Introduction
Enterprises are deploying AI faster than they can secure it. Traditional security testing was never designed for systems that behave probabilistically, respond differently to identical inputs, and can be manipulated through plain language alone.
The stakes are concrete. Stanford HAI's 2025 AI Index recorded 233 AI-related incidents in 2024 — a 56.4% increase over 2023 — based on public media reports alone, meaning actual numbers run higher.
IBM's 2025 data breach research found that 13% of organizations had already experienced breaches of AI models or applications, with 97% of those lacking proper AI access controls.
Regulators are responding. The EU AI Act mandates adversarial testing for high-risk AI systems, with broad enforcement from August 2026.
This guide explains what AI red teaming is, why every organization deploying AI needs it, the specific attack vectors it surfaces, and a practical implementation path for security teams to act on.
Key Takeaways
- Structured adversarial testing built for AI systems covers vulnerabilities traditional pen testing cannot detect.
- The AI attack surface includes prompts, model behavior, training data, retrieval pipelines, and autonomous tool calls.
- Effective programs follow a six-step cycle: scope, threat model, test, analyze, remediate, and retest continuously.
- NIST AI RMF, MITRE ATLAS, OWASP LLM Top 10, and the EU AI Act set the compliance framework for AI red teaming.
- Without a closed loop into runtime enforcement, discovered vulnerabilities remain open attack paths.
What Is AI Red Teaming?
AI red teaming is a structured, adversarial testing methodology designed to probe AI systems — large language models, agentic AI, and AI-powered applications — for vulnerabilities, unsafe behaviors, and exploitable attack paths before real attackers find them.
The core distinction from traditional security testing lies in determinism. Conventional tools test systems where the same input always produces the same output. AI systems are probabilistic: their responses vary across identical prompts, they can be manipulated through natural language, and their failure modes — hallucinations, jailbreaks, prompt injection — don't appear in standard vulnerability databases.
How AI Red Teaming Differs from Traditional Penetration Testing
Traditional penetration testing targets infrastructure: networks, servers, APIs, and access controls. AI red teaming targets model behavior, training data integrity, inference pipelines, and the logic governing how the AI makes decisions.
Both disciplines are necessary — and neither replaces the other.
| Dimension | Traditional Pen Testing | AI Red Teaming |
|---|---|---|
| Primary target | Infrastructure, APIs, access controls | Model behavior, prompts, training data |
| Failure modes | CVEs, misconfigurations | Jailbreaks, hallucinations, prompt injection |
| Attack medium | Network packets, code exploits | Natural language, crafted inputs |
| Tooling | Scanners, exploit frameworks | Adversarial prompt libraries, LLM orchestrators |

The attack surface expands further with agentic AI. Autonomous tool calls, RAG retrieval pipelines, and multi-agent handoffs introduce vectors that neither traditional pen testing nor standard LLM red teaming was built to cover.
AI red teaming addresses this across two dimensions simultaneously:
- Security testing — protecting the AI system from malicious actors
- Safety testing — preventing the AI from producing harmful, biased, or out-of-scope outputs
Missing either dimension leaves exploitable gaps — in model behavior, in compliance posture, or both.
Why Your Organization Needs AI Red Teaming
AI systems are embedded in high-stakes workflows: customer service, financial decisions, compliance processes, automated transactions. Failure in these contexts carries real consequences — not theoretical ones.
The IBM data makes this concrete: 63% of breached organizations either lacked an AI governance policy or were still developing one. Organizations with high shadow AI usage saw breach costs averaging $670,000 more than those with low or no shadow AI exposure.
The Unique AI Vulnerability Landscape
AI-specific threats cannot be caught by firewalls, DLP tools, or code scanners. Attacks like prompt injection, jailbreaks, retrieval poisoning, and sensitive data leakage through agent tool calls don't require backend access — they exploit the model through its natural interface.
As organizations move from chatbots to autonomous AI agents with tool access, the consequences of a successful attack escalate from bad output to real-world action:
- Unauthorized financial transactions
- Data exfiltration through tool calls
- Lateral movement across connected systems
The OWASP Top 10 for Agentic Applications 2026 (published December 2025) names the core risks directly: ASI01 Agent Goal Hijack, ASI02 Tool Misuse, and ASI03 Identity & Privilege Abuse. These aren't edge cases — they're the primary attack patterns against agentic systems.
Regulatory and Compliance Drivers
Adversarial testing has moved from best practice to compliance requirement:
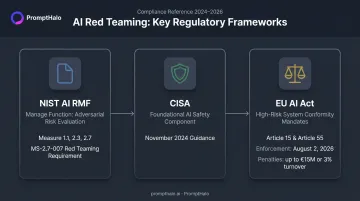
- NIST AI RMF: Adversarial and red-team testing appears in the Measure function (Measure 1.1, 2.3, 2.7). NIST AI 600-1 includes MS-2.7-007 specifically requiring red teaming for prompt injection and malicious code generation.
- CISA: Published formal guidance in November 2024 framing AI red teaming as a foundational component of AI safety and security evaluation.
- EU AI Act: Article 15 mandates adversarial testing for high-risk AI systems; Article 55 requires documented adversarial testing for general-purpose models with systemic risk. Full enforcement begins August 2, 2026, with penalties up to €15M or 3% of worldwide turnover for noncompliance.
For security teams, the practical payoff is direct: red teaming produces the audit trails regulators expect and surfaces exploitable paths before they appear in an incident report.
Key AI Attack Vectors Red Teaming Uncovers
Prompt Injection and Jailbreaks
These are the most prevalent attack classes against deployed AI systems.
Prompt injection splits into two forms:
- Direct injection — overrides system instructions through the user input itself
- Indirect injection — embeds malicious directives in external content the AI processes (documents, emails, retrieved data)
Jailbreaks use roleplay, encoding, multi-turn escalation, and logic traps to bypass safety guardrails. The severity is not theoretical: 2025 research published on arXiv using HarmBench with 200 harmful behaviors demonstrated 93.0% attack success rate (ASR) against GPT-4o and 96.5% ASR against Llama-3.1-405B using adversarial LLMs as attackers. An ensemble approach reached 100% ASR against Llama-3.1-405B.
OWASP lists prompt injection as LLM01:2025 — the top risk in the LLM Top 10. MITRE ATLAS catalogs it under AML.T0051.
Agentic-Specific Attack Vectors
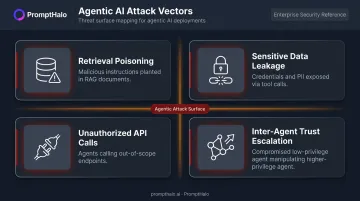
The attack surface that most security tools cannot see includes:
- Retrieval poisoning — planting malicious instructions in documents a RAG system will surface and treat as trusted input
- Sensitive data leakage — tool calls that inadvertently expose credentials, PII, or proprietary data during agent operations
- Unauthorized API calls — agents calling tools or endpoints outside their intended scope
- Inter-agent trust escalation — a compromised low-privilege agent manipulating a higher-privilege one in multi-agent pipelines
These vectors require red teaming that specifically targets multi-step, multi-agent workflows — not just single-turn LLM interactions.
Training and Supply Chain Risks
Two distinct risks belong in every red teaming scope:
- Data poisoning — manipulated training examples that corrupt model behavior at the source, often without any visible signal until the model is under adversarial conditions
- Supply chain compromise — malicious plugins, adapters, or third-party model components that introduce backdoors persisting through deployment
Red teaming should explicitly probe both: test model outputs for signs of poisoned behavior and audit every third-party component in the model pipeline for tampered artifacts or hidden triggers.
How to Implement AI Red Teaming
Step 1: Define Scope and Objectives
Identify which AI systems to test — LLMs, agentic workflows, RAG pipelines, or the full application stack. Define realistic threat actors for your context and clarify which assets need protection.
Scope definition shapes everything. Testing everything at once produces unfocused results that are difficult to prioritize or act on.
Step 2: Build a Threat Model and Risk Profile
Map the AI system's capabilities, data access, and tool permissions against relevant attack categories. Use MITRE ATLAS tactics or the OWASP LLM and Agentic Top 10 as your starting taxonomy.
Prioritize based on:
- Exploitability of the vulnerability
- Business impact of a successful attack
- Autonomy level of the system being tested (higher autonomy = higher blast radius)
Step 3: Execute Testing in a Controlled Environment
Never test against production. Use a staging environment that mirrors production conditions.
Effective programs combine three testing modes:
- Manual testing — human creativity surfaces novel attack patterns automated tools miss
- Automated scanning — provides scale, consistency, and regression coverage
- Adversarial simulation — structured red team exercises that replicate realistic attacker behavior end-to-end
The right balance depends on your maturity and threat model. Most teams use automation for broad coverage and human testers for depth and novel discovery.
Step 4: Analyze, Score, and Report Findings
AI systems produce probabilistic outputs, so findings require statistical framing. Report attack success rates across multiple attempts, not binary pass/fail results.
Score severity based on:
- Exploitability — how easily an attacker can reproduce the attack path
- Blast radius — the scope of damage if the vulnerability is triggered
- Autonomy exposure — whether the system can act on a successful attack without human review
Every finding must be reproducible. Document the exact inputs, model version, and conditions that triggered each vulnerability.
Step 5: Remediate and Retest
Findings should drive concrete mitigations: guardrail updates, input filtering, tool permission scoping, retrieval pipeline hardening. Retest after each fix to confirm resolution and prevent regression.
Keep a versioned attack library so previously discovered vulnerabilities are re-validated each time the system changes — not just when a new test cycle begins.
Step 6: Integrate into CI/CD and Establish a Continuous Cadence
AI models evolve through updates, fine-tuning, and prompt changes — and each change can reintroduce vulnerabilities you already fixed. Structured testing cadence by risk tier prevents coverage gaps from accumulating.
Recommended cadence by risk tier:
| Risk Tier | Automated Testing | Manual Testing |
|---|---|---|
| High-criticality systems | Every deployment / weekly | Monthly |
| Medium-criticality systems | Every deployment | Quarterly |
| Lower-criticality systems | Every deployment | Bi-annually |

Embed automated red teaming checks in deployment pipelines so no change reaches production untested.
Tools and Frameworks for AI Red Teaming
Key Frameworks
Four frameworks provide the structural foundation for AI red teaming programs:
- NIST AI RMF — adversarial testing sits in the Measure function (1.1, 2.3, 2.7); provides governance structure and maps directly to NIST AI 600-1 requirements
- MITRE ATLAS — AI-specific attack taxonomy extending ATT&CK with 16 tactics, 170 techniques, and 57 case studies; enables consistent finding classification
- OWASP LLM Top 10 (2025) and OWASP Top 10 for Agentic Applications 2026 — practical vulnerability categories for LLMs and autonomous agents respectively
- EU AI Act — compliance requirement for high-risk systems and GPAI models with systemic risk; full enforcement from August 2026
Testing Tools
These frameworks define what to test for. The tools below determine how you test:
- Microsoft PyRIT — enterprise-grade orchestration with 53+ adversarial datasets, 70+ prompt converters, and Azure AI Foundry integration; tests content risks and agentic risks including sensitive data leakage and task adherence
- NVIDIA Garak — LLM vulnerability scanner with 198 distinct probe classes covering hallucination, data leakage, prompt injection, toxicity, and jailbreaks; well-suited for systematic regression testing
- Promptfoo — LLM testing with CI/CD integration (GitHub, GitLab, Jenkins), covers direct and indirect prompt injection, tailored jailbreaks, PII leakage, and insecure tool use; includes EU AI Act alignment documentation
Most mature programs combine open-source tooling with commercial platforms that layer on automation, compliance reporting, and managed services. Automated tools deliver coverage and consistency; human testers supply the creativity to find what scanners miss. In practice, you need both.
From Red Teaming Findings to Real-Time Defense
Most organizations overlook a critical gap: red teaming that ends with a findings report leaves the organization exposed until mitigations deploy — and even then, new attacks will emerge.
Findings are only actionable when they feed directly into runtime enforcement.
PromptHalo's platform addresses this gap through a closed-loop architecture. Its red teaming capability continuously attacks agents, RAG layers, and tool chains to surface exploitable paths before deployment. Every attack pattern discovered is encoded into a shared Threat Library that trains the runtime enforcement engine, so protection compounds over time rather than decaying between test cycles.
The enforcement layer then sits inline on every inference, tool call, and agent-to-agent handoff. It makes per-action decisions in under 100ms:
- Allow — request proceeds as normal
- Restrict — scope or output is narrowed
- Challenge — step-up verification triggered
- Deny — action blocked entirely
- Monitor — flagged for review without interrupting flow
For regulated environments — financial services, payments, compliance-sensitive workflows — this feedback loop matters beyond security. Decision-level, replayable, tamper-evident audit logs mapped to OWASP LLM Top 10, NIST AI RMF, and EU AI Act requirements provide the evidence-grade documentation that regulators and customers expect.
Discovery without enforcement is just a to-do list. The two have to work together — and they have to work continuously.
Frequently Asked Questions
What is automated red teaming?
Automated red teaming uses software tools and AI-driven agents to generate and execute adversarial attacks at scale, enabling systematic coverage and regression testing as AI systems evolve. Human expertise remains essential for discovering novel attack patterns that automated tools cannot anticipate — the two approaches complement rather than replace each other.
What is an example of red teaming in AI?
A security team testing an AI-powered customer service agent might attempt prompt injection to extract internal system instructions, try roleplay jailbreaks to bypass content guardrails, or feed malicious documents through the RAG pipeline that the agent then executes as instructions.
Which AI is best for red teaming?
No single model is best. Effective programs combine purpose-built tools like Microsoft PyRIT and NVIDIA Garak with human expertise; some programs also use adversarial LLMs to generate attack variants at scale. Tool selection should match the specific AI system being tested and the threat model in scope.
How does AI red teaming differ from traditional penetration testing?
Traditional pen testing targets deterministic infrastructure — networks, APIs, access controls — using known vulnerability patterns. AI red teaming targets probabilistic model behavior, prompts, training data integrity, and AI-specific attack vectors like jailbreaks and prompt injection that traditional scanners and exploit frameworks cannot detect.
How often should organizations conduct AI red teaming?
Continuous rather than point-in-time. Automated testing should run with every model update or deployment; manual expert exercises should occur at least monthly for high-risk systems.
What frameworks and regulations require or support AI red teaming?
NIST AI RMF includes adversarial testing in its Measure function; MITRE ATLAS provides the attack taxonomy; OWASP publishes the LLM Top 10 and Agentic Top 10. The EU AI Act mandates adversarial testing for high-risk AI systems and GPAI models with systemic risk, with full enforcement and financial penalties applicable from August 2026.


