
Introduction
Enterprise AI deployments — internal copilots, RAG-powered assistants, agentic workflows — now sit at the center of sensitive business operations. Yet most organizations secure them the way they'd secure a file server: perimeter controls, DLP rules, access logs. That mismatch is where data leakage risk lives.
AI systems process information differently from anything conventional security was designed to handle. They retrieve, infer, summarize, and act on data in ways that bypass traditional controls entirely. A junior employee can receive a summary of executive financial records through a perfectly normal prompt. An agent can exfiltrate customer data through a tool call that looks identical to legitimate usage — and neither a firewall nor a DLP rule will catch it.
These aren't edge cases. They're the default behavior of systems your organization is already running in production.
According to McKinsey's 2025 State of AI report, 88% of organizations now use AI in at least one business function — yet only 1% describe themselves as mature in AI deployment. That governance gap is the attack surface.
This article covers a practical framework for evaluating data leakage risk across the full enterprise AI attack surface: identifying exposure points, scoring risk, testing actively, and enforcing controls that actually work.
Key Takeaways
- Enterprise AI leakage spans prompts, RAG retrieval, agent tool calls, memory stores, and logs
- Traditional DLP was built for email, USB, and file transfer; it can't see AI-native leakage paths
- Effective risk evaluation maps data flows, scores exposure, and stress-tests findings adversarially
- Agentic AI compounds leakage risk because agents operate autonomously across systems with minimal human oversight
- Regulated industries carry overlapping compliance obligations — GDPR, HIPAA, PCI DSS, EU AI Act — the moment AI touches sensitive data
What Makes AI Data Leakage Risk Evaluation Different
Data leakage risk evaluation in the AI context is a structured process for identifying where sensitive information can be unintentionally exposed through AI system components — prompts, outputs, retrieval layers, agent actions, memory, logs, and API integrations — and quantifying the likelihood and business impact of each exposure path.
Traditional data loss prevention monitors known channels using pattern matching — credit card numbers in emails, SSNs in file transfers, source code on USB drives. AI data leakage bypasses every one of those checkpoints. Sensitive content emerges through:
- Semantically transformed outputs that don't match any pattern rule
- Vector database retrievals that return unauthorized content without triggering access logs
- Autonomous agent tool calls that look identical to legitimate AI usage
OWASP and NIST both identify these AI-specific leakage paths as requiring application-layer and model-system controls — not rule-based detection. No authoritative public benchmark exists for what percentage of AI leakage events legacy DLP misses, but the structural gaps are well-documented across both frameworks.
This evaluation also isn't a one-time audit. Enterprise AI systems evolve continuously. New data sources get indexed, new agents get connected, model behavior drifts. Risk evaluation has to be a repeatable practice tied to the AI system lifecycle — not a checkbox completed at deployment.
The Enterprise AI Data Leakage Attack Surface
Before scoring or mitigating risk, security teams need to understand where leakage can actually originate. Five distinct layers each require a different evaluation lens — and most organizations have blind spots in at least three of them.
Prompt and Output Layer
Sensitive data enters AI systems constantly through user prompts — source code, customer records, financial data, credentials. Employees frequently don't distinguish between enterprise-managed AI accounts and consumer-tier tools.
The scale of this problem is measurable. Harmonic Security's analysis of 22 million enterprise AI prompts found that 8.5% contained sensitive information — categories including customer data, employee records, financial details, and proprietary source code. Cyberhaven's telemetry puts the figure even higher at 39.7% of AI interactions involving sensitive data. Both are vendor measurements, but the pattern is consistent: sensitive data flows into AI systems at significant scale.

On the output side, models can surface retrieved or inferred information outside intended scope — returning content a user was never authorized to request, based on what was semantically close to their query.
RAG and Vector Database Layer
Retrieval-augmented generation introduces a risk that most organizations don't anticipate: retrieval authorization operates as a distinct control point, separate from document-level access controls. If a RAG system indexes too broadly, or fails to enforce document-level, role-level, or tenant-level permissions, the model may summarize content a user was never authorized to see.
The underlying problem is that vector databases often flatten permission hierarchies during embedding. A document that required executive clearance in SharePoint may have no such restriction at the vector layer. The query returns it; the model summarizes it; the user reads it.
OWASP LLM08:2025 identifies vector and embedding weaknesses as a significant RAG risk, specifically citing unauthorized access to sensitive information through manipulated or over-indexed embeddings.
Agentic and Tool Call Layer
AI agents that can call APIs, query databases, access SaaS platforms, and trigger workflow actions create the most expansive leakage surface. Several factors compound the risk:
- Agents typically operate with service-account-level permissions far broader than any individual user
- Prompt injection can redirect agents to return unauthorized data or execute unsafe tool calls
- Multi-agent handoffs can carry sensitive context across system boundaries without inspection
Gartner forecasts that 40% of enterprise applications will integrate task-specific AI agents by end of 2026, up from less than 5% in 2025. Separately, Gartner projects 15% of day-to-day work decisions will be made autonomously by agentic AI by 2028. That's a large and rapidly expanding tool-call surface with limited governance infrastructure behind it.
A Cloud Security Alliance study commissioned by Zenity found that 53% of organizations had AI agents exceed their intended permissions. The commissioned methodology warrants some caution, but the figure aligns with what security teams are observing in practice.
Memory and Log Layer
AI systems generate new data stores that organizations routinely under-classify. Prompt logs, completion logs, conversation memory, tool traces, and analytics pipelines frequently contain:
- Customer PII and financial records
- Source code and internal strategy documents
- Credentials passed through prompts
- Regulated health information
EU AI Act Article 12 requires automatic logging for high-risk AI systems. HIPAA's Security Rule requires safeguards for electronic PHI wherever it's stored. PCI DSS Requirement 10 mandates logging and monitoring of cardholder data access.
The moment a prompt log captures any of this content, it becomes subject to the same compliance obligations as any other regulated data store — whether or not the organization has classified it that way.
Cloud and SaaS Integration Layer
Enterprise AI systems connected to cloud storage, CRM, EHR, ticketing, and data warehouse platforms inherit access risk from every integration. Common failure modes include:
- IAM misconfigurations that grant AI systems broader access than intended
- Overpowered service accounts with no tenant or department boundaries
- Weak role mapping that allows cross-group data retrieval with no audit trail
Without visibility into what the AI accessed or why, these exposures can go undetected indefinitely.
How to Evaluate Data Leakage Risk: A Six-Step Process
AI data leakage risk evaluation follows a structured sequence. Most organizations stop after the first two steps, leaving the most dangerous exposure paths completely unvalidated.
Step 1 — Inventory Your AI Systems and Data Flows
Document every AI system in the environment: model interfaces, RAG pipelines, agent frameworks, connected APIs, SaaS integrations, vector databases, memory stores, and log sinks. Don't omit shadow AI tools employees use without IT approval. These often carry the highest risk precisely because they lack any oversight.
For each system, map what data it can access, process, retrieve, store, and return. That mapping determines which exposure points need scrutiny in the steps ahead.
Step 2 — Classify Sensitive Data Exposure Points
Against the inventory, identify where each category of sensitive data could enter or exit the AI system:
- PII and customer records — GDPR, HIPAA obligations
- Financial data and cardholder information — PCI DSS obligations
- Source code and proprietary business data — IP and confidentiality risk
- Credentials — lateral movement and privilege escalation risk
- Regulated health information — HIPAA Privacy and Security Rule obligations
This step reveals which AI components touch data carrying active compliance obligations.
Step 3 — Score Leakage Risk by Likelihood and Impact
Apply a risk scoring model across each exposure point:
| Dimension | High | Medium | Low |
|---|---|---|---|
| Likelihood | Easily triggered, no authentication | Requires insider access | Theoretical only |
| Impact | Regulated data, broad user exposure | Internal data, limited scope | Non-sensitive content |
| Priority | Act immediately | Schedule remediation | Monitor |
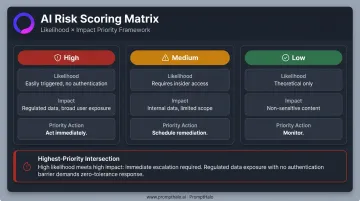
The highest-priority scenarios are where high likelihood meets high impact — for example, a RAG system over-indexing on HR or financial data with weak retrieval authorization in a regulated environment.
Step 4 — Actively Test the Attack Surface
Risk scores are only as useful as the testing behind them. Leakage paths must be validated adversarially. Testing should cover:
- Direct and indirect prompt injection for data extraction
- RAG access control bypass across user roles and tenants
- Agent tool permission abuse and scope boundary testing
- Memory and log content review for sensitive data capture
- Cloud and SaaS integration authorization gaps
One way to cover this surface systematically: PromptHalo's AI red teaming tests agents, RAG layers, and tool chains the way a real adversary would, across prompt injection, jailbreaks, poisoning, and data-leakage probes in multi-step workflows. Findings are delivered as reports mapped to specific risk scenarios with prioritized fixes, not raw vulnerability lists.
Step 5 — Define Controls and Enforce Least Privilege
Translate validated risks into specific controls. The most reliable controls operate outside the model — in the access control, retrieval, and tool governance layers:
- Retrieval authorization enforcement at the document and tenant level
- Least-privilege scoping for agent tool permissions, with authority decay over time
- Output filtering for sensitive content before responses reach users
- Protected logging with retention limits and access controls
- Data classification that feeds into AI-aware policy enforcement

Prompt engineering is not a substitute for any of these — it can be bypassed; external enforcement cannot.
Step 6 — Establish Continuous Monitoring and Re-Evaluation Triggers
Ongoing monitoring should include:
- Tracking prompt and output logs for sensitive content patterns
- Monitoring agent behavior for anomalous tool calls or data access
- Auditing RAG retrieval results against expected authorization scope
- Behavioral drift detection across sessions — subtle shifts that compound into compliance failures
Re-evaluation should trigger on any material change: new data sources indexed, new agents connected, model updates, or new regulatory requirements. Annual cycles are too slow for systems that evolve continuously. Monitoring outputs should map to audit trail requirements under OWASP LLM Top 10, NIST AI RMF, and EU AI Act reporting obligations.
A Regulated Industry Example: Financial Services RAG
Consider a financial services organization that deploys an internal AI assistant connected to a RAG system indexed across customer account data, transaction histories, and internal compliance documentation.
The risk evaluation process reveals a critical gap: the RAG system retrieves documents based on semantic relevance rather than enforcing user-level authorization. A junior employee querying the system for "Q3 compliance summary" can receive a synthesized response drawing from executive-level financial records — because those documents are semantically relevant, even if the user was never authorized to access them directly.
Active adversarial testing confirms the path. A prompt injection attempt embedded in an indexed compliance document redirects the AI to return content outside the user's authorization scope — a scenario that passive review or a policy checklist would never surface.
With both the retrieval gap and the injection path now documented, the control response targets each exposed layer:
- Retrieval authorization enforced at the document level, not just at login
- The agent's service account scoped to minimum required permissions
- Output filtering added before responses reach end users
- All evaluation findings logged with a tamper-evident audit trail mapped to PCI DSS and EU AI Act obligations
Organizations that skip active testing — and rely on policy checklists or login-layer controls alone — leave exactly this type of path open. The financial services example shows why evaluation has to follow the data through the full retrieval and response chain, not just verify that access controls exist at the front door.
How PromptHalo Evaluates and Contains AI Data Leakage Risk
PromptHalo is a purpose-built runtime security platform for the agentic AI attack surface — the layer that traditional firewalls, DLP, and code scanners were never designed to see.
Built on a test-then-trust model, PromptHalo red-teams your AI to find exploitable data leakage paths, then enforces trust on every agent action at runtime. Both capabilities share a threat library, so attack patterns discovered during red teaming feed directly into runtime defense — no release cycle required.
Key operational capabilities for security and compliance teams:
- Inline protection on every inference, tool call, and agent-to-agent handoff — allow, restrict, challenge, deny, or monitor decisions made in under 100ms
- ML-based detection at over 95% catch rate and under 5% false positives, combining threat library signatures with classifier-based risk scoring
- Agent security passports that travel with each request, with embedded policy, per-action budget enforcement, and authority decay — ensuring agents can't accumulate permissions beyond their intended scope
- Evidence-grade, tamper-evident audit logs at the decision level, capturing the decision, reason, agent identity, session context, and timestamp in an append-only structure
- Deploys in under a day with no model retraining and no code rewrite, connecting via API gateway, agent mode, or inline middleware
For fintech, payments, and enterprise compliance teams, those capabilities translate directly into risk quantification at scale. Every agent decision generates a replayable audit trail that security teams and regulators can inspect.
Because PromptHalo never touches the underlying model, it runs across any AI application, regardless of vendor — no proprietary access required.
Conclusion
Evaluating data leakage risk in enterprise AI is not a one-time exercise or a compliance checklist. It requires mapping the full attack surface across every AI system layer, scoring exposure by likelihood and impact, and validating findings through adversarial testing. Organizations that skip active testing don't have a risk posture — they have a gap they haven't measured yet.
As AI systems gain greater autonomy — adding agents, expanding tool access, and pulling from more data sources — the evaluation process has to keep pace. Enterprises that build repeatable, continuous risk evaluation practices now will deploy AI faster, with a security and compliance story that holds up when regulators ask questions. Platforms like PromptHalo are built for exactly this: continuous runtime monitoring that catches leakage vectors across every inference, tool call, and agent handoff — so the evaluation never stops when deployment begins.
Frequently Asked Questions
What is data leakage risk evaluation in enterprise AI deployments?
It's a structured process for identifying, scoring, and validating where sensitive data can be unintentionally exposed across AI system components: prompts, RAG retrieval, agent tool calls, memory, logs, and cloud integrations. The findings get translated into prioritized controls. Unlike a one-time audit, it's a continuous practice tied to the AI system lifecycle.
How is AI data leakage different from what traditional DLP tools catch?
Legacy DLP monitors known channels (email, USB, file transfer) using pattern matching. AI data leakage occurs through semantically transformed outputs, vector database retrievals, and autonomous agent actions that look identical to normal usage. No pattern-matching rule can reliably catch content that has been retrieved, inferred, and summarized by a model.
Which AI system components carry the highest data leakage risk?
RAG systems with weak retrieval authorization, agentic workflows with over-permissioned tool access, and prompt and completion logs that capture sensitive inputs are the highest-risk components — especially when connected to regulated data sources like customer records, financial systems, or health information.
How do agentic AI systems expand the data leakage attack surface?
Agents can autonomously call APIs, query databases, and chain actions across systems using service-account-level permissions far broader than any individual user. A single compromised agent or successful prompt injection can expose data across multiple systems simultaneously, with no human review between steps.
What compliance frameworks apply to AI data leakage in regulated industries?
GDPR, HIPAA, PCI DSS, and the EU AI Act all impose obligations when sensitive data is processed or exposed through AI systems. The EU AI Act adds specific requirements for high-risk deployments: risk management documentation, technical logging, and human oversight mechanisms covering logs, outputs, and retrieval results.
How often should organizations re-evaluate AI data leakage risk?
Continuous monitoring is the baseline. Formal re-evaluation should be triggered by any material change : new data sources indexed, new agents or tools connected, model updates, or new regulatory requirements. Fixed annual cycles are too slow for AI systems that evolve on shorter timescales.


