
Introduction
Security teams deploying autonomous AI agents face a threat model that traditional penetration testing and generative AI safety evaluations were never built to address. Unlike a chatbot that generates text, an agentic AI plans, executes, and acts — calling APIs, querying databases, running code, and coordinating with other agents.
When one of those agents is compromised, the consequences don't stop at a bad output. They cascade across every system the agent can touch.
Deloitte found that 61% of healthcare technology executives are already building or funding agentic AI initiatives, with 85% planning increased investment over the next two to three years. In financial services, adoption is already underway. The attack surface is expanding faster than most security programs have adapted.
That gap points to a specific practitioner problem: most security teams apply generative AI red teaming methods to agentic systems without accounting for autonomy, persistent memory, tool access, and multi-agent coordination. The result is a security assessment that misses the highest-impact failure modes entirely.
This guide breaks down what agentic AI red teaming actually requires — the threat categories, the methodologies, and how to build it into your security program as an ongoing practice rather than a one-time deployment gate.
Key Takeaways
- The agentic AI attack surface spans control systems, memory, tool calls, knowledge bases, and inter-agent communications — not just model inputs
- 12 agentic threat categories — defined by the Cloud Security Alliance — set the scope for structured red teaming
- Red teaming functions continuously across the AI lifecycle, not only at pre-deployment checkpoints
- Redirect findings into runtime enforcement — discovery without enforcement leaves production systems exposed
- NIST AI RMF, OWASP LLM Top 10, and the EU AI Act require regulated environments to demonstrate measurable control over agent behavior
What Is Agentic AI Red Teaming?
Agentic AI red teaming is the simulation of adversarial attacks specifically against autonomous AI agents — designed to discover how an agent can be manipulated to deviate from its intended goals, abuse granted permissions, leak sensitive data, or take irreversible real-world actions before an attacker does.
How It Differs from Related Processes
Three terms are frequently conflated, but they cover distinct ground:
| Process | Primary Focus | Key Limitation for Agentic AI |
|---|---|---|
| Traditional penetration testing | Deterministic code vulnerabilities in static systems | Doesn't test probabilistic AI behavior or tool use |
| Generative AI red teaming | Content safety, jailbreaks, single-turn model interactions | Misses multi-step reasoning, memory, and tool execution |
| Agentic AI red teaming | Full operational surface: inputs, memory, tools, goals, inter-agent handoffs | Requires purpose-built methodology and tooling |

The intended outcome is a documented map of exploitable attack paths across the agent's entire operational surface. Security teams use this to harden defenses, while compliance teams use it to demonstrate control coverage against frameworks like NIST AI RMF and the EU AI Act.
Testing agentic AI is fundamentally harder than testing a standard LLM. Four properties create that gap:
- Non-determinism: Identical inputs can produce different outputs on every run
- Persistent memory: State carries forward, so one compromised interaction affects all future behavior
- Elevated permissions: Agents hold access that attackers can abuse beyond the conversation itself
- Inter-agent communication: Connected agents become secondary targets in multi-step attack chains
None of these properties exist in a single-turn content safety evaluation.
Why Agentic AI Systems Demand Specialized Red Teaming
The risk profile of a compromised agentic AI is categorically different from a compromised chatbot. When an agent is manipulated, every system it has access to becomes a potential downstream target.
The Unique Testing Demands
Agentic systems create four specific requirements that conventional red teaming doesn't address:
- Attack success is probabilistic — the same input may succeed in 3 of 10 runs and fail in 7, so testing requires multiple iterations of each scenario
- Memory corruption persists: one poisoned memory state affects all future behavior until it's detected and cleared, not just the single interaction
- Elevated permissions that agents hold legitimately become attack leverage the moment the agent is manipulated
- A compromised agent serves as a launchpad against peer agents that trust its outputs, turning one failure into a chain
What Goes Wrong Without Specialized Testing
The EchoLeak vulnerability (CVE-2025-32711), published by Microsoft in June 2025, is the clearest public example of why conventional controls miss agentic-specific flaws. The attack was a zero-click indirect prompt injection in Microsoft 365 Copilot — malicious instructions embedded in content that Copilot processed, exploiting its trusted access to organizational data rather than requiring any direct user interaction.
No traditional security control was positioned to catch it. That gap isn't an exception — it's the pattern.
Organizations relying solely on traditional pentesting or generative AI safety evaluations miss entire attack classes:
- Indirect prompt injection through tool outputs and retrieved documents
- Goal hijacking through chain-of-thought manipulation
- Knowledge base poisoning via RAG retrieval
- Orchestration-layer attacks across multi-agent pipelines
The Agentic AI Threat Landscape: What Red Teams Must Test For
The Cloud Security Alliance's Agentic AI Red Teaming Guide, released May 28, 2025, identifies 12 agentic threat categories developed specifically because the OWASP LLM Top 10 and traditional threat models don't adequately capture agentic risk. OWASP later confirmed this gap by publishing a separate Top 10 for Agentic Applications for 2026. These categories define red team scope.
Input and Goal Manipulation
- Prompt injection (direct and indirect/XPIA): Malicious instructions embedded in tool outputs, retrieved documents, or external content the agent consumes — not just user inputs. Microsoft identifies cross-domain prompt injection as the primary mechanism behind EchoLeak.
- Context window poisoning: Adversarial directives hidden in long contexts, processed by the agent without being flagged as untrusted.
- Goal hijacking: Malicious sub-goals inserted into the agent's step-by-step reasoning chain, redirecting behavior without touching the surface-level instruction.
- Checker-out-of-the-loop attacks: Human oversight bypassed during sensitive actions, especially dangerous when agents operate faster than manual monitoring allows.
Memory, Knowledge Base, and Data Threats
- Memory and context manipulation: Persistent state tampering that alters all future agent behavior — among the most durable attack effects in agentic systems.
- Knowledge base poisoning: Corrupting RAG retrieval sources. USENIX Security 2025 research found attack success rates exceeding 90% with just 5 poisoned texts, a meaningful proof-of-concept for regulated environments handling customer data.
- Sensitive data leakage: Financial records, PII, or health data exposed through agent tool calls or generated outputs.
Orchestration, Multi-Agent, and Operational Threats
- Multi-agent exploitation: Spoofing agent identities, abusing inter-agent trust relationships, or enabling malicious collusion between agents.
- Agent impact chain: A single compromised agent propagating access across every connected tool and system — the blast radius expands with every integration.
- Supply chain attacks: Malicious or compromised third-party tools, plugins, or dependencies introduced into the agent's execution path.
- Resource exhaustion: Cascading recursive blocking attacks (where one stalled agent triggers failures in dependent agents) that drain computational resources across systems like AutoGen.
Authorization and Traceability Threats
- Authorization and control hijacking: Permission gaps or dynamic role assignments exploited to issue unauthorized commands.
- Critical system interaction risks: Agents connected to industrial or physical systems manipulated to cause real-world harm.
- Agent untraceability: Agent action origins masked to evade audit trails. IBM's AI Risk Atlas flags this directly: explanations, lineage, and trace information may be difficult or entirely unobtainable.

These three categories carry direct compliance exposure. NIST AI RMF, the OWASP LLM Top 10, and EU AI Act Regulation 2024/1689 all require demonstrable control over agent authorization and tamper-evident audit logs. When an agent acts without a traceable record, regulators won't treat that as a security incident — they'll treat it as a controls failure.
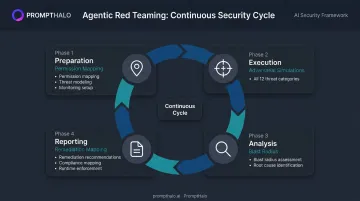
How Agentic AI Red Teaming Works: A Four-Phase Process
Agentic AI red teaming runs as a repeating cycle: map scope, simulate attacks, analyze findings, harden defenses. Each phase builds on the last. Platforms like PromptHalo's red teaming solution automate adversarial simulation across tool calls, RAG retrieval, and multi-agent handoffs — covering attack surfaces that manual testing alone would miss.
Phase 1: Preparation
Preparation is more than scoping. Before a single attack runs, red teamers must:
- Map granted permissions and authority boundaries — document exactly what the agent is allowed to do and what systems it can reach
- Enumerate every API endpoint and data source — nothing in the tool catalog should be untested
- Document inter-agent communication protocols — who does this agent trust, and how are those trust relationships established?
- Define prohibited actions and acceptable behavior boundaries — you need a clear baseline to measure deviations against
- Configure monitoring to capture full decision traces — every tool call, reasoning step, and output must be logged during testing
The threat model established here should be deployment-specific. A financial services agent with payment API access requires a fundamentally different threat model than an internal IT automation agent — different permissions, different blast radius, different compliance obligations.
Phase 2: Execution
Execution actively simulates adversarial conditions across all 12 threat categories. This includes:
- Injecting crafted prompts — direct and indirect, including via tool outputs and retrieved content
- Attempting to poison knowledge sources and RAG retrieval pipelines
- Simulating compromised tool outputs that carry hidden instructions
- Escalating permissions through legitimate interfaces
- Spoofing inter-agent communications to test trust boundaries
- Running multi-turn attacks that gradually escalate risk across conversational turns
Because agents are non-deterministic, multiple runs of each scenario are mandatory. A vulnerability that surfaces in 2 of 10 runs is still exploitable — probabilistic failures require probabilistic testing. All agent actions, tool calls, and decision outputs must be logged in real time for correlation in analysis.
Phase 3: Analysis
Analysis translates raw test data into prioritized findings. Red teamers correlate injected inputs with logged agent behavior to identify root causes:
- Failed input validation
- Overly permissive tool grants
- Unvalidated RAG retrieval results
- Missing inter-agent authentication
Each finding gets a blast radius assessment — how far could this exploit propagate across connected systems? Findings that affect compliance-sensitive workflows (transactions, PII handling, audit logging) get priority flags. Risk-scenario-mapped reports, rather than raw vulnerability lists, give security and compliance teams actionable triage starting points.
Phase 4: Reporting
Effective red team reports for agentic systems document each attack path end-to-end: input → agent reasoning → tool call → outcome. They include replayable evidence, map findings to compliance frameworks (OWASP LLM Top 10, NIST AI RMF, EU AI Act), and deliver specific remediation recommendations.
Agentic-specific remediations to include:
- Time-limit elevated permissions so agent authority decays rather than persisting indefinitely
- Block tool and API calls that exceed the agent's intended operational boundary
- Validate retrieved content before it enters the agent's context window
- Require agents to verify peer identity before acting on inter-agent instructions
Findings should feed directly into runtime enforcement rules. PromptHalo's closed-loop architecture encodes newly discovered attack patterns into a shared Threat Library, so each red team cycle compounds protection — every iteration makes the next defense stronger.
Embedding Agentic AI Red Teaming Across the AI Development Lifecycle
Treating red teaming as a pre-deployment gate is one of the most common and costly mistakes enterprises make. Agents evolve — adding tools, encountering new data, and integrating new knowledge sources after launch. A clean pre-deployment assessment becomes outdated the moment any of those variables shift.
When to Run Red Teaming
| Lifecycle Stage | Trigger |
|---|---|
| Design | Evaluating foundational model risk for the intended use case |
| Development | Upgrading models, integrating new tools, modifying agent goals |
| Pre-deployment | Comprehensive adversarial testing before production release |
| Post-deployment | Scheduled continuous runs as the agent encounters real-world data |
Red team findings should feed into CI/CD pipelines as automated regression tests, flagging configuration changes that re-introduce known vulnerabilities. They should also inform system prompt updates, guardrail configurations, and runtime enforcement rules in production. That continuity matters most when agents hit the limitations red teaming alone can't address.
When Red Teaming Alone Is Insufficient
Red teaming identifies risk. It cannot block real-time attacks. Organizations in regulated environments that treat a single red team report as sufficient compliance evidence are exposed because:
- New tool integrations create new attack surfaces immediately
- Updated knowledge bases introduce new poisoning opportunities
- Shifting user behavior surfaces failure modes that weren't anticipated in testing
Runtime enforcement, anomaly monitoring, and evidence-grade audit logging must operate alongside red teaming. Each layer addresses what the others cannot.
Common Misconceptions and Limitations
Misconception 1: Agentic Red Teaming Is the Same as LLM Jailbreak Testing
This is the most dangerous misconception in practice. Security teams frequently apply jailbreak and harmful content probing to agentic systems without testing tool use, memory, goal persistence, or multi-agent interactions. That leaves the highest-impact attack surfaces completely untested.
Even a passed assessment doesn't guarantee security. Non-determinism means the same agent can behave differently in production — particularly under novel inputs or data distributions the test never covered.
Misconception 2: Red Teaming Only Applies to the Model
Many organizations scope red teaming to the model itself — not to the orchestration layer, memory stores, RAG pipelines, or tool integrations. All of these are in scope. The agent's entire operational ecosystem must be tested, not just what it says in response to a prompt.
Separate from scope, red teaming (adversarial testing to find exploitable paths) is frequently conflated with safety evaluation (benchmarking against known harmful categories). They serve different purposes and neither replaces the other.
What Red Teaming Cannot Do
- Enforce real-time protection against attacks in production
- Guarantee complete coverage of emergent behaviors from novel agent architectures
- Substitute for identity governance, access control, and secure-by-design development practices
Organizations that treat red teaming as a one-time compliance exercise will find their assessments outdated before new agent capabilities even reach production. Adversaries don't wait for the next scheduled test cycle.
Frequently Asked Questions
What is the difference between red teaming an agentic AI system and red teaming a standard LLM?
Standard LLM red teaming focuses on model inputs and outputs — jailbreaks, harmful content, data extraction from a single interaction. Agentic red teaming must also probe the agent's control system, persistent memory, tool call behavior, knowledge base integrity, and inter-agent trust. Because the agent acts autonomously across multiple systems, a single compromised decision can cascade into a system-wide breach.
How often should agentic AI red teaming be performed?
Red teaming must be continuous, not a one-time pre-deployment exercise. Best practice combines automated adversarial scanning across design, development, and pre-deployment with scheduled post-deployment runs. Re-test immediately whenever tools, goals, or data sources change.
What are the most critical threat categories to prioritize?
Prioritize by blast radius for your specific deployment. For most organizations, the highest-priority categories are: indirect prompt injection via tool outputs, goal and instruction manipulation, knowledge base poisoning in RAG-dependent agents, and multi-agent exploitation in orchestrated pipelines — particularly in regulated environments where a single agent failure can trigger compliance violations.
Can automated tools replace human red teamers for agentic AI systems?
Automated tools accelerate coverage — generating adversarial prompts, simulating attack strategies, and running regression tests at scale. They cannot replace human expertise for designing deployment-specific threat models, interpreting probabilistic results, or translating findings into remediation strategies. The two work best together.
How does agentic AI red teaming support regulatory compliance?
NIST AI RMF, OWASP LLM Top 10, and the EU AI Act all require organizations to assess and manage AI risk systematically. Red teaming provides the evidence base: it maps exploitable attack paths to defined risk categories, demonstrates that controls were tested before deployment, and — when paired with tamper-evident audit logs — supports regulatory reporting requirements in financial services, healthcare, and other regulated sectors.
What should organizations do after red teaming finds vulnerabilities?
Triage findings by exploitability and blast radius first, then remediate — tightening permissions, hardening RAG retrieval validation, and updating system prompts and guardrails. Pair those fixes with runtime enforcement rules that block identified attack paths in production. Feed all findings into automated regression tests so vulnerabilities don't re-emerge as the agent evolves.


