
For enterprise AI teams, this matters in a specific way: by the time outputs visibly degrade, reliability has eroded, user trust has fractured, and compliance exposure may already exist. Gartner predicted in 2024 that at least 30% of GenAI projects would be abandoned after proof of concept by end of 2025 — with poor data quality and inadequate risk controls cited as primary drivers. Drift sits at the center of both.
This article covers the four main causes of LLM drift, the consequences of leaving it unaddressed, and how to build a layered detection and prevention strategy that keeps your models reliable in production.
Key Takeaways
- Data drift occurs when production inputs diverge from training data, causing silent, cumulative model degradation.
- Causes range from organic language evolution and domain terminology changes to adversarial manipulation and shifting user behavior.
- Undetected drift leads to accuracy loss, increased hallucinations, and compliance risk — particularly severe in regulated industries.
- Detection requires layering statistical, semantic, and performance-based monitoring — no single method catches every drift pattern.
- Long-term control requires automated alerting, fresh retrieval pipelines, and human oversight where decisions carry real stakes.
Common Causes of Data Drift in LLMs
Before addressing causes, it helps to distinguish two related but distinct phenomena:
- Data drift — a statistical change in the distribution of inputs (users asking about new topics, using new terminology, adopting different syntax)
- Concept drift — a shift in the correct answer for similar-looking inputs (the right regulatory guidance changes even though the query phrasing stays the same)
Both degrade LLM performance, but at different rates and through different mechanisms. LLMs are especially vulnerable because they operate on language, which evolves constantly, making them far more susceptible to drift than narrowly scoped ML models.

Societal and Cultural Language Shifts
Language evolves through demographic changes, new slang, political movements, and shifting social norms. These changes alter both how users phrase queries and what they expect a model to understand.
A customer service LLM trained on formal, structured language may start receiving queries rich in casual phrasing or emoji-adjacent syntax. Confidence scores drop. Routing decisions become less reliable. The model isn't broken — it's just operating outside the distribution it was built for.
Domain-Specific Terminology Updates
Specialized fields (finance, healthcare, law, technology) regularly introduce new regulations, product names, and technical concepts. A domain-tuned LLM trained on data from 18 months ago may have no representation of those concepts at all.
This is particularly risky in regulated industries. A 2025 medical knowledge drift study found that GPT-4o endorsed current clinical guidance strongly (ECDA_adh of 0.90) but rejected outdated advice much less reliably (ECDA_rej of 0.395). The model wasn't confidently wrong — it was uncertain about what to discard. That quiet uncertainty is more dangerous than a clear error, because it's harder to detect and correct.
Adversarial Attacks and Retrieval Poisoning
Not all drift is organic. Malicious actors can deliberately introduce manipulated inputs through prompt injection, adversarial examples, or corrupted retrieval data to systematically skew model behavior over time.
OWASP LLM04 identifies data and model poisoning as a top LLM risk: poisoning pre-training, fine-tuning, or embedding data can introduce backdoors, insert biases, or degrade performance in ways that remain dormant until triggered. Unlike organic drift, adversarial drift can be targeted, rapid, and deliberately designed to avoid triggering standard performance alerts.
Shifting User Behavior Patterns
As a product scales or expands to new user segments, the nature of interactions changes. Users ask more complex questions, shift topics entirely, or use the system in ways that weren't anticipated during design.
The input distribution drifts from the training baseline, but because the change is gradual, it reads as noise rather than signal. This makes shifting user behavior the type of drift that goes undetected the longest.
What Happens When Data Drift Goes Unaddressed
Three consequences compound over time when drift isn't caught:
- Accuracy loss — outputs become irrelevant, outdated, or factually incorrect relative to current context
- Behavioral drift — the model hallucinates details, references superseded policies, or recommends unsupported actions
- Compliance and safety risk — in finance, healthcare, and legal services, incorrect outputs can trigger regulatory violations or reputational damage

The GPT-4 behavior study published in Harvard Data Science Review provides a concrete example of how fast this can happen: GPT-4's accuracy on a prime-number identification task fell from 83.6% to 35.2% between March and June 2023, and directly executable code output dropped from 52% to 10% over the same period — with no changes to the application code. Vendor-hosted model updates created drift that most teams wouldn't have been monitoring for.
The Adversarial Drift Problem Is Different
When drift is induced through retrieval poisoning or prompt injection rather than organic data shift, it becomes an active attack vector. The output structure looks normal — no obvious error codes, no alert triggers — while the content is being systematically compromised. Conventional statistical monitoring misses this because it monitors distributions, not intent.
PromptHalo is built specifically for this attack surface. Its inline detection intercepts adversarial patterns at the inference level, covering every tool call and agent-to-agent handoff. Embedding-based scoring against a shared Threat Library identifies retrieval poisoning attempts that statistical drift monitoring isn't designed to catch.
Warning Signs You're Already Experiencing Drift
Catch these signals before outputs become critically unreliable:
- Rising human override rates: users or reviewers increasingly reject or rephrase outputs, even when raw accuracy metrics look stable — a leading indicator that the model is misaligned with current expectations
- Confidence score drops or rising perplexity: statistical shifts against your baseline are often the earliest measurable signal of input distribution drift, showing up before downstream errors do
- Contextually wrong outputs: the model responds correctly by its own training logic but references a policy, product, or regulation that no longer applies
How to Detect Data Drift in LLMs
No single method catches all drift types. Effective detection is a layered discipline combining statistical signals, semantic analysis, and performance metric tracking — with each layer catching what the others don't.
Statistical Methods on Embeddings
Comparing the distribution of input prompt embeddings from a baseline period against current production embeddings is the most reliable first-line detection approach for LLMs.
The basic workflow:
- Capture a representative sample of embeddings from a stable baseline period
- Continuously capture production prompt embeddings
- Compute distributional distance between baseline and current samples
- Trigger an alert when a predefined threshold is breached
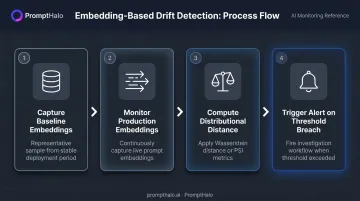
AWS lists Wasserstein distance and Population Stability Index (PSI) as practical drift metrics for LLM monitoring. High-dimensional embedding spaces typically require calibration and dimensionality-aware evaluation rather than a one-size-fits-all threshold.
Embedding-Based Semantic Drift Detection
Semantic drift detection monitors changes in the meaning of terms over time using cosine similarity between baseline and current embeddings. This catches subtle concept drift that statistical tests on raw distributions often miss.
Consider how "delivery" might evolve in user queries to cover digital fulfillment, software deployment, and physical logistics simultaneously — all in the same product context. A statistical test may not flag anything. A cosine similarity comparison between current and baseline embeddings for that term will show the divergence.
A drop in cosine similarity for key domain terms is a reliable indicator that the model's understanding of core concepts has drifted from user intent.
Performance Metric Monitoring
Task-specific KPIs provide the most business-relevant signal that drift is impacting real-world outcomes. Track these against established baseline thresholds:
- Escalation and override rates
- Resolution and task completion rates
- User satisfaction scores
- Perplexity on current inputs vs. baseline
- F1, BLEU, or task-specific accuracy metrics
When any metric crosses a threshold, treat it as a drift trigger requiring investigation — not just a support issue.
LLM-as-Judge for Semantic Analysis
One practical approach to continuous qualitative evaluation: use a secondary LLM to grade the primary model's outputs at scale, comparing them against current ground truth without requiring full human review.
AWS recommends a two-layer approach:
- Layer 1: Statistical alerts identify that drift has occurred
- Layer 2: A judge LLM classifies the nature of the drift — "new topic emergence," "shift in user intent," "language style change," or "concept redefinition"
That classification determines the correct remediation: retraining, fine-tuning, RAG knowledge base refresh, or prompt engineering adjustment. The right fix depends entirely on the nature of the drift — not just the fact that it occurred.
How to Prevent Data Drift in LLMs
Prevention slows drift accumulation and reduces severity when it does occur — but the specific strategies depend heavily on deployment context.
Continuous Learning and Scheduled Retraining
Two retraining approaches suit different deployment contexts:
| Approach | Best For | Tradeoff |
|---|---|---|
| Online learning | Streaming environments, high data velocity | Complexity, risk of instability |
| Batch retraining from checkpoint | Large LLMs, cost-sensitive deployments | Higher latency to correction |

The key principle: tie retraining triggers to drift alert thresholds rather than fixed calendar schedules. Retraining should respond to actual distributional change, not arbitrary time intervals.
Data Augmentation and Knowledge Base Refresh
Expanding training datasets with synthetically generated examples, recent domain documents, and diverse samples improves model resilience by broadening the distribution the model was trained on.
For RAG-based deployments, this is especially critical — stale retrieval sources are a primary driver of concept drift in production RAG systems. AWS Bedrock documentation confirms that syncing a data source re-ingests documents through parsing, chunking, embedding generation, and vector store updates. Separately, a 2025 medical drift study found that combining RAG with direct preference optimization reduced internal knowledge conflict ratios from 0.45 to 0.26 in Llama-3-8B.
Refresh frequency should follow source-system update cadence and risk tier, not a universal schedule.
Human-in-the-Loop Validation
Expert reviewers validate flagged outputs, provide corrective labels, and catch nuanced behavioral drift that automated metrics don't surface. NIST AI 600-1 supports post-deployment validation as a core governance requirement.
Deploy HITL selectively:
- Systematically for high-stakes domains (finance, healthcare, legal)
- As a response step when automated drift alerts fire, rather than as continuous review of all outputs
Tips for Long-Term Drift Monitoring and Control
Sustained drift governance requires more than detection tooling. These practices keep monitoring effective over time:
Establish a documented baseline immediately after deployment — including representative embedding samples, key performance metrics, and acceptable drift thresholds. All future comparisons depend on this reference point being stable and well-documented.
Automate adaptive drift thresholds that account for expected seasonal or event-driven variation (query spikes during product launches, regulatory update cycles). This reduces false alert fatigue while preserving sensitivity to genuine drift.
Maintain decision-level audit logs that record model inputs, outputs, and drift alerts over time, mapped to regulatory frameworks including NIST AI RMF, OWASP LLM Top 10, and the EU AI Act. Articles 12 and 72 specifically require logging and post-market monitoring for high-risk AI systems — making tamper-evident, compliance-ready trails a regulatory necessity, not just good practice.
Build cross-functional collaboration between data scientists, domain experts, and security teams. Drift that looks like a performance issue to ML engineers may signal an active adversarial campaign to a security team. Both perspectives are required for accurate diagnosis.

Platforms like PromptHalo address the audit log requirement directly: append-only trails capture decision rationale, agent identity, session context, and timestamp at the inference level — without requiring access to the underlying model.
Conclusion
Data drift in LLMs has identifiable causes — linguistic evolution, domain terminology changes, adversarial manipulation, and user behavior shifts — and each is detectable with the right combination of statistical monitoring, semantic analysis, and human oversight. None of this is speculative; the measurement exists. GPT-4's accuracy dropped nearly 50 percentage points over three months in a documented study. Healthcare LLMs show measurable asymmetry between accepting current guidance and rejecting outdated guidance.
That evidence points to a consistent pattern: drift isn't a detection problem, it's an organizational one. Most enterprise teams treat it as a background maintenance task rather than a continuous operational discipline. That posture leads to accuracy degradation that compounds over time, compliance exposure under NIST, EU AI Act, and FINRA obligations, and exploitable security vulnerabilities that standard monitoring tools aren't designed to catch.
Proactive drift management protects more than model quality. It determines whether AI deployments remain defensible — to regulators, to auditors, and to the customers relying on them.
Frequently Asked Questions
What is drift detection in LLM?
Drift detection in LLMs is the process of monitoring changes in input data distributions, model output quality, and semantic consistency over time. It uses statistical tests, embedding comparisons, and performance metric tracking to identify when a model's behavior has diverged from its trained baseline — typically before that divergence surfaces as visible output failures.
What is concept drift in LLM?
Concept drift refers to a shift in the underlying relationship between inputs and desired outputs. Even when user queries look statistically similar to the training baseline, the correct answer may have changed — for example, when regulatory guidance updates or market conditions redefine what constitutes a sound recommendation.
How do you detect drift in machine learning models?
Core methods include statistical tests (Wasserstein distance, PSI, Kolmogorov-Smirnov) to compare input distributions, embedding-based cosine similarity to catch semantic shifts, and performance metric monitoring (perplexity, escalation rate, F1) to measure real-world impact.
What is the difference between data drift and concept drift?
Data drift is a statistical change in input feature distribution — users asking about new topics or using new terminology. Concept drift is a change in the correct answer for the same type of input — the right regulatory guidance changes even though the query phrasing stays the same.
What happens if data drift in an LLM goes undetected?
Outputs become progressively less accurate or relevant, hallucinations increase, and user trust erodes. In regulated environments, the model may begin generating non-compliant or legally risky responses without triggering any obvious error signal — leaving compliance gaps and incident liability to accumulate silently.
How often should LLMs be monitored for data drift?
Continuous automated monitoring is preferable to scheduled checks. Alert thresholds should be tuned to the deployment context — high-stakes domains like finance or healthcare warrant near-real-time monitoring, while lower-stakes applications may tolerate daily or weekly batch evaluation. Frequency should match risk tier, not convenience.


