The problem: done wrong, red-teaming is an expensive way to produce a report that collects dust while production systems stay just as exposed.
McKinsey's 2025 State of AI survey reports 88% of organizations use AI regularly in at least one business function. IBM found 42% of enterprise-scale companies have actively deployed AI — with another 40% experimenting. That's a massive production attack surface. Meanwhile, NIST AI 600-1, the EU AI Act, and EO 14110 all explicitly require adversarial testing for AI systems. The compliance pressure is real.
This article makes the case for when GenAI red-teaming actually works, when it fails, and what must come next.
Key Takeaways
- GenAI red-teaming operates on probabilistic behavior and semantic attack surfaces, not deterministic code — the testing rules are fundamentally different.
- Generic jailbreak libraries find yesterday's vulnerabilities. Effective testing is application-specific and architecture-aware.
- Agentic AI raises the stakes categorically: a compromised agent doesn't produce a bad response, it executes a bad action.
- Every red-team engagement is a point-in-time snapshot. Model updates, new tools, and retrieval corpus changes all reopen gaps that were previously closed.
- Mature programs pair red-teaming with runtime enforcement: findings become enforcement rules, not filed reports.
The Security Theater Case: Where GenAI Red-Teaming Falls Short
Most enterprise red-team exercises follow a familiar pattern: scope a test, run it, receive findings, patch the obvious jailbreaks, and mark the AI as reviewed. The problem is the assumption that passing a test means staying secure.
The Non-Determinism Problem
Traditional penetration testing works because deterministic systems behave consistently: the same input produces the same output. LLMs don't. A prompt that fails on Monday can succeed on Tuesday with minor rephrasing. Research published in the Harvard Data Science Review documented this directly — GPT-4's accuracy on prime-number identification fell from 97.6% to 2.4% between the March and June 2023 versions of the same model. Silent, dramatic behavioral change across versions, with no warning.
NIST AI 600-1 responds to exactly this reality by calling for adversarial testing at a regular cadence and requiring risk re-assessment after fine-tuning or RAG implementation: not a one-time gate, but an ongoing control.
Why Generic Test Suites Miss the Real Threat
Most red-teaming efforts rely on pre-built prompt libraries targeting well-known jailbreaks: DAN-style attacks, role-play bypasses, language obfuscation. These find vulnerabilities that are already documented and partially mitigated.
The most dangerous failures come from context-dependent, application-specific interactions — attack paths that emerge from your system prompt, your retrieval corpus, and your tool permissions combined. Scope misalignment compounds this: many exercises test the foundation model in isolation. Attackers don't attack the model. They attack the application built on top of it. The actual attack surface includes:
- System prompt configuration and injection opportunities
- RAG retrieval layer and knowledge base integrity
- Tool and API call permissions granted to the agent
- Output handling and downstream system trust
Testing only the model misses most of this.
The Organizational Failure Mode
Red-teaming is typically introduced post-build, pre-launch — the worst possible moment. Findings arrive when development teams are under pressure to ship, producing partial remediation or risk acceptance that looks like a security decision but isn't. Without a feedback loop that connects findings to actual runtime controls, the exercise produces a report, not protection.
What Makes Red-Teaming for GenAI Actually Work
Effective GenAI red-teaming shifts the central question from "can I break the model?" to "can I turn this specific application against its own logic?" That requires understanding the full architecture before crafting a single prompt.
Application-Specific Threat Modeling First
Before any testing begins, map the actual threat model for the deployment context. A financial services AI agent that can initiate transactions has a fundamentally different risk profile than a customer support chatbot. Effective threat modeling covers:
- Attack surfaces: inputs, system prompts, retrieval sources, tool calls, outputs, and inter-agent handoffs
- Adversary profiles: external attackers, malicious insiders, indirect injection via third-party content
- Critical failure definitions: what does a successful attack actually cost in business terms?
Without this, red-teamers are testing abstract model behavior rather than the specific ways your system can be weaponized.
Attack Categories That Actually Matter
The OWASP LLM Top 10 2025 provides the most authoritative taxonomy for scoping coverage:
| Priority | Attack Category | Why It Matters |
|---|---|---|
| LLM01 | Prompt Injection | Direct and indirect; #1 attack vector |
| LLM08 | Vector & Embedding Weaknesses | RAG poisoning through retrieval |
| LLM06 | Excessive Agency | Agents acting beyond granted scope |
| LLM02 | Sensitive Information Disclosure | Data leakage through inference |
| LLM07 | System Prompt Leakage | Confidential config exposure |
The research benchmarks are sobering. A 2023 study reported an 86.1% success rate for a prompt injection toolkit against LLM-integrated applications. PoisonedRAG research demonstrated 90% attack success when injecting five malicious texts per target question into a large knowledge base. These aren't production prevalence figures — but they illustrate what effective, targeted attacks achieve against realistic systems.

Continuous Testing Over Point-in-Time Audits
Because model behavior changes with foundation model updates, new tool integrations, and retrieval corpus shifts, red-teaming must be embedded in the AI development lifecycle. Three phases matter:
- Pre-deployment — design-time evaluation against the threat model before any code ships
- Pre-release regression — adversarial testing on every significant model update, tool addition, or prompt change
- Post-deployment drift monitoring — continuous behavioral monitoring to catch silent changes between formal test cycles
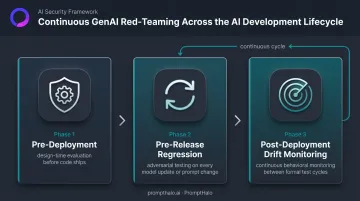
PromptHalo's red-teaming capability is built around this model — probing agents, RAG layers, and tool chains across multi-step, multi-agent workflows. Results come back as risk-scenario-mapped reports with prioritized fixes, not raw findings. Every attack path discovered feeds directly into the runtime enforcement layer through a shared threat library, so the find-then-defend loop closes automatically.
The Agentic AI Problem: Why the Stakes Just Changed
For a standalone LLM chatbot, a successful attack produces a bad response. For an autonomous agent with permissions to query databases, call APIs, execute code, send emails, or initiate financial transactions, a successful attack produces a bad action with real-world consequences. The exposure isn't just larger — it's categorically different.
The Indirect Prompt Injection Threat
The primary agentic attack vector isn't a user typing a malicious prompt — it's malicious instructions embedded in content the agent retrieves. A poisoned document, a manipulated email, a compromised web page: any of these can hijack agent behavior without the user or operator ever seeing the adversarial instruction. Google DeepMind describes indirect prompt injection as complex, requiring constant vigilance and multiple defense layers. Research on LLM-to-LLM prompt injection in multi-agent systems shows malicious prompts can self-replicate across interconnected agents, turning a single injection into a systemic compromise.
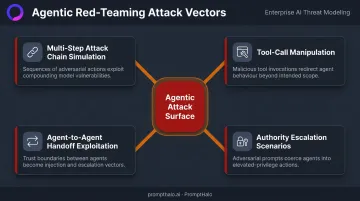
What Agentic Red-Teaming Requires
Generic single-turn LLM testing misses the entire agentic attack surface. Testing an agent properly means:
- Multi-step attack chain simulation: attacks that unfold across reasoning steps, not just one-turn prompts
- Tool-call manipulation: verifying an agent can't be tricked into invoking tools with attacker-controlled parameters
- Agent-to-agent handoff exploitation: confirming trust is never implicitly granted across agent boundaries
- Authority escalation scenarios: confirming an agent cannot self-authorize beyond its original permission grant
OWASP LLM06:2025 (Excessive Agency) formally categorizes the failure mode: damaging actions when an agent holds excessive permissions, excessive autonomy, or excessive functionality. Containing that failure mode requires external enforcement — controls that operate outside the agent itself and can't be overridden by the agent's own reasoning. PromptHalo's runtime enforcement layer does this through agent security passports that travel with each request, authority decay that prevents permissions from persisting indefinitely, and per-action budget and scope thresholds enforced externally.
Compounding Failures in Multi-Step Reasoning
Autonomous agents operate across multiple reasoning steps. Small misalignments don't stay small — they compound. A minor behavioral drift in step two of a ten-step workflow can produce a radically different outcome at step ten. Behavioral drift monitoring for agentic deployments isn't just about catching individual bad outputs — it's about detecting the early signal before compounding turns a small deviation into a harmful action.
What a Mature GenAI Red-Teaming Program Looks Like
Maturity in GenAI red-teaming comes down to three things: scope completeness, adversarial creativity, and feedback loops that actually close vulnerabilities.
The Three Components of Program Maturity
1. Scope completeness
A mature program tests the model, system prompt, retrieval layer, tool-calling logic, and multi-agent handoffs. Testing only the foundation model is the most common scope failure — and the one attackers count on.
2. Adversarial creativity
Replaying a fixed prompt library is not red-teaming. Mature teams explore semantic variations, multi-step attack chains, and context-specific exploitation paths. Automated tools generate prompt variations at scale; human judgment maps findings to actual business risk.
3. Feedback loops
Red-team findings need to become enforcement rules — not archived reports. If discovered attack paths sit in a queue rather than training runtime controls, you've generated documentation without generating protection.
Metrics Security Leaders Should Track
| Metric | What It Measures |
|---|---|
| Testing frequency | Aligned to model updates, tool additions, and deployment events? |
| OWASP LLM Top 10 coverage | Are all 10 categories tested, not just the obvious ones? |
| Novel vs. known attack detection | Can the program find attack variants not in the prompt library? |
| Mean time from finding to remediation | Are findings being acted on? |
| Findings-to-enforcement conversion | Are discoveries training runtime controls or filing as reports? |

NIST AI 600-1's GV-3.2-002 explicitly names testing, evaluation, validation, and red-teaming roles. MITRE ATLAS provides an AI-adversary technique knowledge base grounded in real-world attack observations — both are practical resources for building scope coverage frameworks.
Red-Teaming Alone Isn't Enough: The Runtime Enforcement Gap
Red-teaming is a test, not a control. It tells you where your AI is vulnerable. It does not protect production users from those vulnerabilities between now and the next test cycle.
The gap is structural. AI systems deploy continuously, attacks evolve continuously, and model behavior drifts in between test cycles. A quarterly red-team report cannot close a gap that opens in real time. Current research on guardrail benchmarks confirms the problem runs deeper: even purpose-built detection tools suffer from high false negatives in adversarial conditions and excessive false positives in benign ones. Closing that gap requires real enforcement, not just detection.
What Runtime Enforcement Actually Does
Effective runtime enforcement sits inline on every inference, tool call, and agent-to-agent handoff, making a per-action decision before the action executes. For each action, the decision is: allow, restrict, challenge, deny, or monitor.
That distinction matters because perimeter-based controls weren't built for this. WAFs, DLP systems, and traditional firewalls were designed for deterministic, network-layer threats — they don't see the semantic attack surface of AI. A prompt injection that manipulates an agent's retrieval query looks like normal application traffic to a WAF. It never triggers a rule.

PromptHalo's runtime enforcement layer operates inline with sub-100ms response latency, deploys in under a day with no model retraining and no code rewrite, and works across any AI application from any vendor. Every decision produces a tamper-evident, append-only audit log — capturing the decision, its reason, the agent passport identity, session context, and timestamp — creating the replayable evidence trail that compliance teams and incident investigators need.
The Closed-Loop Defense Model
The architecture that makes red-teaming genuinely valuable rather than theatrical is one where findings don't stop at a report. In PromptHalo's model, every attack path discovered through red-teaming is encoded into a shared threat library. That library trains the runtime enforcement engine — so a newly discovered attack pattern becomes a runtime defense without waiting for the next test cycle.
The test and the control share the same threat intelligence. Red-teaming becomes the discovery layer that continuously improves runtime protection — so protection compounds rather than resets with each engagement.
Frequently Asked Questions
Is red-teaming for generative AI the same as traditional penetration testing?
No. Traditional pen testing targets deterministic systems — networks, code, access controls — where the same input produces the same output. GenAI red-teaming targets probabilistic behavior, semantic attack surfaces, and AI-specific failure modes: prompt manipulation, hallucination, retrieval poisoning, and tool-call exploitation. Different techniques, different scope, different success criteria.
How is red-teaming an agentic AI system different from testing a standard LLM?
Agentic systems introduce attack vectors that don't exist in single-turn interactions: multi-step attack chains, indirect prompt injection through retrieved content, tool-call manipulation, agent-to-agent handoff exploitation, and authority escalation. None of these appear in standard LLM testing — the entire multi-step reasoning pipeline and tool permission structure becomes part of the attack surface.
How often should organizations red-team their GenAI systems?
At minimum, before major releases and after any significant model update, tool addition, or retrieval corpus change. NIST AI 600-1 calls for adversarial testing at a regular cadence and continuous monitoring — not one-time gates. Post-deployment behavioral drift monitoring should run continuously between formal test cycles.
Can automated red-teaming tools replace human red teamers?
No — both are necessary. Automated tools provide scale and consistency across large input spaces, generating prompt variations no human team can match in volume. Human red teamers provide adversarial creativity, contextual judgment, and the ability to discover novel attack chains that fixed prompt libraries miss entirely. The strongest programs run both together.
Does passing a red-team exercise mean an AI system is secure in production?
No. Red-teaming is a snapshot of behavior at a point in time. Model updates, new tool integrations, retrieval corpus changes, and evolving attacker techniques can all reopen vulnerabilities after a clean test. That's why runtime enforcement is a necessary complement — it enforces trust continuously, not just at test time.
What compliance frameworks reference AI red-teaming?
Several frameworks include specific provisions:
- NIST AI 600-1: MS-2.7-007 requires red-teaming against prompt injection; MS-4.2-001 requires adversarial testing at a regular cadence
- EU AI Act: Article 55 requires adversarial testing for GPAI models with systemic risk; Article 15 requires robustness against adversarial examples for high-risk systems
- OWASP LLM Top 10 2025: Structured vulnerability taxonomy that defines red-team scope
- EO 14110: Section 4.2(a)(i)(C) requires reporting red-team results for covered dual-use foundation models