
Introduction
When an AI agent makes a bad decision, most organizations cannot answer three basic questions: What did the agent decide? Why did it decide that? Which action did it actually take?
This is the accountability gap in agentic AI. Unlike traditional software — where every function call is deterministic and traceable — AI agents receive a prompt, retrieve external context, invoke tools, pass instructions to sub-agents, and produce outcomes, all without a human reviewing each step. When something goes wrong, there is often no trail to follow.
AI agent audit trails are not the same as general inference logs or financial record-keeping — and this guide is built around that distinction. Agentic audit trails must capture the full autonomous decision chain: inferences, tool calls, RAG retrievals, multi-agent handoffs, and authority state at each step.
Gartner predicts over 40% of agentic AI projects will be canceled by end-2027 due to escalating costs, unclear business value, or inadequate risk controls. Audit trail gaps are a core risk driver.
By the end of this guide, you will know what an AI agent audit trail must capture, how it maps to the EU AI Act, NIST AI RMF, and OWASP LLM Top 10, and how to build tamper-evident logging that satisfies regulators and security teams alike.
Key Takeaways
- AI agent audit trails must capture decision-level events — not just inference inputs and outputs
- Treat multi-agent handoffs, RAG retrievals, and tool calls as first-class audit events — not optional metadata
- EU AI Act Article 12 requires automatic logging, with a minimum six-month retention obligation for both providers and deployers
- Tamper-evidence requires append-only storage and integrity verification; retrofitting after deployment won't satisfy regulators
- Only decision-level logs let you reconstruct agentic attacks like prompt injection and retrieval poisoning after the fact
What Makes AI Agent Audit Trails Different from Traditional AI Logging
Traditional AI audit logs were designed for supervised models: record the training run, log the model version, capture the inference input and output. A human reviewed the output before anything happened downstream. That design assumption no longer holds.
The Autonomous Decision Chain Problem
An AI agent operates in a continuous chain. It receives a prompt, queries a knowledge base, decides which tool to invoke, acts on the result, and may pass instructions to a sub-agent — all within a single run. Traditional inference logs capture the start and the end. Everything in the middle — where tool calls fire, retrievals get injected, and sub-agents receive delegated authority — is invisible to conventional logs. That's where most agentic AI risk concentrates.
The new audit surfaces unique to agentic AI include:
- Tool calls and API invocations — what the agent invoked, what parameters it passed, and what happened before and after execution
- RAG retrievals — which documents were retrieved, from which source, and what context was injected into the prompt
- Agent-to-agent handoffs — when one agent delegates to another, including what authority was transferred and what instruction was passed

The Multi-Agent Accountability Gap
In multi-agent systems, Agent A can instruct Agent B to take an action. If that action causes harm, standard logs cannot reconstruct who held authority at the moment of the decision. ACM research on autonomous systems describes this as a "responsibility gap," driven by three compounding factors:
- Causal distance between the original designers and the downstream outcome
- Diluted agency spread across multiple teams and system components
- Unpredictable emergent behavior from agents acting on delegated instructions
The result: no log, no owner, no answer to the question of which agent was actually responsible.
Existing security tools — firewalls, DLP, code scanners — operate at the network or data layer. They cannot observe an agent's internal reasoning, its decision to invoke a specific tool, or whether a RAG retrieval was poisoned before the agent acted on it. This gap is architectural — and closing it requires audit infrastructure designed specifically for the agentic decision layer.
What AI Agent Audit Trails Must Capture
Decision-Level Events
For every inference, the audit record should include:
- Full prompt context (system prompt, user input, retrieved context)
- Model version and configuration active at decision time
- The agent's response or action decision
- Outcome classification: allow, restrict, challenge, deny, or monitor
The outcome classification is what makes a log forensically useful. Knowing what the agent produced is not enough. You need to know what it decided to do and whether that decision was constrained.
For every tool call and API invocation, log:
- Tool name and call ID
- Parameters passed
- System state before execution
- Result returned
- Latency
This pre/post-execution record is the only way to prove the agent acted within its authorized scope — and the only way to reconstruct unauthorized actions after the fact.
Agent Identity and Authority Scope
Authority in agentic systems is not static. It decays over a session as the agent consumes its action budget. Logs must capture the authority state at each decision step, not just at session start.
PromptHalo handles this through agent security passports: signed credentials that travel with each request, carrying policy, budget, and authority decay state. Every decision records the acting agent's passport identity, the scope constraints in effect, and the remaining budget. When a budget envelope is exceeded, re-authorization is forced and logged.
RAG Retrievals and Multi-Agent Handoffs
Log RAG retrievals as first-class audit events:
- Which knowledge sources were queried
- What documents were retrieved
- What context was injected into the prompt
OWASP LLM08:2025 (Vector and Embedding Weaknesses) recommends detailed, immutable logs of retrieval activities. Without retrieval-level logs, it is impossible to distinguish a hallucination from a retrieval-based manipulation.
For multi-agent handoffs, the audit record should capture:
- Instructing agent ID
- Receiving agent ID
- Instruction passed
- Scope granted to the receiving agent
- Timestamp
This creates an auditable delegation chain across complex multi-agent workflows — exactly the chain-of-custody record regulators and incident investigators require.
Security Signals as Audit Events
Security signals — prompt injection attempts, jailbreak patterns, out-of-scope tool calls, guardrail triggers — belong in the audit trail, not in a separate security log. When they live in the same stream as decision events, investigators can correlate an attack pattern with the specific agent decision it influenced. Siloed security logs make that correlation nearly impossible after the fact.
Mapping AI Agent Audit Trails to Regulatory Frameworks
EU AI Act Article 12
Article 12 requires high-risk AI systems to enable automatic event recording over the system lifetime. For Annex III systems, logs must cover the start and end of each use, reference databases checked, input data matches, and the identity of any natural persons involved in result verification.
On retention: both providers and deployers must retain logs under their control for a minimum of six months, per Articles 19 and 26(6), unless EU or national law specifies otherwise. Technical documentation and quality-management records face a stricter standard — 10 years after the system is placed on the market.
The practical implication for agentic AI: every consequential decision must be reconstructable from the log. A log that captures only inference inputs and outputs does not satisfy this standard.
NIST AI RMF
The NIST AI RMF identifies transparency and traceability as core characteristics of trustworthy AI. Its four functions map directly to audit trail requirements:
| RMF Function | Audit Trail Application |
|---|---|
| Govern | Logging policy, roles, and authority definitions |
| Map | Documenting agent context, intended use, and scope |
| Measure | Monitoring records and evaluation outputs |
| Manage | Incident response evidence and remediation records |
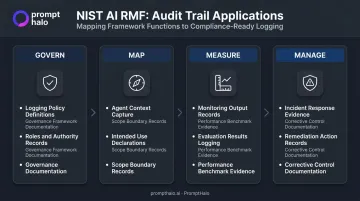
NIST AI 600-1 (Generative AI Profile) adds requirements for data provenance, continuous monitoring, and policies to record errors, near misses, and negative impacts — requirements that apply directly to agentic deployments.
OWASP LLM Top 10 (2025)
Decision-level audit logs provide direct evidence of defense against the OWASP LLM categories most relevant to agents:
- LLM01 (Prompt Injection): Logs of retrieved context, system prompt boundaries, and blocked/allowed actions show whether injection attempts were detected and how the agent responded
- LLM06 (Excessive Agency): Tool call logs with scope constraints and authority state demonstrate that agent permissions were enforced and monitored
- LLM08 (Vector and Embedding Weaknesses): Immutable retrieval logs show which documents were consulted and whether the retrieval index was in an authorized state
Financial Services: SR 11-7
SR 11-7 (Federal Reserve/OCC model risk management guidance) requires documented model validation, ongoing monitoring, and outcomes analysis. While SR 26-2 (2026) explicitly excludes generative and agentic AI from its scope, SR 11-7 remains the operative framework for model risk governance in financial services AI deployments.
AI agent audit trails satisfy SR 11-7 obligations by providing a time-stamped, attributable record of every decision the agent made in a regulated workflow — giving examiners and internal validators the evidence they need without reconstructing events after the fact.
Electronic record retention requirements for financial services add further specificity:
- SEC Rule 17a-4: Six years for most broker-dealer records (three years for certain record types); WORM storage required
- FINRA Rule 4511: Six-year default where no other retention period applies
- Both rules: Require a complete time-stamped audit trail capturing any modifications, deletions, time, and identity of the actor
The Three-Layer Audit Architecture for Agentic AI
Capture Layer
Deploy lightweight emitters at every agent decision point: inference, tool invocation, RAG retrieval, guardrail event, and agent-to-agent handoff. The critical design requirement is that emitters must fire inline — before the action executes — not after. This ensures blocked and modified actions are captured alongside permitted ones.
PromptHalo's enforcement runs inline, deciding allow, restrict, or deny in under 100ms for every inference, tool call, and handoff. Blocked actions are logged at the same level of detail as permitted ones — and that equal treatment extends to governance events. Approvals, scope changes, and configuration updates belong in the same event stream as technical events, not in separate documentation.
Store Layer
Stored logs must be tamper-evident. The standard approaches are:
- Append-only storage: Once written, records cannot be modified or deleted
- Hash chaining: Each record includes a cryptographic hash of the previous record, making any deletion or modification detectable
- Role-based access controls to prevent unauthorized reads or writes
- Write-once retention policies for regulated environments

SEC and FINRA frameworks permit either WORM storage or a complete time-stamped audit trail that records any modification, the time of modification, and who made it. Either approach satisfies the tamper-evidence standard for regulated financial records.
PromptHalo's audit logs are append-only and tamper-evident by design. Once an event is written, it cannot be modified or removed.
Use Layer
The stored log must support three distinct use cases:
- Auditor-facing querying — filter by agent ID, action type, time window, or outcome classification
- Integrity verification — replay the event chain to confirm the trail is complete and unaltered
- Regulatory reporting exports — bounded subsets of events with integrity metadata attached
Replayability is what separates a compliance artifact from a security investigation tool. Regulators don't want a summary — they want to reconstruct every decision, in order, with evidence that the sequence is complete and unaltered.
Security Threats That Only Audit Trails Can Surface
Prompt Injection Leaving Traces Without Triggering Guardrails
NIST AI 100-2e2025 defines indirect prompt injection as attacks through modified external resources — web pages, documents — ingested at runtime. NIST's own red-teaming research increased attack success rates from 11% to 81% for the strongest new attack methods.
Some prompt injection attempts will not trigger guardrails. But they leave traces: an instruction embedded in retrieved context that subtly altered the agent's next tool call, a shift in the tool call sequence that follows a specific retrieval event. Decision-level logs allow security teams to identify these influence patterns retrospectively, even when the attack was not blocked in real time.
Retrieval Poisoning in RAG Systems
Without retrieval-level logs, a poisoned RAG document and a hallucination look identical from the outside — both produce an unexpected output. With retrieval logs that capture which documents were retrieved, from which index, and at what time, investigators can determine whether the agent acted on unauthorized or modified content.
OWASP LLM08:2025 specifically recommends immutable logs of retrieval activities for this reason.
Anomalous Tool Call Sequences
Standard security stacks log what happened at the perimeter — they don't capture what an agent decided to do, or why. Anomalous tool call sequences exploit that blind spot. These patterns include:
- Invoking a tool the agent has never used before
- Calling an API outside its authorized scope
- Chaining tool calls in a sequence that resembles a known attack pattern
Decision-level audit logs provide the forensic evidence needed to investigate and report each of these cases. PromptHalo's replayable audit logs are specifically designed for this: the platform continuously red-teams agent tool chains, and discovered attack patterns train the ML detection engine used for runtime defense — reaching a 95% catch rate at under 5% false positives, compared to roughly 35% for rule-based approaches.
Best Practices for Implementing Compliant AI Agent Audit Trails
Log at the Decision Level, Not Just the Inference Level
The difference matters in practice. Consider an agent that calls a payment API:
- Inference-level log: Input prompt → output text. No record of which API was called, what parameters were passed, or whether the agent had authorization.
- Decision-level log: Agent identity, authority scope at decision time, tool invoked (payment API), parameters passed (amount, recipient, currency), outcome classification (allow/deny), result, timestamp.

The decision-level log is what you need for a regulatory inquiry. The inference-level log tells you almost nothing about what the agent actually did.
Build Tamper-Evidence In from the Start
Hash chaining, cryptographic signing, and append-only storage must be architectural decisions made before deployment. Retroactively applying tamper-evidence to existing logs does not satisfy regulatory evidentiary standards. A log that can be modified cannot serve as evidence in regulatory or legal proceedings.
The practical implication: tamper-evident audit logging needs to be operational before an agentic AI system goes to production, not bolted on afterward.
Map Logs to Regulatory Frameworks at Design Time
Identify which frameworks apply before deploying agents, then configure the audit trail schema to capture what each framework requires. The frameworks do not share identical field requirements:
- EU AI Act needs: event timeline, retrieval/database references, verifier identity
- NIST AI RMF needs: context, actor, scope, monitoring outcomes, incident records
- SR 11-7 needs: decision attribution, validation records, ongoing monitoring evidence
- OWASP LLM Top 10 needs: tool call scope, retrieval sources, guardrail outcomes
Reactive logging — adding fields when a regulator asks — creates gaps that cannot be filled retroactively. Events that were not captured at decision time are gone.
Frequently Asked Questions
What is the difference between an AI agent audit trail and standard AI logging?
Standard AI logging records inference inputs and outputs. An AI agent audit trail captures the full autonomous decision chain — tool calls, RAG retrievals, multi-agent handoffs, and the authority state at each step. This makes it possible to reconstruct why an agent took a specific action, not just what it produced.
What regulatory frameworks require audit trails for AI agents?
The EU AI Act (Article 12) mandates automatic logging for high-risk AI systems, with minimum six-month retention for both providers and deployers. NIST AI RMF, SR 11-7 (financial services model risk), and OWASP LLM Top 10 each identify traceability and decision-level logging as core requirements.
What should an AI agent audit trail capture at minimum?
Every decision event should capture:
- Agent identity, action type, inputs/outputs, and tool or API invoked
- Authority scope at decision time, timestamp, and outcome classification (allow/restrict/challenge/deny/monitor)
- RAG retrieval sources and multi-agent handoff chains for any agentic workflow
How do you make AI agent audit logs tamper-evident without slowing production systems?
Hash chaining — where each log entry includes a cryptographic hash of the previous entry — makes any deletion or modification detectable without synchronous external verification. Combined with append-only storage and role-based access controls, this adds minimal latency while satisfying regulatory evidentiary standards.
How long should AI agent audit trail records be retained?
The EU AI Act requires six months for operational logs and ten years for technical documentation. SEC Rule 17a-4 and FINRA Rule 4511 both default to six years for broker-dealer records. Retention policy must be set before deployment — logs that weren't preserved cannot be reconstructed after the fact.
How do audit trails help detect and investigate agentic AI attacks like prompt injection?
Decision-level audit logs allow security teams to trace an anomalous agent action back through the full decision chain — identifying whether a prompt injection in retrieved context, a poisoned RAG document, or an out-of-scope tool call was the root cause. Without a replayable chain of evidence, post-incident investigation is impossible and regulatory reporting cannot be substantiated.


