Introduction
LLMs are now embedded across enterprise operations — customer service bots, internal developer tools, code generation assistants, and agentic systems making autonomous decisions across multi-step workflows. According to the Stanford HAI 2025 AI Index Report, AI business usage jumped to 78% of organizations in 2024, up from 55% the year before.
The security problem is straightforward to describe and genuinely hard to solve: most security teams are testing these systems with methodologies built for deterministic, rule-based software. Traditional pentests look for predictable code paths. LLMs don't have those.
That gap has a direct consequence: the attack surface has moved from infrastructure to language. Guardrails can be bypassed through natural conversation. A system that behaves safely in one context can become exploitable in another — and firewalls and DLP tools see none of it.
This post covers what makes LLM red teaming structurally different from traditional offensive security: the attack surfaces red teams evaluate, the highest-severity vulnerabilities found in production systems, and how pre-deployment testing connects to runtime enforcement in production.
Key Takeaways:
- LLMs fail non-deterministically, making traditional pentest logic insufficient
- RAG poisoning, indirect prompt injection, and tool abuse carry the highest immediate risk in production
- Red teaming must run continuously, not as a one-time pre-launch exercise
- Red team findings require runtime enforcement to matter — detection without defense is incomplete
- OWASP LLM Top 10, NIST AI RMF, and the EU AI Act now treat adversarial AI testing as a compliance baseline
Why LLMs Demand a New Breed of Offensive Security
The Non-Determinism Problem
Traditional application vulnerabilities follow deterministic logic paths. A SQL injection either works or it doesn't. An LLM fails differently: stochastically, contextually, and often inconsistently.
The same input can produce a safe response in one session and a harmful one in the next. A guardrail that blocks a direct attack may yield to a rephrased version. A system prompt that holds firm in isolation can collapse when the model is given enough conversational context.
A single test run proves almost nothing. Security teams need to generate adversarial inputs at scale and evaluate behavior statistically across many runs.
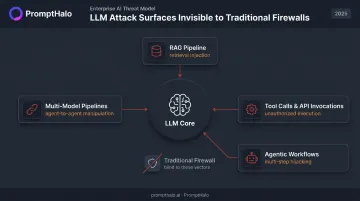
An Attack Surface Firewalls Cannot See
LLMs don't just receive user input. They also:
- Retrieve data from external sources via RAG pipelines
- Execute tool calls and API invocations
- In agentic configurations, act autonomously across multi-step workflows
- Pass instructions between agents in multi-model pipelines
Each of these creates a distinct injection or manipulation surface. A firewall inspects network packets. A DLP tool looks for known data patterns. Neither can evaluate whether an instruction embedded in a retrieved document is about to redirect an agent's behavior. That's exactly the gap where retrieval injection and agentic hijacking operate.
The Regulatory Shift
The attack surface problem hasn't gone unnoticed by regulators. Frameworks have caught up faster than most security teams expected:
- OWASP LLM Top 10 (2025) catalogs AI-specific attack vectors including prompt injection, data poisoning, and excessive agency
- NIST AI 600-1 (released July 2024) calls for regular adversarial testing of generative AI systems to identify vulnerabilities and potential misuse
- EU AI Act Article 55 requires providers of GPAI models with systemic risk to perform model evaluations including adversarial testing — red teaming is listed in Annex XI
Adversarial AI testing is fast becoming a compliance expectation, not a security nice-to-have.
The LLM Attack Surface: What Red Teams Actually Target
Red teams distinguish between two threat layers. Model-layer threats are inherent to the foundation model itself — hallucinations, harmful content generation, training data leakage, and jailbreaks on base behavior. Application-layer threats only emerge when the model is connected to tools, databases, APIs, RAG pipelines, and user interfaces.
For most enterprises building on top of existing foundation models, application-layer vulnerabilities are the primary focus. That's where the actionable risk lives.
Prompt Injection: Direct and Indirect
Direct prompt injection is the most widely understood variant: an attacker manipulates user-facing input to override system prompt instructions, hijack model behavior, or extract information. The analogy to SQL injection holds — except that the injection vector is natural language, which cannot be filtered deterministically. There is no character blocklist for English sentences.
Indirect (stored) prompt injection is more dangerous in production environments. Here, malicious instructions are embedded in data the model retrieves — emails, documents, web content, RAG knowledge bases — and execute when the model processes that content. The user never types a malicious prompt. The attack arrives through content the model was designed to trust.
A real-world example: EchoLeak (CVE-2025-32711), a zero-click vulnerability in Microsoft 365 Copilot, enabled remote unauthenticated data exfiltration through a crafted email. The attack required no user interaction — the indirect injection triggered automatically when Copilot processed the message. It was reported in January 2025 and fixed server-side in May 2025.
RAG and Retrieval Poisoning
Insecure access control in RAG architectures creates two distinct attack paths:
- Over-permissioned read access — the model surfaces documents that the querying user should not see, exposing cross-tenant data or privileged content
- Write-access poisoning — adversaries inject malicious content into the RAG data store, poisoning the retrieval pipeline and enabling indirect prompt injection at scale
Research on PoisonedRAG demonstrated a 90% attack success rate after injecting just five malicious texts into a knowledge base containing millions of documents. In practice, RAG poisoning ranks among the most exploitable findings in LLM security assessments: high impact, easy to execute, and frequently absent from threat models.

Agentic AI and Tool Abuse
Agentic AI expands the attack surface in a way static LLMs don't. When an agent can browse the web, write to databases, send emails, execute code, or trigger downstream agents, a successful prompt injection doesn't just produce bad text — it executes unauthorized actions.
Gartner predicts that 40% of enterprise applications will include task-specific AI agents by 2026, up from less than 5% in 2025. The InjecAgent benchmark found that ReAct-prompted GPT-4 agents were vulnerable to indirect prompt injection 24% of the time under standard conditions — before any attempt at adversarial optimization.
The attack surface expands with every tool an agent can call. Red teams must evaluate not just what the model outputs, but what the model can do.
How LLM Red Teaming Works: From Scoping to Exploitation
LLM red teaming shares the goal of traditional pentesting — find exploitable paths before attackers do — but the methodology differs at almost every step. Because outputs are stochastic, a single test pass tells you very little. Teams must generate thousands of adversarial inputs across multiple attack categories and evaluate behavior across runs, not just individual responses.
Defining Scope and Testing Approach
Before any engagement begins, three scoping decisions determine what the test can actually find:
- Identify the architecture : RAG pipeline, agentic system, chatbot, or multi-model pipeline. Each has a distinct threat profile requiring different probe strategies.
- Choose testing mode : black-box (input/output access only, most representative of real-world attacker conditions) vs. white-box (full access to system prompts, tool schemas, and configurations, enabling deeper structural vulnerability discovery)
- Define attacker success : data exfiltration, guardrail bypass, unauthorized tool invocation, lateral movement between agents, or business logic abuse
Scoping is where most engagements go wrong. Testing a chatbot with agentic probes wastes cycles. Missing the RAG layer entirely means the highest-risk surface goes untested.
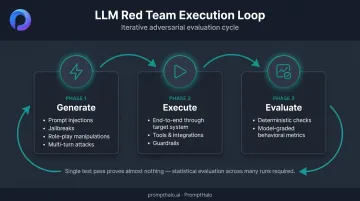
Generating and Executing Adversarial Inputs
The red team execution loop runs in three phases:
- Generate : produce diverse adversarial inputs targeting identified vulnerability categories — direct and indirect prompt injections, jailbreaks, role-play manipulations, multi-turn conversation attacks, and data exfiltration via active content rendering
- Execute : run inputs through the target system end-to-end, including all tools, guardrails, and integrations as they exist in production. Testing isolated model behavior without the application layer misses the most dangerous attack paths
- Evaluate : assess outputs using deterministic checks (did the model reveal the system prompt? did it invoke an unauthorized tool?) combined with model-graded metrics for more nuanced behavioral failures
Platforms that close this loop automatically compound protection over time. PromptHalo's approach encodes each newly discovered attack pattern into a shared threat library, converting red team findings into runtime defenses without waiting for a new release cycle.
Analysis, Prioritization, and Remediation
Not all red team findings carry equal weight. Triage should separate:
- Model-layer issues — often improve over time as foundation models advance; lower immediate priority for enterprise teams
- Application-layer vulnerabilities — higher impact, more immediately actionable, and fully within the organization's control to fix
For each high-priority finding, remediation should be specific. Common fixes include:
- Prompt engineering changes to constrain model behavior
- Output sanitization rules to block sensitive data in responses
- Access control modifications to limit tool invocation scope
- Architectural redesigns for systemic trust boundary failures
Each fix should be re-tested against the original probe set to confirm it holds. Security and development teams need risk-mapped reports with prioritized guidance — not raw vulnerability dumps.
Top Vulnerabilities Found in Production LLM Systems
RCE via LLM-Generated Code Execution
One of the most severe recurring findings in AI red team assessments: developers use LLMs to generate code for data analysis, SQL queries, or calculations, then execute that output directly using exec, eval, or similar constructs without sandboxing.
When prompt injection chains into code generation that executes without restriction, the attacker gains access to the full application environment. Real documented cases include:
- CVE-2024-5565 (Vanna library) — prompt injection could alter a prompt function and lead to code execution
- CVE-2024-12366 (PandasAI) — prompt injection could run arbitrary Python code, leading to RCE
- LangChain PALChain — prompt injection against processing pipelines could enable harmful command execution
The fix is architectural: map LLM output to a predefined allowlist of safe, permitted functions rather than executing it directly. Any necessary dynamic execution should run in an isolated sandbox with no access to the broader application environment.
Data Exfiltration via Active Content Rendering
If a UI renders markdown automatically, an attacker can weaponize LLM output to exfiltrate data. A malicious image URL embedded in the model's response encodes conversation history or session data and sends it to an attacker-controlled server in the HTTP request that fetches the image — invisibly, from the user's perspective.
Checkmarx demonstrated this against Microsoft Copilot Chat and Google Gemini through markdown injection. Mitigations include:
- Content security policies restricting image sources to approved domains
- Sanitizing LLM output to strip active content before rendering
- Displaying full URLs before activation in sensitive interfaces
- Disabling markdown rendering entirely in high-risk contexts
Jailbreaking: Bypassing Safety Guardrails
Jailbreaking attacks subvert the foundational safety constraints of an LLM. Jailbreaking attacks subvert the foundational safety constraints of an LLM. Common techniques include:
- Role-play framing — instructing the model to act as an unconstrained persona
- Hypothetical scenarios — asking the model to respond "as if" restrictions don't apply
- Persona assignment — overriding system identity through user-turn manipulation
- Iterative automated methods — systematically probing until guardrails break
Tree of Attacks with Pruning (TAP) achieved a 90% success rate against GPT-4 using an average of just 28.8 queries per prompt — outperforming all previous black-box methods. That efficiency means attackers don't need sophistication; they need persistence.

The business exposure isn't limited to harmful content generation. The Chevrolet dealer chatbot incident illustrates the range: a crafted prompt convinced the chatbot to agree to sell a 2024 Tahoe for $1. The output wasn't legally binding, but the reputational damage was immediate, public, and entirely avoidable.
Sensitive Data Leakage via Prompt and RAG Manipulation
Two distinct leakage paths appear consistently in production assessments:
- System prompt leakage — adversaries manipulate the model into revealing proprietary instructions, personas, or business logic embedded in the system prompt. This exposes competitive information and provides a roadmap for further attacks
- PII and document leakage via RAG — over-permissioned retrieval or indirect prompt injection causes the model to surface data belonging to other users or protected document sets
In multi-tenant enterprise deployments, the second path is particularly dangerous. A single misconfigured retrieval scope can expose one tenant's data to another — and the exposure may be gradual enough to evade monitoring entirely.
Catching gradual leakage requires inline inspection at the response level — before output reaches the user — with data-access policy enforced consistently across multi-step and multi-session interactions. That's where platforms like PromptHalo close the gap that traditional DLP tools miss entirely.
From Red Team Findings to Runtime Enforcement
Most organizations fall into the same gap: red teaming reveals vulnerabilities, a remediation report is generated, static fixes are applied, and the application goes to production with no mechanism to enforce what the red team learned.
Static fixes erode. Models update. Use cases expand. New attack techniques will emerge that no pre-deployment test could anticipate.
What Effective Runtime Enforcement Looks Like
Runtime enforcement means inline evaluation of every inference, tool call, and agent-to-agent handoff before it executes, with the ability to allow, restrict, challenge, deny, or monitor each action in real time.
PromptHalo's Runtime Security delivers this at every layer:
- Per-action decisions in under 100ms, inline on every inference and tool call
- Security passports per request, carrying policy, budget, and authority scope on each agent handoff
- Authority decay as agents operate, forcing re-authorization when thresholds are exceeded and preventing the privilege accumulation that agentic systems are otherwise prone to
For regulated environments, enforcement must also generate tamper-evident audit logs at the decision level. Every action is logged with its reason, agent identity, session context, and timestamp: append-only, immutable, and replayable for regulatory reporting.
The closed-loop mechanism matters: attack patterns discovered during red teaming are encoded into a shared threat library, which the runtime enforcement engine draws on continuously. What gets found in testing becomes an active defense in production without waiting for a new release cycle.
The Vendor-Agnostic Requirement
As enterprises run AI applications across multiple providers and models, runtime security must work across the full stack. PromptHalo operates without requiring access to the underlying model: no model retraining, no code rewrite, and deployment in under a day. This means security coverage doesn't depend on which model an organization uses today or migrates to tomorrow.
Gartner's prediction that more than 40% of agentic AI projects will be canceled by end of 2027 cites inadequate risk controls as a primary cause. For any agentic AI system that needs to stay in production, runtime enforcement is the baseline, not an enhancement.
Building Red Teaming Into Your AI Development Lifecycle
LLM red teaming should not be a one-time pre-launch exercise. It delivers the most value when integrated at multiple points:
| Lifecycle Stage | What It Catches |
|---|---|
| During fine-tuning | Training data poisoning, behavioral drift introduced by new data |
| Pre-deployment | Application-layer vulnerabilities that emerge when the model connects to tools, databases, and APIs |
| Continuous CI/CD | Regressions as prompts change, models update, or new attack techniques emerge |
The OWASP GenAI Red Teaming Guide (January 2025) includes a Secure CI/CD Pipeline solution taxonomy — adversarial testing in continuous integration is no longer a theoretical recommendation.
The Compliance Dimension
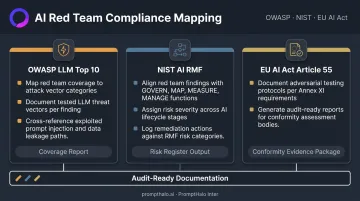
Regulatory expectations are hardening. Teams should:
- Map red team coverage to OWASP LLM Top 10 categories and document which vectors were tested
- Align findings with NIST AI RMF risk management actions across the AI lifecycle
- For EU-facing deployments, ensure adversarial testing documentation satisfies EU AI Act Article 55 and Annex XI requirements
- Produce audit-ready reports, not just internal findings documents
CISA joint guidance now recommends offensive security assessments and AI red teaming to regularly evaluate AI system functions, identify vulnerabilities, and test resilience.
Addressing the Talent Gap
Effective LLM red teaming requires a multidisciplinary skill set:
- Offensive security tradecraft (adversarial mindset, exploitation techniques)
- AI/ML knowledge (understanding model behavior, RAG architecture, agentic systems)
- Domain context (understanding what "harmful output" actually means in a regulated financial services environment vs. a developer tool)
ISACA's 2025 AI Pulse Poll found 89% of digital trust professionals say they need more AI skills and knowledge to advance their careers. That shortage is already affecting security program quality.
Organizations should assess whether to build internal capability, partner with specialized providers, or use automated red teaming platforms. Strong traditional pentesting skills don't automatically transfer to non-deterministic, language-driven attack surfaces — the discipline requires a distinct approach.
Frequently Asked Questions
What is the difference between AI red teaming and traditional red teaming?
Traditional red teaming targets deterministic infrastructure and application vulnerabilities using known exploit patterns and code paths. AI red teaming tests LLM-specific vectors like prompt injection, jailbreaking, and RAG poisoning under a methodology built for the non-deterministic, language-driven nature of AI systems, requiring statistical evaluation across many test runs rather than binary pass/fail checks.
What is the difference between a prompt injection and a jailbreak?
Prompt injection chains untrusted external or user input with trusted developer-authored prompts to hijack model behavior often covertly, without the user's awareness. Jailbreaking attempts to override the model's built-in safety constraints through adversarial prompt crafting, role-play manipulation, or persona assignment targeting the model's foundational guardrails.
What are the highest-priority vulnerabilities to test in an LLM application?
Application-layer vulnerabilities carry the greatest immediate risk and are fully within an organization's control to fix:
- RAG access control failures and indirect prompt injection via retrieved content
- LLM-generated code execution without sandboxing
- Active content rendering for data exfiltration
- Unauthorized tool or API invocations in agentic systems
How often should organizations red team their LLM applications?
Red teaming should happen at multiple lifecycle points: pre-deployment, after model or prompt changes, and continuously in CI/CD pipelines. LLM attack surfaces evolve as models update and new adversarial techniques emerge, so yesterday's passing test may not reflect today's risk.
Can red teaming alone protect an LLM application in production?
No. Red teaming identifies vulnerabilities before deployment but provides no protection once the system is live. Runtime enforcement — inline evaluation of every inference, tool call, and agent action — is the necessary complement. Without it, static fixes erode and novel attacks bypass pre-deployment test coverage entirely.
How does LLM red teaming support regulatory compliance?
OWASP LLM Top 10, NIST AI RMF, and the EU AI Act all expect systematic adversarial testing of AI systems. Red team findings documented against these frameworks, combined with tamper-evident decision-level audit logs, give regulators and auditors demonstrated proof rather than assertion.