORA for financial institutions, HIPAA for healthcare, and GLBA/FTC Safeguards for financial data. California's CPPA adopted automated decision-making regulations in July 2025; the EU AI Act applies to any organization processing EU residents' data.
What is the difference between AI governance and AI security?
AI governance defines the policies, oversight structures, and accountability frameworks for how AI systems are built and used. AI security implements the technical controls that enforce those policies at runtime, prevent attacks, and generate the evidence governance requires. Both are necessary: without security, governance has no enforcement mechanism; without governance, security has no defined policy to apply.
Can existing security tools like firewalls and DLP protect enterprise AI deployments?
No. Traditional tools operate at the network and file level and cannot inspect the semantic content of prompts, agent tool calls, or retrieval pipelines. AI-native threats — prompt injection, retrieval poisoning, agentic overreach — are invisible to these tools. Purpose-built runtime enforcement operating at the semantic level is required.
How do you demonstrate AI compliance to regulators and enterprise customers?
By maintaining decision-level, tamper-evident audit logs mapped to recognized frameworks, conducting documented pre-deployment red-teaming, and implementing runtime controls with clear policy definitions. Every agent action must be explainable, traceable, and verifiable — not just the API calls surrounding it.


