
Introduction
Machine learning models are not self-maintaining systems. Once deployed, they encounter a world that keeps changing — new customer behaviors, evolving fraud tactics, shifting demographic mixes — while the model itself stays frozen in the past. The result is silent degradation: predictions erode without warning, and nothing in your system flags it.
This problem is particularly consequential for data scientists, ML engineers, security teams, and enterprises in regulated industries. A 2021 Bank of England survey found that 35% of UK banks reported negative impacts on ML model performance from COVID-19 alone — a stark illustration of how fast real-world shocks can degrade deployed models.
This article covers:
- What model drift is and why it happens
- The four main types you need to know
- Statistical methods for detection and measurement
- Actionable solutions — including what changes when AI agents and LLMs are involved
Key Takeaways
- Model drift is the gradual degradation of ML model performance caused by changes in data distributions or real-world relationships after deployment
- Four primary types exist: concept drift, data/feature drift, prediction drift, and label drift
- Detection methods span statistical tests, distribution distance metrics, and model-based classifiers — each suited to different drift types
- In agentic AI, drift compounds across sequential decisions — one early shift can cascade through an entire automated workflow
- No monitoring system eliminates drift; the goal is catching it early, before silent degradation reaches your users or your regulators
What Is Model Drift?
IBM defines model drift (also called model decay) as the degradation of model performance caused by changes in data or in the relationships between input and output variables. The core mechanism is straightforward: models are trained on historical data that captures the world at a specific point in time. Once deployed, the live world changes. The model doesn't automatically update, and a growing gap opens between what it learned and what it now sees.
Model Drift vs. Data Drift
These terms are often used interchangeably, but they mean different things:
- Data drift specifically refers to changes in input feature distributions (P(X)) — the statistical profile of what's flowing into the model
- Model drift is the broader term covering shifts in input distributions, output predictions, and actual model accuracy
Model Drift vs. Training-Serving Skew
Another distinction worth clarifying: training-serving skew is a mismatch between training and production data that appears immediately after deployment, often caused by feature engineering inconsistencies or preprocessing differences. Drift, by contrast, is a gradual divergence that develops over months of operation.
Google Cloud distinguishes these explicitly: skew detection requires the original training dataset; drift detection does not.
The Feedback Delay Problem
Even when drift is actively occurring, teams often can't measure it directly — because ground truth labels aren't available in real time. Research on credit card fraud detection confirms this pattern across industries:
- Credit card fraud: labels surface days later, after customers report unauthorized payments
- Loan defaults: outcomes aren't known for months after origination
- Clinical results: patient outcomes follow long after the model's prediction
Because of these delays, proxy signals like distribution monitoring and output tracking aren't a fallback option. They're the primary detection mechanism.
Types of Model Drift
Concept Drift
Concept drift occurs when the underlying relationship between inputs and the target variable changes — P(Y|X) shifts. The rules the model learned no longer hold in the current world.
Bayram et al. identify three sub-patterns:
- Sudden drift — an abrupt change in the target distribution (a pandemic reshaping purchasing behavior overnight)
- Gradual drift — slow transition between concepts over time (spam techniques evolving incrementally)
- Recurring/seasonal drift — cyclical patterns that may be sudden, gradual, or incremental depending on timing
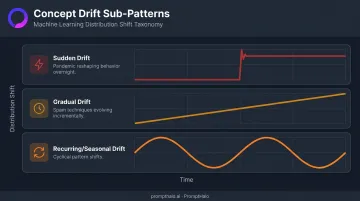
This is the most dangerous drift type. The model's decision boundary is fundamentally wrong — not just imprecise.
Data Drift / Covariate Shift
Covariate shift refers to changes in P(X): the distribution of input features changes, even if the underlying relationship between inputs and outputs hasn't. A model trained on one demographic mix might encounter an entirely different customer segment after geographic expansion.
Healthcare models face this when population risk-factor distributions shift — for example, falling tobacco use gradually changing cardiovascular-disease prevalence over years.
Prediction Drift
Prediction drift tracks changes in P(Ŷ) — the distribution of what the model outputs, independent of whether you can measure accuracy. This makes it a valuable leading indicator.
A fraud detection model suddenly flagging transactions at twice the normal rate is worth investigating immediately — whether it reflects a genuine fraud spike or model degradation, the signal demands attention. Microsoft Azure lists prediction drift as one of four core signals monitored in production.
Label Drift and Upstream/Operational Drift
Label drift (prior-probability shift) refers to changes in P(Y) — the actual distribution of target values. Credit-risk research documented default probability rising from 0.056 pre-pandemic to 0.079 during the pandemic, a real-world shift in label distribution that can undermine model calibration without any change in input features.
Upstream/operational drift is fundamentally different: it stems from changes in the data pipeline itself — a unit conversion (USD to EUR), a new data source with different encoding, or a broken feature engineering step. Unlike environmental drift, this usually indicates a data engineering bug rather than a real-world change. It should trigger investigation, not automatic retraining.
How to Detect Model Drift
Statistical Hypothesis Tests
Two tests form the baseline for distribution comparison:
- Kolmogorov-Smirnov (K-S) test — a nonparametric test that compares empirical distribution functions for continuous features. It produces a p-value indicating whether two samples could reasonably have come from the same distribution. Its nonparametric nature makes it flexible across data types without requiring distributional assumptions.
- Chi-square test — applied to categorical or binned features, testing whether observed frequencies match expected distributions. Requires adequate sample sizes for the approximation to hold.
Both tests answer a binary question: is drift present? They don't tell you how much.
Distribution Distance Metrics
These metrics produce a continuous drift score — useful for tracking drift magnitude over time, not just detecting its presence:
| Metric | Best For | Notes |
|---|---|---|
| Population Stability Index (PSI) | Financial services credit monitoring | PSI < 0.1 = stable; 0.1–0.25 = investigate; > 0.25 = significant action needed |
| KL Divergence | Small sample comparisons | Measures relative entropy; asymmetric — direction matters |
| Jensen-Shannon Divergence | Zero-probability bins | Symmetric variant of KL; more robust to sparse distributions |
| Wasserstein Distance | Outlier-heavy data | Earth Mover's Distance; quantifies the "work" to transform one distribution into another |

Summary Statistics and Rule-Based Checks
Simpler approaches that trade statistical rigor for speed:
- Summary statistics monitoring — tracking mean, median, variance, and quantiles against thresholds (e.g., alert if a feature mean moves more than two standard deviations from baseline). Fast to implement, but can miss distributional shape changes while individual statistics look stable.
- Rule-based checks — business heuristics like "alert if the fraud prediction rate exceeds X%" or "flag if a new categorical value appears in a key feature." Not statistically rigorous, but fast, interpretable, and often the first line of defense.
Model-Based Drift Detection
When rule-based checks aren't catching enough, train a binary classifier to distinguish between a reference dataset and the current production dataset. If the classifier achieves high accuracy, the distributions are meaningfully different — drift has occurred. This approach surfaces subtle multivariate shifts that univariate tests miss, at the cost of explainability: telling a stakeholder "the classifier says so" rarely satisfies a post-incident review.
Two detection patterns worth knowing for specific contexts:
- Classifier-based detection — best for batch pipelines where you can afford the compute and need to catch complex, correlated feature shifts.
- Page-Hinkley method — monitors running means in streaming data and signals when observed values diverge beyond a threshold. Well-suited to real-time production environments where latency matters.
Model Drift in Agentic AI and LLM Systems
Traditional ML drift monitoring was designed for structured, tabular data. In LLM and agentic AI systems, the signals are fundamentally different:
- Embedding drift — semantic meaning in user inputs shifts over time; standard statistical tests can't directly detect changes in high-dimensional embedding space
- Prompt/input drift — the mix of task types sent to the model changes, altering what the model is being asked to do
- Output quality drift — measured through automated evaluators rather than ground truth labels
The Compounding Risk in Agentic Systems
Unlike a static prediction model, an AI agent makes sequential decisions : tool calls, API interactions, multi-agent handoffs. Drift at one step propagates and amplifies downstream. A 2026 arXiv benchmark studying multi-turn model handoffs reported single-turn handoff changes of -8 to +13 percentage points in strict success rates , a variance that compounds across multi-step workflows.
PoisonedRAG research demonstrated that attackers can corrupt model outputs by injecting malicious content into a RAG knowledge base, achieving 90% attack success by injecting just five malicious texts among millions of documents. The model weights never change , yet agent behavior drifts entirely from poisoned retrieval. Standard drift monitoring misses this entirely.
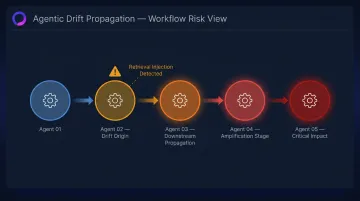
Where Runtime Enforcement Fits
Statistical monitoring can tell you that behavior has shifted. It cannot stop an out-of-scope tool call or a poisoned retrieval response before it executes.
PromptHalo's runtime security layer addresses exactly this gap, sitting inline on every inference, tool call, and agent-to-agent handoff. Key enforcement capabilities include:
- Makes allow, restrict, challenge, deny, or monitor decisions in under 100ms
- Tracks behavioral changes session over session using per-tenant memory state
- Detects gradual output drift before it compounds into compliance exposure
- Operates without accessing proprietary model weights
The platform's security passport and authority decay mechanism adds a second layer: agent permissions automatically degrade over time, steps, and accumulated risk, forcing re-authorization when thresholds are exceeded. This limits how much damage behavioral drift can cause during a live session, even before detection catches up. Enforcement runs entirely at the inference and action layer.
Solutions: How to Prevent and Address Model Drift
Continuous Automated Monitoring
Manual periodic checks aren't sufficient for production ML. Effective monitoring requires:
- Scheduled or streaming drift metric computation against a stable reference window
- Alerts tied to feature importance — drift in low-importance features rarely warrants team attention
- Logged drift events with enough context for root cause analysis
- Separate tracking for input distributions, output distributions, and performance metrics where ground truth is available
For enterprises in regulated industries, this logging layer also feeds compliance workflows — automated pipelines like those in Google Cloud's MLOps architecture and AWS SageMaker can trigger retraining workflows when drift thresholds are crossed, with each event captured for audit purposes.
Model Retraining Strategies
When drift is confirmed, retraining options depend on how fundamentally the distribution has shifted:
- Retrain on combined data — blend old and new data when the shift is partial; preserves historical signal
- Recency weighting — train on all available data but weight recent observations more heavily
- Retrain on new data only — when distributions have shifted fundamentally and historical data is actively misleading
- Model redesign — when the underlying task has changed enough that the original architecture is no longer appropriate

None of these options work without validated, labeled data — which teams often can't source immediately. In the gap before retraining is complete, consider lowering decision thresholds, routing affected segments to human review, or temporarily halting predictions where confidence is insufficient.
Proactive Design for Drift Resilience
Upstream choices at training time reduce drift sensitivity:
- Filter volatile features — features that shift frequently add noise without improving stability
- Bucket continuous variables — converting continuous values to stable categories reduces sensitivity to gradual distributional creep
- Prefer generalizable architectures — models that sacrifice some launch-day accuracy for robustness often outperform highly tuned but brittle alternatives over a 12-month production lifecycle
- Use adaptive ensemble methods — sliding windows and adaptive ensembles, as covered in recent non-stationary learning research, provide practical tools for maintaining accuracy in evolving environments
Frequently Asked Questions
What is model drift detection?
Model drift detection is the practice of continuously monitoring a deployed ML model's inputs, outputs, and performance metrics to identify when the model's behavior has diverged from its training baseline. It uses statistical tests, distance metrics, or rule-based checks to catch degradation before it causes business harm.
How do you calculate model drift?
Drift is calculated by comparing the statistical distribution of current production data against a reference dataset. Common metrics include PSI, KL divergence, JS divergence, Wasserstein distance, and the K-S test — each producing a score or p-value that quantifies how far the distributions have diverged.
How can model drift be prevented?
Drift can't be fully eliminated, but it can be managed. The core approaches are continuous monitoring, trigger-based retraining on fresh labeled data, and feature engineering choices that reduce volatility — such as bucketing or removing high-variance inputs.
What is the difference between model drift and concept drift?
Model drift is the broader term for any degradation in model performance over time. Concept drift specifically refers to a change in the relationship between input features and the target variable (P(Y|X)) — meaning the model's learned decision boundary no longer reflects how the world actually works.
How does model drift affect AI in regulated industries?
In regulated environments, undetected drift creates compliance exposure, not just accuracy problems. Frameworks like the EU AI Act (Article 72) and Federal Reserve SR 11-7 require demonstrable ongoing model validity. Organizations need audit trails showing when drift was detected, what action was taken, and how performance was restored.


