
Introduction
Most generative AI systems ship having never been deliberately attacked. They pass standard quality checks, clear performance benchmarks, and get deployed into production—where they handle financial transactions, customer data, and compliance workflows. Then attackers find the gaps.
IBM's 2025 research found that 13% of organizations reported breaches of AI models or applications—and 97% of those breached organizations lacked proper AI access controls. As agentic AI expands into autonomous tool calls, multi-step reasoning, and RAG retrieval pipelines, the consequences of untested deployments are compounding.
Adversarial testing is the practice of intentionally trying to break these systems before real-world attackers do. This guide breaks down why it matters for enterprise AI, the core attack types your team must probe for, and a practitioner workflow you can put to work immediately.
Key Takeaways
- Adversarial testing probes a generative AI system with malicious or edge-case inputs to expose vulnerabilities before attackers find them.
- Unlike standard correctness testing, adversarial testing evaluates safety, security, and alignment under hostile conditions.
- Core attack categories include prompt injection, jailbreaks, RAG poisoning, data leakage, and agentic tool misuse.
- An effective workflow covers threat scoping, attack design, execution, and result analysis—integrated directly into CI/CD pipelines.
- Testing findings must feed into runtime enforcement and ongoing monitoring to close the security loop.
What Is Adversarial Testing for Generative AI?
Adversarial testing is the systematic practice of supplying a generative AI system with inputs specifically crafted to elicit unsafe, incorrect, policy-violating, or harmful outputs. That includes both explicitly adversarial prompts—designed to force a clear violation—and implicitly adversarial prompts, which appear innocuous but exploit sensitive topics or subtle contextual manipulations.
How It Differs from Standard AI Testing
Standard testing evaluates whether a model produces correct outputs for expected inputs, using predefined test cases with deterministic pass/fail logic. Adversarial testing operates differently — it explores emergent failure modes and edge cases that no standard test suite anticipates.
The distinction goes beyond methodology. The table below captures how each approach differs across key dimensions:
| Dimension | Standard Testing | Adversarial Testing |
|---|---|---|
| Testing logic | Deterministic pass/fail | Probabilistic, exploratory |
| Input type | Expected, valid inputs | Crafted, malicious, edge-case |
| Result type | Correctness | Safety, security, alignment failures |
| Approach | Predefined scenarios | Attack simulation, red teaming |

Where It Applies
Adversarial testing applies across AI deployment types:
- LLM-powered chatbots and customer service agents
- Agentic AI systems making autonomous tool calls
- RAG-based applications pulling from external data sources
- Multi-modal models processing text, images, or structured data
- Any AI embedded in regulated workflows—fintech, healthcare, legal services
Why Adversarial Testing Is Critical for Enterprise AI
The Cost of Untested Deployments
Vulnerabilities in production AI systems aren't theoretical. Recent incidents illustrate the stakes:
- EchoLeak (CVE-2025-32711) — a zero-click prompt injection in Microsoft 365 Copilot that enabled remote data exfiltration without any user interaction
- Samsung restricted generative AI tools after employees submitted sensitive source code and internal meeting content to ChatGPT
- Air Canada was ordered to pay damages after its chatbot gave a customer incorrect bereavement-fare information
Most AI teams discover vulnerabilities after incidents rather than before launch. Gartner predicts that by 2027, more than 40% of AI-related data breaches will be caused by improper use of generative AI. That trajectory makes pre-deployment adversarial testing a business necessity, not a nice-to-have.
Regulatory Pressure Is Increasing
Regulatory frameworks are tightening around AI safety and testing requirements:
- EU AI Act Articles 9 and 15 require high-risk AI systems to have documented risk management, maintain appropriate robustness and cybersecurity, and demonstrate resilience against adversarial examples, data poisoning, and model poisoning.
- NIST AI RMF structures AI risk through its TEVV framework—test, evaluation, verification, and validation—and NIST AI 600-1 specifically recommends red-teaming for prompt injection, data poisoning, and model extraction risks.
- FINRA and FCA guidance reminds financial firms that governance, model risk management, and validation obligations apply to AI deployments, including evaluation before deployment.
Organizations deploying AI without documented adversarial testing face both regulatory exposure and reputational risk when incidents occur.
The Agentic AI Problem
A static chatbot has a limited attack surface. An AI agent that autonomously calls APIs, retrieves data from external sources, and hands tasks off to sub-agents is a different problem entirely.
Gartner predicts 40% of enterprise applications will feature task-specific AI agents by 2026, up from less than 5% in 2025. A single successful prompt injection in an agentic pipeline can cascade across tool calls and agent handoffs in ways a traditional security stack was never designed to detect.
That's why adversarial testing for agentic AI requires a fundamentally different scope — one that covers not just model outputs, but every tool call, retrieval step, and agent-to-agent handoff in the pipeline.
Types of Adversarial Attacks on Generative AI
Generative AI systems have multiple exploitable surfaces beyond just the input prompt. A complete adversarial testing program must probe each layer.
Input and Prompt Layer Attacks
Two dominant attack types operate at the input layer:
- Jailbreaks — prompts that bypass safety filters to elicit prohibited content. JailbreakBench data shows roleplay-based attacks achieving 79% success rate on some models, with PAIR attacks reaching 82% on Vicuna.
- Prompt injection — embedding malicious instructions in user-supplied or retrieved text to override system behavior. OWASP classifies this as LLM01, the top vulnerability for LLM applications.
Obfuscated variants using Base64 encoding, zero-width characters, or indirect phrasing are designed specifically to evade rule-based content filters. A 2025 systematic evaluation found encoding tricks achieved a 76.2% attack success rate by evading keyword-based filtering. This is why ML-based detection outperforms regex and keyword approaches.

Retrieval and Context Layer Attacks
Two attack types target the retrieval layer:
- RAG poisoning — an attacker inserts malicious content into the knowledge base, causing the AI to retrieve and act on false or harmful information without any direct prompt manipulation. Research on PoisonedRAG demonstrated 90% attack success by injecting just five malicious texts into a database with millions of entries.
- Context override attacks — injected instructions in retrieved documents replace or corrupt the original system prompt entirely, bypassing any controls set at the application layer.
Agentic and Tool Use Layer Attacks
Where retrieval attacks corrupt data, agentic attacks exploit what the AI does with that data. This layer carries the highest consequence risk in enterprise deployments:
- Unauthorized tool execution — forcing an agent to invoke APIs or functions beyond its intended scope
- Data exfiltration via external API calls — using tool access to leak sensitive information
- Chain-of-thought manipulation — altering intermediate reasoning steps to produce malicious downstream outcomes
- Multi-agent handoff exploitation — a compromised sub-agent passes poisoned instructions to downstream agents
OWASP's LLM06 Excessive Agency category specifically addresses when LLM-based systems have unchecked autonomy to call functions, leading to unintended consequences.
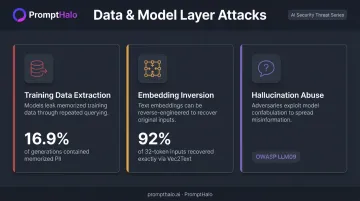
Data and Model Layer Attacks
- Training data extraction — researchers extracted over 10,000 unique examples from ChatGPT, with 16.9% of tested generations containing memorized personally identifiable information
- Embedding inversion — Vec2Text recovered 92% of 32-token inputs exactly from dense vector embeddings, reconstructing original text from what organizations assumed was anonymized data
- Hallucination abuse — crafting prompts that reliably cause the model to fabricate authoritative-sounding false information (OWASP LLM09 Misinformation)
How Adversarial Testing Works: Step by Step
Effective adversarial testing isn't ad hoc prompt experimentation. It follows a structured workflow that mirrors a security assessment lifecycle. Programs that skip threat scoping, rely solely on automation, or treat testing as a pre-launch checkbox tend to find the least dangerous problems while missing the most exploitable ones.
Step 1 – Define Scope and Threat Model
Map the AI system's attack surface before writing a single test case. This means identifying:
- All input channels (user prompts, API calls, retrieved content)
- Retrieval sources and external data integrations
- Tool permissions and agent handoff pathways
- Harm categories relevant to the deployment context
A fintech AI agent requires testing for data exfiltration and unauthorized transaction execution. A healthcare chatbot requires testing for unsafe medical advice and PII exposure. A clear threat model prevents teams from testing broadly but shallowly, and ensures coverage aligns with actual business risk.
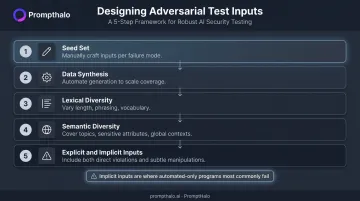
Step 2 – Design Adversarial Inputs
Construct test datasets systematically:
- Start with a seed set — manually crafted inputs targeting each identified failure mode
- Expand with data synthesis — use automated generation to scale coverage
- Ensure lexical diversity — vary length, phrasing, and vocabulary across inputs
- Ensure semantic diversity — cover varied topics, sensitive attributes, and global contexts
- Include both explicit and implicit adversarial inputs — direct policy violations and subtle context-dependent manipulations that automated scanners typically miss
Implicit adversarial inputs are where most automated-only programs fail. A prompt that appears to request legitimate help can exploit context in ways keyword scanners never flag.
Step 3 – Execute Tests (Manual, Automated, and Hybrid)
| Approach | Speed | Coverage | Depth | Best For |
|---|---|---|---|---|
| Manual red teaming | Slow | Targeted | High | Novel failure modes, context-dependent attacks |
| Automated fuzzing | Fast | Broad | Low | Volume stress-testing, known attack patterns |
| Hybrid | Moderate | Broad + targeted | High | Production-grade programs |
Tools like NVIDIA's garak and Microsoft's PyRIT support automated adversarial probing across hallucination, data leakage, prompt injection, and jailbreak categories. Anthropic has documented converting qualitative red-team findings into quantitative evaluations for repeated automated testing—the hybrid approach in practice.
Automated tools excel at volume. They miss context-dependent vulnerabilities that require human reasoning, which is why manual and automated methods aren't competing approaches — they cover different failure surfaces.
Step 4 – Analyze Results and Score Risk
After execution, structure your findings:
- Annotate outputs using safety classifiers, human raters, or both
- Score by severity and business impact using OWASP's AI Vulnerability Scoring System (AIVSS), which adds AI-specific metrics — Adversarial Attack Surface, Decision Criticality, and Model Robustness — to standard base metrics
- Map findings to OWASP LLM Top 10 for consistent reporting to security teams and regulators
- Prioritize by exploitability combined with business impact — not just technical severity in isolation
This structured output is what security teams and compliance officers can act on—and what regulators expect to see documented.
Step 5 – Remediate, Harden, and Continuously Test
Remediation options include:
- Enforcing input/output guardrails
- Fine-tuning the model with adversarial examples
- Adding ML-based filters (not just keyword rules)
- Updating governance policies and agent permission scopes
Adversarial testing belongs in the CI/CD pipeline, not just the pre-launch checklist. The security value of a one-time test decays the moment the system changes — and AI systems change often. Treat re-testing as a trigger, not a calendar event:
- Any model update or architecture change warrants a new test cycle
- New tool integrations or agent handoff paths expand the attack surface
- Every finding should inform detection and enforcement systems going forward
How PromptHalo Can Help
Most adversarial testing programs stop at findings. They identify vulnerabilities, produce a report, and leave remediation to the development team, with no mechanism for those findings to automatically strengthen runtime defenses. That gap is exactly what PromptHalo closes.
PromptHalo's AI Red Teaming capability attacks your agents, RAG layers, and tool chains the way a real adversary would, probing for prompt injection, jailbreaks, RAG poisoning, data leakage, and unauthorized tool calls across the full agentic attack surface, including multi-step, multi-agent workflows. Results come back as risk-scenario-mapped reports with prioritized, actionable fixes, not raw vulnerability dumps.
The critical differentiator is the closed-loop architecture. Every attack path the Red Teaming solution discovers gets encoded into a shared Threat Library, which automatically trains the Runtime Security engine. A newly identified attack pattern becomes a runtime defense without waiting for a new release cycle. Protection compounds over time instead of decaying between test cycles.
At runtime, PromptHalo sits inline on every inference, tool call, and agent-to-agent handoff. Every action gets one of five enforcement decisions (allow, restrict, challenge, deny, or monitor) in under 100ms, without touching the underlying model, without a code rewrite, and without model retraining.
Agent security passports travel with each request, carrying embedded policy and authority information. Authority decay ensures permissions don't persist indefinitely, forcing re-authorization when time, step, or risk budgets are exceeded.
For enterprise buyers, the deployment and compliance story matters:
- Deploys in under a day via API gateway, agent mode, or inline middleware—no model retraining, no code rewrite
- Vendor-agnostic across any AI provider or model; operates externally by monitoring input/output streams
- ML-based detection achieving over 95% catch rate at under 5% false positives, compared to roughly 35% for rule-based approaches
- Tamper-evident, append-only audit logs at the decision level—every event captured with reason, agent identity, session context, and timestamp—providing the replayable evidence trail security teams and regulators need
Adversarial testing is not a one-time event. The most resilient AI deployments pair systematic testing with runtime enforcement, because vulnerabilities discovered in testing need to harden real-time defenses, not sit in a backlog. For teams deploying or scaling generative AI, that closed loop is what turns point-in-time findings into durable, compounding protection.
Frequently Asked Questions
How does adversarial AI testing differ from standard AI testing?
Standard testing uses predefined inputs to verify correct outputs under expected conditions. Adversarial testing uses crafted malicious or edge-case inputs to expose safety failures, policy violations, and emergent vulnerabilities that standard test cases would never surface. The goal isn't confirming what works—it's finding what breaks.
What are adversarial examples in AI?
Adversarial examples are inputs (text, images, or other data) deliberately crafted or subtly altered to cause an AI system to produce incorrect, unsafe, or policy-violating outputs. They often appear completely normal to a human observer, making them difficult to catch with rule-based filters alone.
What are the different types of AI testing?
The main categories are:
- Functional/standard testing — correctness under expected conditions
- Performance testing — latency and throughput
- Safety testing — prevention of harmful outputs
- Adversarial/red team testing — deliberate attack simulation
- Compliance testing — alignment with the EU AI Act, NIST AI RMF, and similar frameworks
What is the difference between red teaming and adversarial testing?
Adversarial testing is the broader practice of probing AI systems with harmful or edge-case inputs. Red teaming is a specific methodology within it, involving a dedicated team that simulates real attacker behavior — manually, through automated tools like garak or PyRIT, or both in combination.
What are the most common adversarial attacks on LLMs?
The most prevalent are prompt injection, jailbreaks, RAG and data poisoning, and training data extraction. For agentic systems specifically, unauthorized tool execution and multi-agent handoff manipulation represent the fastest-growing and least-tested category in enterprise deployments.
How often should adversarial testing be conducted on a generative AI system?
Continuously — integrated into the development pipeline, not run once before launch. Mandatory re-testing should trigger on model updates, architecture changes, and new tool or API integrations — and always ahead of regulatory certification or production release.


