Introduction
GenAI deployments are accelerating faster than most security teams can respond. According to Gartner, more than 80% of enterprises will have used GenAI APIs or deployed GenAI-enabled applications by 2026. The risk frameworks meant to govern those deployments haven't kept pace. The Cloud Security Alliance's 2025 research found that 34% of organizations with AI workloads had already experienced an AI-related breach.
Two distinct problems sit at the center of this challenge. Organizations face immediate risks the moment they deploy GenAI — hallucination, data leakage, adversarial attacks, compliance exposure. Most also lack the structured controls to manage those risks at scale.
This guide addresses both dimensions: what the risks actually are, and how to build frameworks and enforcement mechanisms that go beyond policy documents and governance slides.
Key Takeaways:
- Traditional security tools weren't built for GenAI's unpredictable outputs and agentic autonomy
- Core risk categories include hallucination, data privacy, adversarial attacks, compliance gaps, and third-party supply chain exposure
- Agentic AI amplifies every risk category — one compromised inference can cascade across entire workflows
- Runtime enforcement matters more than governance policy alone
- NIST AI RMF, OWASP LLM Top 10, and the EU AI Act are the frameworks to anchor your program
What Makes Generative AI Different from a Risk Perspective
Traditional software executes explicit instructions. A GenAI model reasons across unstructured inputs, generates outputs that weren't explicitly programmed, and can respond differently to semantically similar prompts.
That non-determinism creates a control gap. Rule-based systems like fraud detection follow auditable logic. GenAI behavior is harder to predict, constrain, or verify using those same conventional controls.
The Shift from Tool to Agent
The risk profile compounds significantly when GenAI moves from answering questions to taking actions. An agentic AI system doesn't just generate text — it calls external APIs, reads internal databases, chains decisions across multi-step workflows, and operates with minimal human checkpoints between each step.
A static model returning a wrong answer is a nuisance. An agent acting on a wrong inference is a different problem: it can trigger unauthorized transactions, exfiltrate sensitive data, or escalate its own privileges before any human has a chance to intervene.
Regulatory Response
Regulators have noticed this distinction. The EU AI Act, which entered into force on August 1, 2024, defines AI systems by their ability to "operate with varying levels of autonomy" and "generate outputs such as predictions, content, recommendations, or decisions." High-risk classifications and mandatory controls follow directly from that definition.
The NIST AI RMF and its GenAI-specific profile, NIST AI 600-1, take a different approach — a voluntary framework structured across four functions:
- Govern — establish accountability and risk culture
- Map — identify AI risks in context
- Measure — analyze and assess those risks
- Manage — prioritize and respond to them
The EU AI Act carries direct legal obligation. The NIST AI RMF is voluntary in name, but for organizations in regulated industries, it's increasingly expected by auditors and regulators in practice.
The Core Risk Categories Every GenAI Deployment Faces
Hallucination and Output Reliability
GenAI models produce confident, fluent outputs that can be factually wrong. In low-stakes contexts, that's an inconvenience. In regulated workflows, it's a liability.
Research published in the Journal of Legal Analysis found that leading LLMs hallucinated legal information at rates between 69% and 88% on specific legal queries. The real-world consequences aren't hypothetical — in Mata v. Avianca, a federal judge sanctioned attorneys $5,000 after they filed briefs citing fake cases generated by ChatGPT.
Financial reporting, compliance documentation, and medical contexts carry the same exposure: anywhere accuracy has regulatory or reputational consequences, hallucinations aren't just a technical problem.
Data Privacy and Leakage
Hallucinations are a model-side problem. Data privacy failures are a human-side one — and they're just as common. When employees use GenAI tools, whether public models or enterprise deployments, they routinely enter sensitive information without understanding where it goes. The Samsung incident in 2023 demonstrated this clearly: engineers accidentally leaked proprietary source code and internal meeting notes into ChatGPT.
The regulatory exposure from these incidents is significant. GDPR, HIPAA, and financial data regulations all impose obligations on how sensitive data is handled, stored, and processed. The FTC has made clear that AI companies that mishandle data in ways inconsistent with their privacy commitments will face enforcement action.
Adversarial Attacks
Data leakage involves accidental exposure. Adversarial attacks are deliberate — and they're already being exploited in production environments. The OWASP LLM Top 10 (2025) documents active, exploitable attack vectors that enterprises face today:
- Prompt injection — malicious instructions embedded in user input or retrieved content that hijack model behavior
- Jailbreaks — techniques that bypass safety guardrails to elicit prohibited outputs
- Data and model poisoning — corrupting training data or retrieved context to manipulate model behavior
- System prompt leakage — exposing confidential instructions that define the model's behavior

OWASP classifies prompt injection as LLM01, the top risk, noting it can lead to unauthorized access, data breaches, and compromised decision-making.
Compliance and Regulatory Risk
These attacks create direct compliance exposure. GenAI outputs used in regulated workflows must often meet explainability, fairness, and auditability standards that most deployments cannot currently satisfy:
- EU AI Act Annex III classifies AI systems used for creditworthiness evaluation and HR decisions (recruitment, termination, promotion) as high-risk, requiring mandatory risk management, documentation, and human oversight
- CFPB guidance requires lenders using AI models to provide specific, accurate reasons for adverse credit actions — generic explanations don't satisfy the obligation
- SEC enforcement has already produced $400,000 in civil penalties against investment advisers who made misleading statements about their AI use
Third-Party and Supply Chain Risk
Compliance obligations assume your AI systems behave as intended. Third-party dependencies make that assumption fragile. Most enterprise GenAI deployments rely on third-party model providers, vector databases, retrieval systems, and software libraries — each of which introduces its own trust gaps.
Research published at USENIX Security 2025 demonstrated that attackers can achieve 90% attack success by injecting just five malicious texts into a knowledge base containing millions of entries. These retrieval poisoning attacks corrupt what the model acts on, and they're invisible to conventional security scanning.
Agentic AI Risks: The Threat Surface Your Security Stack Can't See
Static GenAI returns an output. Agentic AI executes a plan — and that distinction changes the entire risk calculus.
An agentic system autonomously plans, uses tools, calls APIs, retrieves from live data sources, and chains multi-step decisions with minimal human checkpoints. A single compromised inference doesn't just produce a bad answer — it can cascade across an entire workflow before anyone notices something went wrong.
Prompt Injection in Agentic Contexts
In a standard chatbot, a prompt injection attack returns a flawed response. In an agentic system, the same attack can:
- Execute unauthorized API calls to external endpoints
- Exfiltrate data to attacker-controlled locations
- Escalate privileges by instructing the agent to access resources beyond its scope
- Trigger real transactions or downstream actions in connected systems
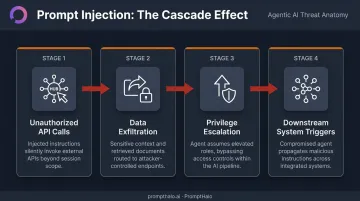
The mechanism: malicious instructions embedded in documents, emails, websites, or RAG-retrieved content that the agent processes as trusted input. The agent follows attacker commands instead of intended ones — often without any visible signal to the user or the model itself.
Retrieval Poisoning (RAG Attacks)
Retrieval-augmented generation (RAG) systems retrieve external content to ground model responses. Attackers exploit this by planting malicious content inside documents, databases, or knowledge bases that an agent retrieves at runtime. The agent acts on corrupted context without detecting it — and conventional security scanning has no mechanism to evaluate the semantic intent of retrieved text.
The ConfusedPilot research demonstrated this concretely: documents used as attack vectors against RAG-based enterprise assistants like Microsoft 365 Copilot create what researchers call "confused deputy" risks, where the model is manipulated into acting against user intent.
Multi-Agent Handoff Risks
When multiple AI agents communicate and delegate tasks, trust must be established at every handoff — not just at the perimeter. Research on "Prompt Infection" showed that malicious prompts can self-replicate across interconnected agents like a computer virus, propagating through an entire multi-agent system from a single point of compromise.
Current enterprise architectures rarely enforce trust at this layer. Standard API gateway controls authenticate sessions, not individual actions — leaving the handoff between agents as a largely unmonitored attack surface.
Addressing this gap requires enforcement at the handoff layer itself. PromptHalo does this through agent security passports: signed, verifiable credentials that travel with each request, carrying:
- Per-agent policy and scope boundaries
- Budget and authority limits that decay over the chain
- Re-authorization triggers when an agent's envelope is exceeded
When a compromised agent attempts to propagate malicious instructions downstream, the passport mechanism intercepts it before the next agent acts.
Why Traditional Security Tools Weren't Built for GenAI
Firewalls, DLP tools, and code scanners were designed around structured, deterministic inputs and outputs. They inspect packets, match patterns against signatures, and enforce rules based on known content types. None of that applies to the semantic content of a prompt, the intent behind a model's tool call, or the safety of a retrieved document.
Specifically, traditional tools cannot:
- Evaluate whether a prompt contains adversarial instructions — they have no concept of prompt semantics
- Detect retrieval poisoning — they cannot assess whether content retrieved from a knowledge base has been tampered with
- Audit agent decision chains — they produce no record of individual inferences, tool calls, or handoff decisions
- Enforce per-action agent authority — they authenticate sessions, not individual actions within workflows

Gartner has stated directly that conventional DLP cannot effectively manage GenAI data loss risks, including exposure through encrypted traffic, intent blindness, and context limitations. Forrester similarly identifies prompt injection, jailbreaking, and data leakage as scenarios requiring AI-specific security controls — not adaptations of existing ones.
The visibility gap compounds every other problem. IBM's 2025 data breach research found that 97% of AI-related breaches involved AI systems lacking proper access controls. Without decision-level logging, most organizations cannot reconstruct what happened at the agent level after a breach — leaving them exposed on both the security and regulatory reporting fronts.
Building a Generative AI Risk Management Framework
Align to Established Standards First
Three frameworks should anchor any enterprise GenAI risk program:
| Framework | What It Covers | Practical Requirement |
|---|---|---|
| NIST AI RMF | Govern, Map, Measure, Manage | Accountability structures, explainability, continuous monitoring |
| OWASP LLM Top 10 | Technical attack surface | Controls against prompt injection, RAG attacks, excessive agency |
| EU AI Act | Regulatory classification | High-risk determination, mandatory documentation, human oversight |
The starting point is mapping existing GenAI use cases against these frameworks. Which deployments qualify as high-risk under EU AI Act Annex III? Which OWASP LLM Top 10 categories lack technical controls? Where does NIST's governance function identify gaps in accountability or monitoring? That mapping exercise produces a prioritized remediation list — specific gaps, ranked by exposure — not a generic compliance checklist.
Build Governance Before Scaling
Governance needs to precede scale. That means establishing AI use policies, defining acceptable use boundaries, assigning ownership across CISO, CRO, CCO, and legal, and creating a review process for new AI deployments before they reach production.
Red-teaming is a non-negotiable part of that process. NIST AI 600-1 explicitly recommends adversarial role-playing and GenAI red-teaming to surface failure modes that governance documents cannot reveal. CISA and the UK NCSC's joint guidelines state organizations should release AI systems only after appropriate security evaluation, including red teaming. Executive Order 14110 went further, requiring certain foundation model developers to provide the government with red-team results.
Pre-deployment red-teaming should cover:
- Prompt injection attempts targeting instruction override
- Jailbreak probes designed to bypass content and policy controls
- Data exfiltration scenarios that test whether sensitive outputs leak through agent tool calls

Each of these attack paths, if left untested, tends to surface in production — found by attackers rather than your team. And once a system is live, the cost of discovery rises sharply. That's where continuous monitoring picks up.
Maintain Continuous Monitoring Post-Deployment
GenAI risk management is not a one-time assessment. Model behavior can drift, attack techniques evolve, and regulatory requirements change. Organizations need:
- Continuous monitoring of model outputs, agent actions, and tool calls
- Alerting when behavior falls outside defined parameters
- Regular re-validation of controls against updated threat intelligence
- Audit trails that satisfy regulatory reporting requirements when something does go wrong
From Policy to Enforcement: Making AI Trust Operational
A governance policy that says "agents should not access out-of-scope data" provides zero protection without a technical control that evaluates each data access request at the moment it occurs. Without runtime enforcement, governance is just documentation.
What Runtime Enforcement Requires
Effective runtime AI security enforcement means inline inspection of every prompt, inference, tool call, and agent-to-agent handoff — with the ability to allow, restrict, challenge, deny, or monitor each action in real time based on risk context. It must operate at inference speed — under 100ms — to be practical in production without adding latency that degrades user experience.
That enforcement layer must also:
- Apply custom governance policies at the point of action, not after delivery
- Produce decision-level audit logs that capture the reason, agent identity, session context, and timestamp for every action
- Detect and block prompt injection, retrieval poisoning, and out-of-scope tool calls before they execute
- Generate compliance evidence that maps to OWASP LLM Top 10, NIST AI RMF, and EU AI Act requirements
How PromptHalo Delivers This
PromptHalo provides this enforcement layer, deploying in under a day without model retraining or code rewrites. Its Policy Enforcement Engine lets enterprises define custom rules that flag, log, or block AI responses in real time — covering every inference, tool call, and agent-to-agent handoff across any AI application from any vendor.
Detection combines Threat Library signatures with classifier-based risk scoring, achieving a catch rate above 95% at under 5% false positives. Attacks discovered through red-teaming are encoded directly into the shared Threat Library, so protection compounds over time without waiting on release cycles.
For regulated industries, every decision is captured in an append-only, tamper-evident audit log with the reason, acting agent identity, session context, and timestamp — replayable for incident investigation and formatted for regulatory reporting.
Frequently Asked Questions
What are the most critical risks of deploying generative AI in an enterprise?
Four categories dominate: hallucination and unreliable outputs, data privacy and leakage, adversarial attacks (prompt injection, jailbreaks), and compliance gaps in regulated workflows. Agentic deployments add tool misuse and cascade failures, where one compromised inference triggers real-world consequences across connected systems.
How is agentic AI risk different from standard GenAI risk?
Agentic AI introduces autonomous action: tool calls, API execution, and multi-step decision chains. A compromised inference can trigger unauthorized transactions, exfiltrate data, or escalate privileges before any human checkpoint catches it.
What is prompt injection and why does it matter for AI security?
Prompt injection embeds malicious instructions in user input or retrieved content, causing the model to follow attacker commands instead of intended ones. In agentic systems, this goes beyond wrong answers — it can trigger unauthorized tool execution or privilege escalation with real operational impact.
Which compliance frameworks should organizations use for generative AI risk management?
The three primary frameworks are NIST AI RMF (governance, accountability, and monitoring), OWASP LLM Top 10 (technical attack surface coverage), and the EU AI Act (regulatory classification and mandatory controls for high-risk use cases). Most mature programs anchor to all three.
Can existing security tools like DLP or firewalls protect against generative AI risks?
No. Traditional tools were designed for deterministic, structured systems and cannot inspect semantic prompt content, evaluate inference-time context, or detect retrieval poisoning. They produce no audit trail of agent decisions and have no mechanism to enforce per-action authority. Purpose-built AI security tooling is necessary for adequate coverage.
How should organizations handle third-party generative AI risk?
Assess vendors for data handling practices, model transparency, and security posture, and include AI-specific clauses in contracts covering data retention and usage. Beyond contract terms, implement technical controls that monitor and govern what data flows to and from third-party AI services in real time.