
Introduction
Financial records, PII, health data, and internal documents now flow through LLMs, RAG pipelines, and autonomous agents that most security stacks were never designed to see. The exposure is already measurable — and growing fast.
According to the Cyberhaven 2025 AI Adoption and Risk Report, 34.8% of corporate data entered into AI tools is now classified as sensitive — up from 10.7% just two years ago. That jump didn't happen gradually — it reflects a fundamental change in where organizational risk now concentrates.
This guide covers both dimensions of that shift:
- How AI systems expose sensitive data to attack vectors that conventional tools can't detect
- How AI-powered security approaches — including runtime enforcement — protect data across the full AI lifecycle
You'll find coverage of AI-native threats, practical protection strategies, regulatory obligations, and what enforcement looks like at the inference and agent layer.
Key Takeaways
- 34.8% of enterprise data entering AI tools is sensitive — a threefold increase in two years
- AI introduces unique threats like prompt injection, model inversion, and retrieval poisoning that perimeter tools can't address
- Sensitive data is at risk during training, inference, and storage — not just at the endpoint
- Runtime enforcement must cover every inference, tool call, and agent handoff — including calls that never touch the model API directly
- GDPR, the EU AI Act, HIPAA, PCI DSS, and CCPA each impose compliance obligations on AI systems that process personal or financial data
What Makes Sensitive Data Vulnerable in AI Systems
AI systems ingest sensitive data at scale, accept unstructured inputs, and can memorize or reproduce information in ways that conventional DLP tools were never built to detect.
The Data-in-Multiple-States Problem
Sensitive data faces exposure at three distinct points:
- During training — ingestion pipelines and labeling workflows pull in data at volume, often without adequate classification
- During inference — real-time prompts and completions pass through models with minimal inspection
- In storage — embedding stores, vector databases, and audit logs retain sensitive content that security teams seldom audit
Traditional perimeter controls protect data at rest and in transit. They have no visibility into semantic content flowing through an LLM inference pipeline.
The Insider and Third-Party Risk
The Samsung incident — where employees allegedly pasted source code, meeting transcripts, and proprietary test sequences into ChatGPT — became a reference case for this problem. Employees were using a cloud AI tool like any productivity app, unaware that organizational data was being transmitted to a third-party model provider. No exploit required — just routine behavior at scale.
According to the LayerX 2025 Enterprise AI and SaaS Data Security Report:
- 77% of employees pasted data into GenAI tools
- 82% of that paste activity occurred through unmanaged personal accounts
- 40% of files uploaded to GenAI tools contained PII or PCI data

When employees use personal accounts, IT has no visibility, no logging, and no recourse — and that exposure problem compounds as AI adoption grows across the organization.
Why Scale Changes the Equation
AI systems process more data, more quickly, and with less human review than any traditional workflow. A single misconfigured retrieval pipeline or compromised prompt template can expose information across thousands of queries before anyone notices. The Harmonic Security 2025 dataset — drawn from over 22 million enterprise AI prompts — found that 16.9% of sensitive exposures occurred on free-tier plans where IT had no visibility at all.
AI-Native Attack Vectors That Put Sensitive Data at Risk
The threat landscape for AI isn't just a variation on existing attack categories. Several vectors are genuinely new, and they require different defenses.
Prompt Injection
OWASP LLM01:2025 defines prompt injection as manipulating model responses through inputs that alter behavior, bypass controls, disclose data, or trigger unintended actions. Two variants matter here:
- Direct prompt injection: a user crafts malicious input to extract data or override system instructions
- Indirect prompt injection: malicious instructions are embedded in retrieved documents, websites, or tool outputs that the model processes as context
Indirect injection is the harder problem. A RAG system retrieving a poisoned document from a corporate knowledge base can unknowingly hand an attacker control over the model's behavior — without any malicious user input at all.
Data Poisoning and Training-Time Attacks
Attackers who can influence training data can introduce backdoors that cause models to behave insecurely later. The NSA, CISA, and partner agencies addressed this threat class directly in their Guidelines for Secure AI System Development, identifying training-data poisoning as a core adversarial ML risk. A poisoned model might leak PII in response to a specific trigger phrase — invisible in normal operation, devastating when exploited.
Model Inversion and Membership Inference
Deployed models can be queried in ways that let attackers reconstruct training data or confirm whether specific records were used. Research published at IEEE S&P demonstrated membership inference with 94% median accuracy on retail purchase data and over 70% on hospital discharge records. For healthcare and financial services organizations, this creates direct privacy liability — the model itself becomes an attack surface for extracting protected information.
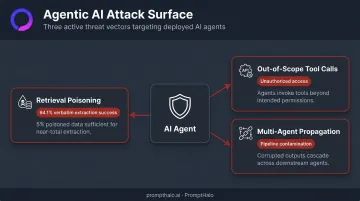
The Agentic AI Attack Surface
Agentic systems introduce compounding risk. When an AI agent autonomously calls APIs, reads databases, executes code, and hands off tasks to other agents, each action is a potential data leakage point. The specific threats include:
- Retrieval poisoning: manipulating RAG retrieval to trigger data exfiltration — backdoored systems with just 5% poisoned fine-tuning data achieved 94.1% verbatim extraction success
- Out-of-scope tool calls: agents acting outside their intended authority, reaching systems or data they were never meant to access
- Multi-agent propagation: one compromised agent passing malicious instructions downstream, contaminating the entire pipeline
Jailbreaks as a Data Security Bypass
Jailbreaks aren't just a content policy problem. OWASP LLM07:2025 is clear that system prompts should not function as primary security controls — they can be bypassed. Attackers who successfully jailbreak a model can extract proprietary system prompts, customer data, and internal context that the model had access to. The data exposure follows directly — and without runtime enforcement, there's nothing between a successful jailbreak and whatever the model knows.
How AI Technology Strengthens Sensitive Data Protection
ML-Based Detection vs. Rule-Based DLP
Traditional DLP tools match known patterns. ML-based detection works differently: it identifies anomalous access patterns, unusual query volumes, and novel exfiltration attempts by learning what "normal" looks like and flagging deviations.
PromptHalo's ML-based detection operates at a catch rate above 95% with under 5% false positives. Rule-based approaches typically land around:
- 35% catch rate — most novel threats go undetected
- 15–20% false positive rate — legitimate actions regularly blocked
- No behavioral baseline — misses anything not explicitly programmed

The result with ML-based detection: fewer breaches missed, fewer legitimate actions blocked.
Real-Time Classification and Masking at Scale
AI-powered systems can scan prompts and completions in flight — identifying and redacting PII, PHI, financial identifiers, and confidential data before they reach a model or appear in logs. Platforms like Amazon Bedrock Guardrails and Google Cloud Sensitive Data Protection demonstrate this at production scale, replacing sensitive values with anonymized tags in real time.
At inference speed, manual review creates an impossible bottleneck. Automated classification handles volume that no human team can.
Anomaly Detection for AI Pipelines
Continuous monitoring of model inputs, outputs, and tool calls surfaces threats that wouldn't otherwise appear in logs. These include unusual retrieval patterns, high-volume queries targeting specific data types, and agent actions that fall outside established behavioral baselines. In high-volume AI workloads, behavioral monitoring is the only practical way to detect exfiltration attempts before they complete.
Best Practices for Protecting Sensitive Data Across the AI Lifecycle
Classify Before You Ingest
The most effective control is applied before data enters an AI system. The ICO's AI data protection guidance states it directly: identify the minimum personal data needed for the specific purpose before processing begins.
In practice, this means:
- Classify PII, PHI, financial data, and confidential IP at the source
- Apply redaction or tokenization before data enters training pipelines or retrieval stores
- Enforce data minimization so models receive only what's necessary for the task
Apply Zero-Trust Principles Across the AI Stack
Zero-trust for AI means treating every prompt, every tool call, and every agent handoff as an untrusted action requiring explicit authorization. Specific controls include:
- Role-based and attribute-based access controls on model APIs and vector databases
- Fine-grained, permission-aware retrieval systems that enforce user-level access at query time
- Least-privilege configurations across all third-party model integrations
NIST AI 600-1 supports this approach, recommending that organizations inventory third parties with content access and specify access modes for foundation models.
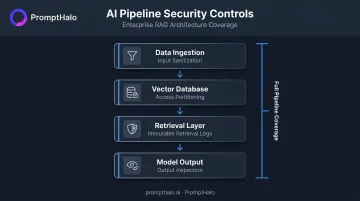
Secure the Entire Pipeline — Not Just the Model
Security focus tends to land on the LLM endpoint, but the data ingestion pipeline, embedding store, retrieval layer, and API integrations connecting the model to production systems each carry their own exposure. Every layer needs controls:
- Input sanitization at ingestion
- Access partitioning in vector databases
- Immutable retrieval logs
- Output inspection before results reach users
Use Privacy-Preserving Techniques for Training
For model development and fine-tuning, anonymization, pseudonymization, and synthetic data generation reduce sensitive data exposure at the source. Some teams assume they can remove sensitive data after the fact through model unlearning — but this is not a reliable fallback. As research in Computer Law & Security Review notes, models absorb training data in ways that can't be cleanly reversed, and behavior after attempted erasure is unpredictable. Keeping sensitive data out of training sets in the first place remains the only dependable control.
Runtime Security: Enforcing Data Protection at Every AI Decision Point
Why Perimeter Security Falls Short
Traditional firewalls, DLP tools, and code scanners operate on known signatures. They have no visibility into the semantic content of model inferences, the intent of tool calls, or the data being passed between agents. OWASP makes this explicit: LLMs are not deterministic, auditable security enforcement mechanisms, and system prompts alone cannot substitute for independent guardrails.
This gap is where AI-native runtime enforcement operates.
What Runtime Enforcement Looks Like
PromptHalo's runtime security platform sits inline on every inference, tool call, and agent-to-agent handoff — making allow, restrict, challenge, deny, or monitor decisions in under 100ms before execution. The platform deploys via API gateway, agent mode, or inline middleware, integrating with existing AI infrastructure without model retraining or code rewrites. Deployment takes under a day.
The platform's agent-level controls provide granular authority management through:
- Security passports — signed credentials carrying each agent's authorized scope and constraints
- Risk profiling — real-time risk assessment on every action
- Authority decay — agent permissions that diminish across time and accumulated risk, forcing re-authorization at defined thresholds
- Per-action budget enforcement — scope limits applied at the individual action level, not as blanket permissions
Audit Trails for Security and Compliance
Every enforcement decision generates an append-only, tamper-evident log capturing the decision, its rationale, the agent identity, session context, and timestamp. Security teams can replay these logs to reconstruct the full sequence of agent actions and decisions for any incident.
Each audit trail maps to recognized compliance frameworks:
- OWASP LLM Top 10 — covers the attack categories most relevant to LLM deployments
- NIST AI RMF — aligns with federal risk management requirements for AI systems
- EU AI Act — supports documentation obligations for high-risk AI applications
These aren't just useful for security operations. They're what regulators and auditors ask for when something goes wrong.
Navigating Regulatory Requirements for AI Data Protection
The Core Frameworks
| Framework | Scope | Key AI Obligation |
|---|---|---|
| GDPR | EU personal data | Data minimization, purpose limitation, right to erasure |
| EU AI Act | High-risk AI systems | Data governance (Art. 10), automatic logging (Art. 12), human oversight (Art. 14) |
| HIPAA | US health data | PHI use/disclosure, minimum necessary, safeguards |
| PCI DSS | Payment card data | Any AI system processing cardholder data is in scope |
| CCPA/CPRA | California consumer data | ADMT regulations effective January 1, 2026, with consumer opt-out rights |
The EU AI Act is rolling out progressively: prohibitions applied from February 2025, GPAI rules from August 2025, and high-risk AI system requirements from August 2026.
The Emerging Accountability Expectation
Regulators increasingly expect organizations to produce documentation of AI decision-making — what data was processed, what decisions were made, and what controls were in place. The NIST AI RMF's GOVERN function establishes accountability structures; MEASURE 2.8 addresses transparency and accountability risks. Security teams that map controls to both frameworks now are building the documentation trail regulators will eventually demand.
Agentic AI Scrutiny in Regulated Industries
Autonomous agents that send emails, call APIs, and access databases on behalf of users create accountability gaps that financial regulators are already examining. Key regulatory signals are already in the record:
- FINRA's 2026 observations flag unintentional disclosure of proprietary information as a specific AI-agent risk
- The FCA's Mills Review notes agentic AI may execute investment portfolios and payment transactions autonomously
- Senior manager accountability under existing frameworks doesn't disappear just because an agent took the action
For fintech, payments, and healthcare organizations, operating agentic AI without documented controls and audit trails is a regulatory exposure, not just a security one.
Frequently Asked Questions
How can I protect sensitive data when using AI?
Classify and minimize data before it enters any AI system, apply access controls and encryption across the full pipeline — including retrieval layers and vector stores — and enforce runtime monitoring to detect and block data leakage during inference and tool execution. No single control is sufficient; protection requires coverage at every layer.
Which AI tools are best for protecting sensitive data?
The right tools depend on where protection is needed: data masking and tokenization for input sanitization, ML-based detection for anomaly monitoring, and runtime enforcement platforms like PromptHalo for agentic environments requiring real-time control across every inference and tool call.
What is prompt injection and how does it expose sensitive data?
Prompt injection is an attack where malicious instructions (embedded in user inputs or retrieved content) manipulate an AI model into bypassing its controls. A successful injection can cause the model to reveal sensitive data, expose system context, or execute unauthorized actions using data it already has access to.
How does agentic AI create new risks for sensitive data?
Agentic AI systems autonomously call APIs, read databases, and pass outputs to other agents — creating multiple points where sensitive data can be accessed or exfiltrated without human review. Each action in a multi-agent chain is a potential leakage point, making runtime enforcement on every action non-negotiable.
What regulations apply to AI systems that handle sensitive data?
Depending on data type and jurisdiction, applicable frameworks include GDPR, the EU AI Act, HIPAA, PCI DSS, CCPA, and emerging state-level AI statutes — all of which increasingly require documented controls, audit trails, and risk assessments for AI systems handling personal or financial data.
What is the difference between traditional data security and AI data security?
Traditional data security protects data at rest and in transit using perimeter controls and known-pattern detection. AI data security must also address inference-layer threats — prompt injection, model inversion, retrieval poisoning, and autonomous agent actions — that conventional tools cannot see.


