Most organizations conduct penetration tests annually — sometimes quarterly if they're diligent. Meanwhile, Mandiant's M-Trends 2026 report shows attackers maintain a median dwell time of 14 days before detection. And Verizon's 2024 DBIR found organizations take 55 days on average to remediate 50% of critical known-exploited vulnerabilities. That gap between scheduled tests and continuous change is exactly where breaches happen.
Continuous Automated Red Teaming (CART) was built to close that gap. This guide covers what CART is, how its attack cycle works, what it simulates, how it compares to traditional red teaming and BAS, and why it's become especially critical as enterprises deploy autonomous AI systems.
Key Takeaways
- CART runs attack simulations continuously, catching new vulnerabilities the moment they're introduced rather than waiting for a scheduled test
- It chains multiple attack techniques into realistic end-to-end paths rather than running isolated vulnerability checks
- CART complements human red teams; it automates the repeatable work so experts focus on creative, complex scenarios
- AI-focused CART adds prompt injection, RAG poisoning, and agent-to-agent trust exploitation — attack classes conventional tools weren't built to handle
- CART generates audit-ready evidence mapped to NIST CSF, PCI DSS, ISO 27001, and GDPR
What Is Continuous Automated Red Teaming (CART)?
CART is an offensive security practice that uses automated tooling and AI to simulate real-world adversary tactics, techniques, and procedures (TTPs) on a continuous basis — not once a year — across an organization's infrastructure, applications, and networks.
The "Continuous" Distinction
A traditional penetration test is a point-in-time snapshot. It tells you where you stood on the day the testers were in your environment. CART runs on an ongoing loop, so vulnerabilities introduced by a configuration change, a software update, or a new employee's misconfigured access get caught immediately rather than sitting exposed for months.
Rapid7's 2026 Global Threat Landscape Report found the median time from vulnerability publication to CISA Known Exploited Vulnerability (KEV) listing dropped from 8.5 days to 5.0 days. A yearly pen test cannot keep pace with that.
The "Automated" Component
Automated decision engines map attack paths, chain exploitable weaknesses, and replicate how a skilled adversary pivots through an environment — without constant human intervention.
These engines follow established frameworks:
- NIST SP 800-115 — defines the penetration testing lifecycle: Planning, Discovery, Attack, and Reporting
- MITRE ATT&CK — provides the TTP vocabulary that makes findings traceable and comparable across engagements
What CART Is NOT
| Capability | CART | Vulnerability Scanner |
|---|---|---|
| Finds known weaknesses | ✅ | ✅ |
| Chains findings into realistic attack paths | ✅ | ❌ |
| Validates detection controls | ✅ | ❌ |
| Runs continuously | ✅ | Sometimes |
| Requires human creativity for novel scenarios | ❌ | ❌ |
CART does not replace human-led red team exercises for novel, social engineering-heavy, or business-logic scenarios. It automates the repeatable, scalable portions.
How CART Works: The Attack Cycle Stages
CART follows a structured cycle that mirrors established penetration testing methodology while adding automation and continuity at each stage.
Stage 1 — Objective Setting and Scoping
Every CART run begins with a clear definition of what a successful attack would mean. Examples:
- Obtaining domain administrator privileges
- Exfiltrating a defined set of sensitive records
- Reaching a payment processing system
Scoping rules define which assets are in bounds, set time and depth limits, and prevent operational disruption. Without this, automated attack tools can cause unintended outages.
Stage 2 — Reconnaissance and Credential Harvesting
Automated tools enumerate users, groups, DNS configurations, and trust relationships to build an accurate map of the environment. Credential harvesting identifies potential pivot points. This mirrors exactly what a real attacker does before touching anything critical — and it's a phase that too many assessments skip or abbreviate.
Stage 3 — Attack Path Discovery and Execution
An intelligence decision engine chains harvested data into the stealthiest viable attack path, then executes:
- Lateral movement
- Privilege escalation
- Pass-the-ticket attacks
- WMI execution
- UAC bypass
If the engine hits a dead end, it adapts and tries alternative paths, exactly as a persistent adversary would. Each path maps to MITRE ATT&CK TTP IDs, making every move traceable and auditable.
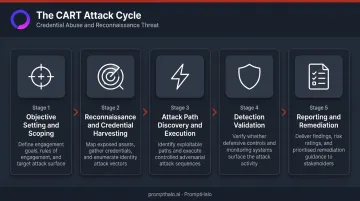
Stage 4 — Detection Validation
While the attack runs, the system simultaneously evaluates whether detection controls fire as expected. Controls measured include:
- SIEM alert fidelity
- EDR telemetry coverage
- SOC playbook response
Gaps between what was simulated and what was detected surface as measurable findings, not assumptions.
This is where CART delivers something pen testing rarely can: a clear answer to "did our controls actually work?"
Stage 5 — Reporting and Remediation Feedback
CART produces a documented, replayable record of every attack path found, including:
- Severity rankings based on actual exploitability
- The specific technique chain used
- Remediation recommendations prioritized by real risk, not theoretical CVSS scores
FIRST's EPSS data illustrates why this matters: a CVSS 7+ prioritization strategy operates at only 3.96% efficiency, while an EPSS 10% threshold reaches 65.2% efficiency with 2.7% of the effort. CART generates the exploitability evidence your team needs to apply that EPSS threshold in practice — shifting remediation from guesswork to ranked, defensible decisions.
What Types of Attacks Does CART Simulate?
Primary Attack Categories
CART can emulate a broad range of adversary behaviors:
- Reconnaissance and OSINT harvesting — passive and active enumeration of exposed assets
- Credential attacks — password spraying, credential stuffing, phishing simulation
- Web and API exploitation — SQLi, XSS, parameter tampering, authentication bypass
- Privilege escalation and lateral movement — moving from low-privilege access toward high-value targets
- Command-and-control (C2) and data exfiltration — beaconing, data staging, exfil over allowed channels
- Cloud and IAM misconfiguration abuse — over-permissioned roles, public storage buckets, identity federation gaps
What separates CART from point-in-time testing is how these techniques combine into realistic attack sequences.
Chained, Multi-Stage Attack Paths
CART chains individual techniques into end-to-end sequences that mirror how actual breaches unfold. A realistic attack path looks like this:
Credential harvest → Lateral movement → Privilege escalation → Data exfiltration
This end-to-end simulation shows the actual blast radius of a successful breach, not just where a single control failed. Verizon's 2024 DBIR analyzed over 30,000 incidents and found vulnerability exploitation increased 180% year-over-year as an initial access vector.
Keeping Playbooks Current
Those attack chains only hold value if they reflect how adversaries are operating today. Rapid7 found that confirmed exploitation of newly disclosed CVSS 7-10 vulnerabilities rose 105% year-over-year — from 71 to 146 incidents. CART content libraries should continuously update against the KEV catalog and current adversary tradecraft, keeping pace with the threat landscape rather than trailing it.

CART vs. Traditional Red Teaming and Breach and Attack Simulation
CART vs. Traditional Red Teaming
Traditional red teaming is manual, infrequent, and scoped to a finite engagement. It delivers something automation genuinely cannot replicate: expert creativity, complex social engineering, and the kind of outside-the-box thinking that finds flaws no scanner would discover. Under EU DORA, designated financial entities are required to conduct threat-led penetration testing at least every three years; PCI DSS v4.0.1 requires penetration testing at least annually. These are floors, not ceilings.
CART fills the months-long gaps between those engagements. The two approaches are complementary:
| Dimension | Traditional Red Team | CART |
|---|---|---|
| Frequency | Annual / periodic | Continuous |
| Coverage | Deep, scoped engagement | Broad, ongoing |
| Novel scenarios | ✅ Excellent | ❌ Limited |
| Scalability | Constrained by headcount | High |
| Detection validation | Sometimes | Always |
CART vs. Breach and Attack Simulation (BAS)
BAS tests whether predefined security controls block or log known techniques. It answers: did my firewall block this specific technique? That's useful for control validation, but it starts from a fixed playbook.
CART goes further. Rather than validating a predetermined set of controls, CART dynamically explores unknown attack paths based on what it discovers in the environment. The difference in scope:
- BAS: "Does my armor stop this bullet?"
- CART: "Find every way an attacker could reach my crown jewels."
For organizations that want both, running BAS for control validation alongside CART for continuous adversary emulation closes the gap between point-in-time testing and real-world exposure.

Key Benefits and Challenges of CART
Benefits
- Surfaces vulnerabilities as environments change, not weeks after the fact
- Measures detection gaps continuously — you know when controls fail as it happens, not at the next scheduled test
- Enterprise-scale coverage without proportional increases in headcount
- Prioritizes remediation by actual exploitability and attack path, not CVSS scores alone
Challenges
CART isn't plug-and-play. Implementation friction is real:
- Integration complexity with existing SIEM, EDR, and SOAR stacks requires careful tuning before automation scales. The SANS 2024 Detection and Response Survey found 64% of respondents identify false positives as a major threat-detection issue, with 42% encountering false positives in 41–80% of cases.
- False positive noise erodes trust in automated findings if severity mappings are poorly tuned to the environment.
- Over-reliance risk — CART won't catch business-logic flaws, social engineering, or creative attack chains that require human judgment.
That last point matters for governance structure. CART should trigger periodic manual red-team audits of its highest-severity findings, with security, engineering, and business stakeholders in the loop — otherwise findings accumulate in reports without translating into actual remediation.
Extending CART to AI and Agentic Systems
Traditional CART was designed for network infrastructure, applications, and identity systems. It was never designed to test what modern AI deployments actually do.
The New Attack Surface
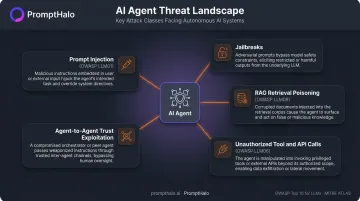
Autonomous AI agents make tool calls, retrieve from external knowledge bases, access APIs, and hand off tasks to other agents. Firewalls, DLP tools, and conventional red-teaming playbooks weren't built to test any of that. OWASP and MITRE ATLAS have formalized the attack classes that matter here:
- Prompt injection (OWASP LLM01) — malicious instructions embedded in user input or retrieved documents manipulate model behavior
- Jailbreaks — bypassing model safety guardrails through adversarial inputs
- RAG retrieval poisoning (OWASP LLM08) — corrupting the knowledge base an agent relies on, so it acts on poisoned context
- Unauthorized tool and API calls (OWASP LLM06 — Excessive Agency) — agents invoking capabilities beyond their intended scope
- Agent-to-agent trust exploitation — manipulating handoffs between agents in multi-step pipelines
MITRE ATLAS provides the adversary taxonomy for AI systems, the same way ATT&CK structures traditional red-teaming. Threat intelligence tracking has documented malware families actively querying LLMs mid-execution — a sign that AI-specific attack techniques have moved out of research and into active exploitation.
Closing the Loop Between Finding and Defending
Red-teaming an AI system is only half the solution. Once exploitable attack paths are found, runtime enforcement must block those vectors on every inference, tool call, and agent handoff — not just during the test window.
PromptHalo's AI Red Teaming solution is designed for exactly this gap. It continuously attacks agents, RAG layers, and tool chains the way a real adversary would — covering adversarial task chains across multi-step, multi-agent workflows. Core capabilities include:
- Continuous attack coverage across prompt injection, jailbreaks, poisoning attacks, and data-leakage probes
- Risk-scenario-mapped findings with prioritized, actionable fixes — not raw vulnerability lists
- A shared Threat Library that encodes each red-team discovery directly into the ML detection engine, so new attack patterns become active enforcement rules without waiting for a release cycle
The runtime layer sits inline on every inference and agent action, making per-action decisions (allow, restrict, challenge, deny, or monitor) in under 100ms.
Frequently Asked Questions
What is continuous automated red teaming?
CART is an offensive security practice that uses automated tooling to continuously simulate real-world adversary TTPs across an organization's environment. Unlike scheduled penetration tests, it runs on an ongoing loop, catching vulnerabilities as they emerge from configuration changes, software updates, or personnel shifts.
What are the stages of the attack cycle in continuous automated red teaming?
CART follows five sequential stages:
- Objective-setting and scoping
- Reconnaissance and credential harvesting
- Attack path discovery and execution (lateral movement, privilege escalation)
- Detection validation against live SIEM and EDR controls
- Reporting with prioritized remediation guidance
What types of attacks does continuous automated red teaming simulate?
CART simulates a broad range of attack types, including:
- Reconnaissance and credential attacks
- Web and API exploitation
- Privilege escalation and lateral movement
- Command-and-control beaconing
- Data exfiltration
Its defining feature is chaining these into multi-stage attack paths that reveal the actual blast radius of a breach.
What is the difference between BAS and CART?
BAS tests whether predefined security controls block known attack techniques — it validates a fixed set of scenarios. CART dynamically explores unchained attack paths based on what it discovers in the environment, making it more adaptive to unknown threat vectors and novel attack combinations.
Does CART replace traditional red teaming?
No. CART automates the repeatable, scalable components of offensive testing while human red teamers focus on creative scenarios — social engineering, complex business-logic flaws, and novel techniques that automation cannot replicate. The approaches work best when run together.
How does CART support regulatory compliance?
Continuous attack simulation generates documented, replayable evidence of security control validation. This evidence maps directly to NIST CSF (DE.CM, ID.RA-01, ID.IM-02), PCI DSS v4.0.1 Requirements 11.3 and 11.4, ISO 27001 Annex A controls 8.8 and 8.29, and GDPR Article 32(1)(d) — giving auditors the proof of proactive security posture they require.