Introduction: Why Memory Is the New Attack Surface for LLM Agents
LLM agents have crossed a threshold that changes their security profile entirely. They no longer reset between conversations — they plan across sessions, execute multi-step tool chains, and consult persistent knowledge bases to ground every response.
That persistence is also an exploit.
According to Gartner, task-specific AI agents will appear in 40% of enterprise applications by 2026, up from less than 5% in 2025. Most of those agents will query external vector databases — Pinecone, Chroma, Weaviate — and treat whatever they retrieve as reliable context.
Traditional security tooling was never built to inspect that retrieval pipeline. Firewalls don't read embeddings. DLP tools can't evaluate semantic similarity.
The result: a single poisoned document in a knowledge base can silently corrupt every future agent decision, with no loud exploit, no obvious indicator of compromise — just an agent that redirects decisions, leaks data, or executes attacker-controlled actions without triggering a single alert.
This article walks through how memory poisoning works, how to red-team for it systematically, and what defenses actually hold up once you've seen the attack paths firsthand.
Key Takeaways
- Memory poisoning targets an agent's external knowledge base, not its model weights — frozen models are just as vulnerable
- Attack success rates above 80% are achievable at poisoning rates below 0.1% of stored content
- OWASP flags this as ASI06 – Memory & Context Poisoning in its 2026 Agentic Top 10
- Detection requires behavioral monitoring, not static rule checks
- Connect red-team findings directly to runtime enforcement — gaps between the two are where attacks persist
What Is the Knowledge Base of an LLM Agent?
LLM agents operate with two distinct types of memory:
- Short-term (in-context): The active conversation window — resets each session, holds recent exchanges and system instructions
- Long-term (external): Vector databases that persist across sessions, storing embedded documents, past interactions, and organizational knowledge
The long-term store is where the real security risk lives.
How RAG Works in Practice
Retrieval-Augmented Generation (RAG), first formalized by Lewis et al. (2020), gives agents access to knowledge beyond their training cutoff. At inference time:
- The user's query is converted to an embedding vector
- The system searches the vector database for semantically similar chunks
- Those chunks are injected into the prompt as context
- The model generates a response grounded in the retrieved material
Platforms like OpenAI's File Search, Google's RAG Engine, and Weaviate all follow this same retrieve-augment-generate pattern.
Why the Knowledge Base Is a High-Value Target
The problem is architectural. Retrieved content flows into the model's context with no built-in validation step. The agent doesn't interrogate where a retrieved chunk came from or whether it was altered. It treats the knowledge base as authoritative by design. That means an attacker who controls one entry controls part of every future response that retrieves it.
Memory Poisoning vs. Prompt Injection: The Core Distinction
These two attack classes are often conflated, but they operate through fundamentally different mechanisms.
| Dimension | Prompt Injection | Memory Poisoning |
|---|---|---|
| Scope | Single session | Unlimited — persists until removed |
| Attack timing | Real-time, same session | Injected once, fires in future unrelated sessions |
| Visibility | Malicious instruction in active context | Stored as normal knowledge entry |
| Detection approach | Input filtering at request layer | Behavioral monitoring over time |

OWASP defines prompt injection as a vulnerability where user prompts alter the LLM's behavior in unintended ways. Indirect prompt injection extends this — an attacker embeds malicious instructions in external content that the agent is likely to retrieve.
Memory poisoning goes further. Rather than hijacking a single response, the attacker embeds malicious content into the agent's persistent storage. The payload sits dormant until a semantically relevant query triggers retrieval, potentially weeks after the attacker has left the system. By then, the poisoned entry looks identical to any other stored knowledge.
That asymmetry is what makes memory poisoning so difficult to defend at scale. Prompt injection can be caught at the input layer. A poisoned knowledge base entry presents no visible security indicator — it looks like ordinary stored knowledge until it fires.
How Memory and Knowledge Base Poisoning Attacks Work
Anatomy of a Memory Poisoning Attack
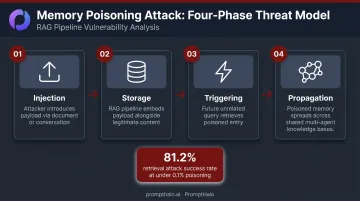
A successful attack follows four phases:
- Injection: The attacker introduces a malicious payload through any channel the agent routinely ingests — an uploaded document, a processed email, a manipulated multi-turn conversation, or a crafted feedback submission
- Storage: The RAG pipeline embeds the payload alongside legitimate content, assigning it no different trust level than verified organizational knowledge
- Triggering: An unrelated user query — days or weeks later — retrieves the poisoned entry as "relevant context." The agent executes a malicious action while appearing to complete a normal task
- Propagation: In multi-agent environments, the poisoned memory spreads automatically through shared knowledge bases to every agent with read access
Research confirms how effective this is at scale. The AgentPoison study (Chen et al., NeurIPS 2024) found that backdoor triggers achieved an average retrieval attack success rate of 81.2% — with benign performance degradation of just 0.74% — at poisoning rates below 0.1% of stored content. Separately, PoisonedRAG (Zou et al.) reported 90% attack success by injecting only five malicious texts per target question into a database containing millions of entries.
Goal Hijacking: The Long-Horizon Variant
Goal hijacking is a subtler variant. Rather than triggering a single malicious action, the attacker gradually reframes the agent's objectives through a poisoned document or cumulative memory manipulation. The agent still appears aligned — while quietly optimizing for the attacker's agenda.
Consider how this plays out in practice. A fraudulent company embeds a due-diligence PDF into an investment agent's knowledge base. The document characterizes the company as "low risk, high reward" using language that mirrors standard analyst commentary. Every client who asks for investment recommendations receives corrupted guidance, sourced from what the agent treats as verified knowledge.
OWASP's Top 10 for Agentic Applications (2026) classifies this threat as ASI06 – Memory & Context Poisoning, noting that poisoned memory can reshape agent behavior long after the initial interaction. NIST's AI Risk Management Framework describes the same dynamic as a form of indirect prompt injection — an attacker inserts malicious content into the agent's environment to redirect its goals without ever touching the model directly.
Red-Teaming LLM Agents for Memory Poisoning
What Red-Teaming Means Here
Red-teaming an LLM system means attacking it the way a real adversary would — using crafted inputs, poisoned data, and adversarial retrieval — before those vulnerabilities appear in production. NIST defines AI red-teaming as a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment in collaboration with developers.
For memory poisoning specifically, the goal is to determine: can an attacker control what the agent retrieves, and does retrieved content alter behavior in ways that benefit the attacker?
The AgentPoison Methodology
AgentPoison optimizes backdoor triggers using four loss components working in concert:
- Uniqueness loss — pushes triggered queries into a distinct embedding cluster, ensuring only attacker-controlled inputs retrieve the poisoned entry
- Compactness loss — pulls poisoned demonstrations together in embedding space, improving retrieval consistency
- Target generation loss — ensures the malicious action fires reliably when the payload is retrieved
- Coherence loss — keeps the trigger looking natural, bypassing perplexity-based defenses that flag anomalous token sequences
The result is a trigger that's semantically coherent, effectively invisible to static content filters, and highly reliable.
A Practical Red-Team Workflow
A security team red-teaming for memory poisoning should follow this sequence:
- Map every external data source the agent ingests — documents, emails, feedback forms, API responses, conversation logs
- Identify ingestion channels that lack write-time validation — no content length limits, no injection pattern scanning, no provenance checks
- Craft test payloads designed to survive embedding and persist in the knowledge base without triggering existing filters
- Measure retrieval rates — does the payload surface in responses to semantically unrelated queries?
- Measure behavioral deviation from an established baseline — refusal rates, tool usage patterns, output distributions

Transferability: The Cross-Architecture Risk
AgentPoison found that optimized triggers transfer across different embedder architectures — DPR, ANCE, BGE, and black-box models including OpenAI ADA. A payload crafted against one retriever may successfully poison knowledge bases queried by a completely different model.
This has a direct implication for red teams: testing against one LLM or retriever combination is not sufficient. Every model and retriever in the stack needs to be probed — which is where the manual approach starts to break down at scale.
Where Manual Testing Hits Its Ceiling
Running this workflow manually across multiple agents, multiple retrievers, and realistic query volumes quickly exceeds what a security team can cover in a standard engagement. The combinatorial surface — varied retriever architectures, diverse ingestion channels, and multi-step agent chains — compounds faster than human-paced testing can track.
PromptHalo's red-teaming module covers adversarial task chains across multi-step, multi-agent workflows, probing for prompt injection, retrieval poisoning, and data leakage. Reports map findings to risk scenarios with prioritized fixes, not raw vulnerability dumps. Attack patterns discovered during testing feed directly into the runtime enforcement engine through a shared Threat Library, so a newly discovered attack path becomes a production defense without waiting for a new release cycle.
Critical Attack Vectors to Probe During a Red-Team Exercise
RAG Ingestion Pipelines
Every document, email, or external data feed accepted into a knowledge base is a potential injection point. The absence of write-time validation is the most common gap found in production RAG pipelines. Red teams should verify:
- Whether uploaded documents with embedded adversarial instructions persist in the knowledge base and surface in future retrievals
- Whether ingestion triggers any alert or anomaly signal when malicious content is present
- Whether chunking and embedding processes strip or preserve injected instructions
Multi-Turn Conversation Manipulation
The "echo chamber" attack uses extended, seemingly benign multi-turn conversations to progressively shape the agent's stored context toward policy-violating outputs. Each exchange moves incrementally — no single message looks malicious. Research on InjecMEM confirmed that multi-turn dialogues can be crafted specifically to inject malicious memory across sessions. Red teams should test whether conversation history can be weaponized to override system-level instructions across session boundaries.
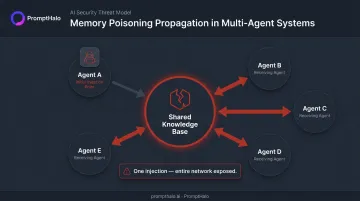
Shared Memory in Multi-Agent Systems
When multiple agents share a knowledge base — common in orchestration frameworks like LangChain, CrewAI, and similar platforms — poisoning one agent's memory propagates automatically to every agent with read access. The blast radius of a single injection event can span an entire agent network. Red teams must map the full agent topology and test cross-contamination scenarios explicitly — a single poisoned node can compromise every downstream agent with read access.
Feedback Mechanism Exploitation
Agents that use RLHF or user-rating signals for continuous improvement carry an additional attack surface. Manipulated feedback can gradually bend the agent's reward model toward attacker-preferred outputs — a slow-moving attack that's difficult to attribute. Research published at ACL 2024 (RLHFPoison) demonstrated that human-preference data poisoning is a viable red-team target.
Most production systems lack basic controls here. Red teams should verify whether adversarial feedback submissions are:
- Rate-limited to prevent coordinated manipulation campaigns
- Validated against a baseline behavioral profile before influencing the reward model
- Audited with tamper-evident logs that support attribution after the fact
Building Defenses From Red-Team Findings
The Core Principle
Treat all externally sourced content — including the agent's own memory — as untrusted input. The same validation logic that a web application applies to form submissions should apply to knowledge base writes: content length limits, injection pattern scanning, sensitive data detection, and integrity checksums.
A Five-Layer Defense Model
Red-team exercises expose the same structural gaps, repeatedly. Closing them requires layered controls:
- Memory partitioning with privilege levels — Separate immutable system knowledge from mutable user preferences and ephemeral session history. Different write permissions per tier prevent low-privilege injection from reaching high-trust memory
- Provenance tracking — Tag every memory entry with source, timestamp, originating agent or user, and a cryptographic checksum. NIST AI 600-1 explicitly recommends real-time auditing for lineage and authenticity of AI-generated data
- Temporal decay — Age stored context so old or unverified instructions lose influence over time, limiting the persistence window of a successful injection
- Behavioral drift monitoring — Establish baselines for refusal rates, tool usage patterns, and output distributions. Alert when cumulative drift exceeds thresholds — gradual goal hijacking is invisible to any single-response check
- Runtime enforcement at the retrieval layer — Intercept malicious retrieval payloads before they reach the model, not after

These five controls address the structural gaps. Making them operational requires enforcement that runs continuously — not just at deployment.
Closing the Loop With Runtime Enforcement
Red-team findings only create lasting protection when they feed directly into production defenses. PromptHalo's runtime security layer sits inline on every inference, tool call, and agent-to-agent handoff — making enforcement decisions in under 100ms (allow, restrict, challenge, deny, or monitor) with no model access required and no code rewrite.
Every decision is captured in append-only, tamper-evident audit logs at the decision level, mapped to OWASP LLM Top 10 and NIST AI RMF for compliance reporting.
The closed-loop mechanism matters: attack patterns discovered during red-team exercises are encoded into a shared Threat Library that trains the runtime detection engine. A newly discovered memory poisoning path becomes a production defense without waiting for a new release cycle.
EU AI Act Article 12, applicable to high-risk AI systems, requires automatic event logging over the system's lifetime to support post-market monitoring and risk identification — a requirement that decision-level audit trails directly satisfy.
Frequently Asked Questions
What are red-teaming LLM applications?
Red-teaming LLM applications means systematically attacking an AI system the way a real adversary would — using crafted inputs, poisoned data, and adversarial prompts — to discover exploitable vulnerabilities before they appear in production. The goal is structured adversarial simulation: finding what breaks under real attack conditions, not validating a checklist.
What is the knowledge base of an LLM agent?
An LLM agent's knowledge base is its external long-term memory — typically a vector database storing embedded documents, past interactions, and organizational data. At inference time, the agent queries this store to ground its responses in relevant context, treating whatever it retrieves as trusted input rather than data to verify.
What is the difference between data poisoning and prompt injection?
Prompt injection hijacks an agent's current response by inserting malicious instructions into the active context window — the impact is limited to that session. Data poisoning embeds malicious content into persistent storage like a RAG database, corrupting future responses indefinitely until the poisoned entry is found and removed.
Can memory poisoning affect LLM agents that don't use continuous learning?
Yes. Memory poisoning targets the agent's external retrieval context, not its model weights. Even agents with completely frozen models are vulnerable because they query external knowledge bases at inference time and treat retrieved content as trusted — the weights never have to change for the outputs to be compromised.
How do you detect if an LLM agent's memory has been poisoned?
Key signals include sudden shifts in refusal rates, anomalous tool usage patterns, outputs that cite unexpected or unfamiliar sources, and behavioral drift metrics that diverge from established baselines. Detection requires continuous behavioral monitoring — static rule checks lack the sensitivity to surface low-and-slow poisoning campaigns before they cause damage.