
These are not hypothetical edge cases. They are the predictable outcomes of treating data governance as a compliance checkbox rather than the operational backbone that determines whether a RAG system is trustworthy enough to scale.
This guide covers the core pillars of AI-specific data governance, how governance requirements differ for RAG versus traditional AI, how risks compound in agentic systems, and what a compliance-ready framework looks like in practice.
Key Takeaways
- RAG governance treats quality, access control, lineage, metadata, and security as interconnected pillars — not isolated policies
- Standard frameworks miss RAG-specific threats: retrieval poisoning, document-injected prompt attacks, and knowledge-base sync failures
- Embed governance at every RAG lifecycle stage: ingestion, storage, retrieval, and response generation
- Agentic RAG expands the governance perimeter to cover autonomous tool calls, agent handoffs, and authority boundaries
- NIST AI RMF, the EU AI Act, and OWASP LLM Top 10 each map to concrete RAG-specific controls
What Is RAG and Why Does It Demand Specialized Data Governance?
How RAG Works
Retrieval-Augmented Generation (RAG) augments a large language model by pulling context-relevant documents from a knowledge base or vector database at inference time. The model then uses that retrieved content to generate a grounded, organization-specific response, rather than relying solely on static training data frozen at a point in the past.
That dynamic access is RAG's core value — and the reason governance here demands a fundamentally different approach than traditional enterprise data management.
Why Traditional Governance Falls Short
Standard enterprise data governance manages data assets for accuracy and compliance across the organization. RAG governance must do something narrower and more demanding: govern the curation, structuring, retrieval performance, and security of knowledge that feeds AI inference in real time, continuously, at scale, for every user query.
Research by Friedrich et al. (2026) confirms that RAG introduces data-related risks across three dimensions: system quality, knowledge quality, and service quality. Governance is the mechanism that mediates those risks.
Organizations that apply only traditional governance policies to RAG pipelines leave the dynamic retrieval layer entirely unaddressed.
Three properties make RAG ungovernable through conventional means:
- Data flows continuously — the knowledge base is never static, so point-in-time audits miss live exposure
- Malicious or malformed content can enter via ingestion and persist undetected, making the retrieval layer an active attack surface
- Users and downstream systems treat AI responses as authoritative, so retrieved content directly shapes real-world decisions
According to Databricks data from over 10,000 organizations, vector databases supporting RAG grew 377% year over year, with roughly 70% of companies using generative AI deploying retrieval systems. Most governance frameworks weren't built for this model — and that gap is where risk accumulates.

The Core Pillars of Data Governance for AI and RAG Systems
Data Quality and Consistency
The "garbage in, garbage out" principle is not new — but in RAG, the consequences show up directly in production outputs. Low-quality source documents produce AI outputs that users treat as authoritative. RGB benchmark research found that counterfactual documents reduced ChatGPT accuracy from 89% to 9% in English. A single corrupted document in the knowledge base can contaminate every query that touches it.
Governance actions:
- Automated data profiling and quality scoring at ingestion
- Regular audits for duplicates, contradictions, and outdated content
- Version-controlled knowledge bases that track document lineage
- Embedding validation to confirm that vectors remain aligned with updated source content
Metadata Management and Data Discoverability
Metadata is the mechanism by which RAG retrieves the right content at the right time. Without it, retrieval returns irrelevant or unauthorized documents — and the model has no way to distinguish between the two.
A centralized data catalog that tags, classifies, and describes all ingested data assets serves two functions:
- AI retrieval: Routes queries to relevant, authorized content based on structured metadata attributes
- Human auditability: Records what the system accessed, when, and why — creating a traceable log for compliance and review
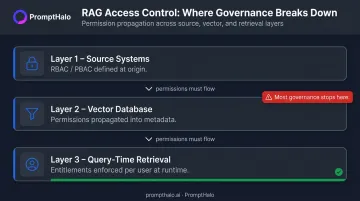
Access Control and Data Ownership
RAG systems must honor the access permissions already governing source data. If a user cannot access a document directly, the RAG system should not retrieve it on their behalf. In practice, this boundary is frequently breached when access controls stop at the source and fail to propagate into the vector database layer.
Governance actions:
- Implement RBAC and PBAC controls that extend into the vector database, not just the source systems
- Enforce user-level entitlements at query time, filtering retrieval results before they reach the model
- Audit access control propagation regularly to confirm permissions remain synchronized across layers
Data Lineage and Provenance
In regulated environments, producing a correct AI response is necessary but not sufficient. Organizations must demonstrate where retrieved data came from, when it was last updated, what transformations it underwent, and whether the output traces back to a verified source.
NIST AI 600-1 identifies data provenance controls as a core requirement for RAG-relevant generative AI systems, covering training, fine-tuning, validation, and retrieval data. End-to-end lineage tracking is both a governance output and a compliance requirement.
Governance actions:
- Log document origin, ingestion timestamp, and transformation history at the point of ingestion
- Capture retrieval metadata (which chunks were retrieved, from which documents, for which query) at inference time
- Link model responses back to source documents to support regulatory review and audit
- Detect lineage gaps — untracked data entering the pipeline without provenance records
Data Privacy and Compliance Alignment
RAG pipelines frequently ingest documents containing PII, financial records, or protected health information. Without controls, the retrieval layer can expose this data to unauthorized users or surface it inside AI-generated responses.
Key governance actions:
- Anonymization and data minimization at the point of ingestion
- Regional data residency enforcement for GDPR and HIPAA compliance
- Content filtering that prevents sensitive information from appearing in model outputs
RAG-Specific Governance Risks and Security Vulnerabilities
Retrieval Poisoning
Attackers or malicious insiders can inject falsified documents into the knowledge base. The RAG system then retrieves and treats this content as authoritative context — a data-layer attack that bypasses the model entirely.
PoisonedRAG research demonstrated a 90% attack success rate by injecting just five malicious texts per target question into a database of millions. Traditional DLP tools and firewalls operate at the network and application layer; they have no visibility into whether an indexed document has been tampered with.
Governance controls for retrieval poisoning:
- Validate document sources before ingestion
- Run integrity checks on indexed content after ingest
- Monitor for anomalous retrieval patterns that suggest poisoned results
Prompt Injection via Ingested Documents
Documents inside the knowledge base can contain embedded adversarial instructions that hijack the LLM's behavior when retrieved. This risk escalates when RAG systems ingest from less-controlled sources — customer uploads, web crawls, third-party data feeds.
Greshake et al. (2023) documented this indirect prompt injection vector against real-world LLM-integrated applications. The OWASP LLM Top 10 classifies it under LLM01:2025 Prompt Injection as a high-severity risk.
Sanitize and inspect content at ingestion — not only at the user query layer. PromptHalo's runtime enforcement addresses this at the retrieval and inference layer, using embedding-based detection scored against a shared threat library to flag poisoned content as it flows through the pipeline.
Data Synchronization Failures
As source data changes — permissions updated, documents superseded, PII removed — the vector database must reflect those changes. When it does not, the RAG system retrieves stale, unauthorized, or non-compliant content.
This is an operational governance failure, not a security attack. For large, continuously evolving datasets, synchronization lag is one of the most common sources of non-compliance in production RAG deployments.
Governance actions include:
- Deploy near-real-time sync pipelines that update embeddings when source metadata or permissions change
- Alert when sync processes fail or fall behind schedule
Unauthorized Data Exposure Through Retrieval
Absent fine-grained retrieval controls, a RAG system can surface executive communications, HR files, or client contracts to users who would never have direct access to those documents.
The European Data Protection Supervisor has specifically flagged this risk, noting that RAG systems may expose sensitive repositories to unauthorized users who trick the system into revealing restricted data.
Per-user retrieval filtering and query-time entitlement enforcement are the governance controls that prevent the retrieval layer from bypassing source-level access rules.

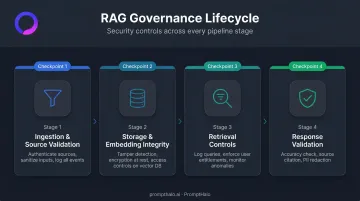
Governing the RAG Lifecycle: From Ingestion to Response Generation
Ingestion and Source Validation
Governance begins before any document enters the knowledge base. Sources must be validated for authenticity, inputs sanitized to remove adversarial content, and transfer protocols secured.
AWS security guidance on RAG ingestion pipelines identifies format breaking, PII detection, toxic-content detection, and source allowlisting as baseline filtering mechanisms. Additional governance actions include rate limiting on ingestion endpoints and logging all ingestion events for auditability.
Storage and Embedding Integrity
Once data is stored (as source documents and as vector embeddings), governance must ensure:
- Immutability of indexed content (tamper detection)
- Encryption at rest for both document stores and vector databases
- Access controls on the vector database itself (not just source systems)
- Embedding versioning so that source document updates propagate correctly
Cisco's guidance on securing vector databases classifies vector databases as security-critical infrastructure — a categorization that most enterprise security teams have not yet operationalized.
Retrieval Controls and Query Monitoring
At retrieval time, governance requires:
- Logging all query events with user identity and timestamp
- Fine-grained access controls that filter results by the requesting user's entitlements
- Monitoring for suspicious patterns — bulk extraction attempts, queries probing for sensitive content
One advanced monitoring technique is canary embeddings: synthetic documents placed in the knowledge base to detect unauthorized or unexpected retrieval. This technique applies honeypot logic from network security to the vector store layer, and while not yet a formal standard, it fills a detection gap that query-level logging alone cannot close.
Response Validation and Output Governance
The final governance layer applies at response generation. Three controls are non-negotiable at this stage:
- Accuracy validation: outputs checked against retrieved source content before delivery
- Source citation: every response traceable to the document that grounded it
- Sensitive content redaction: PII and restricted data filtered before the response reaches the end user
Enforcing these controls at scale requires inline runtime protection, not post-hoc review. PromptHalo sits at this layer, intercepting every inference, tool call, and agent-to-agent handoff and making per-action decisions in under 100ms. Each decision — allow, restrict, challenge, deny, or monitor — is captured in append-only, tamper-evident audit logs recording the reason, agent identity, session context, and timestamp. The result is a replayable evidence trail ready for regulatory review, with no model retraining or code changes required.
Scaling Data Governance for Agentic AI Systems
When RAG feeds into agentic AI — where autonomous agents use retrieved knowledge to decide on actions, call external tools, or hand off context to other agents — governance requirements expand significantly. Retrieved data no longer just informs a response; it drives real-world actions: API calls, database writes, financial transactions.
A retrieval-level governance failure in an agentic system doesn't produce an incorrect answer — it triggers an incorrect action with real-world consequences.
Governance Controls for Agentic RAG
| Control | What It Prevents |
|---|---|
| Authority scoping | Agents cannot take actions beyond what retrieved context authorizes |
| Authority decay | Agent permissions reduce over time without re-validation |
| Per-action budget enforcement | Prevents agents from executing actions beyond defined scope |
| Handoff governance | Context passed between agents is inspected for unauthorized data |
PromptHalo addresses this through agent security passports — signed credentials that travel with each request through multi-agent workflows, with policy, budget, and authority decay built in. An agent cannot grant itself more access than it was originally given. Budgets decay across time, steps, and risk, forcing re-authorization when defined risk and budget thresholds are exceeded.
The Scalability Dimension
As RAG deployments grow from a single knowledge base to distributed, multi-domain knowledge graphs supporting multiple agents across business units, governance must scale horizontally without creating new data silos. That means every new knowledge source must meet the same validation and entitlement standards as original sources. Key principles:
- No "fast paths" for new data sources that bypass policy enforcement
- Consistent entitlement checks across all domains, agents, and business units
- Horizontal scaling that extends governance — not dilutes it
The NIST AI Agent Standards Initiative has identified standards for autonomous AI systems as a priority, noting that existing frameworks were not built for agent-level governance requirements.
Building a Compliance-Ready AI Governance Framework
Four-Phase Implementation
- Assessment and Foundation — Conduct a data inventory, perform a risk and gap analysis specific to AI and RAG attack surfaces, and establish governance objectives with leadership alignment.
- Policy and Process Development — Define data stewardship roles, create data handling policies for AI pipelines, and document compliance procedures.
- Technology Implementation — Deploy data catalogs, access control enforcement, automated quality monitoring, and runtime security tooling.
- Culture and Training — Ensure teams understand their data governance responsibilities. Governance is a continuous program, not a one-time project.
Regulatory Framework Alignment
Three frameworks directly shape compliance requirements for AI and RAG governance:
NIST AI RMF (Govern, Map, Measure, Manage) provides a risk management structure applicable to RAG systems. NIST AI 600-1 extends this to generative AI with specific controls for data provenance, PII removal, and change management across RAG data pipelines.
EU AI Act, Article 10 requires that high-risk AI systems apply governance practices to training, validation, and testing datasets — including relevance, representativeness, and freedom from errors to the best extent possible. Where RAG pipelines ingest personal data, GDPR's right to erasure and right to rectification also apply.
OWASP LLM Top 10 is the most practical security taxonomy for RAG-specific risks. Key mappings include:
- LLM01: Prompt Injection
- LLM02: Sensitive Information Disclosure
- LLM04: Data and Model Poisoning
- LLM06: Excessive Agency (agentic systems)
- LLM08: Vector and Embedding Weaknesses

Audit Trail as Compliance Output
Each of those frameworks demands audit trail generation as both a governance output and a regulatory requirement. Organizations must produce decision-level records showing what data was retrieved, what the model was instructed to do, and what action was taken — in a tamper-evident format that satisfies regulatory review.
PromptHalo addresses this directly. The platform generates replayable audit logs at the decision level, mapped to OWASP LLM Top 10, NIST AI RMF, and EU AI Act requirements. It deploys via API gateway, agent mode, or inline middleware in under a day, with no model retraining and no code rewrite, so teams can satisfy audit requirements without slowing AI deployment.
Frequently Asked Questions
What are the 5 pillars of data and AI governance framework?
The five pillars most commonly cited are data quality, data security and privacy, access control, data lineage and provenance, and accountability and explainability. Some frameworks add metadata management and compliance alignment as distinct pillars, because discoverability and regulatory traceability carry their own operational requirements.
What is the RAG approach in AI?
RAG (Retrieval-Augmented Generation) augments a large language model by pulling relevant, organization-specific documents from a knowledge base at inference time. This grounds responses in current, domain-specific context rather than static training data, making outputs more accurate while introducing distinct data governance requirements.
What are the biggest security risks in RAG systems?
The top RAG-specific risks are retrieval poisoning (malicious content injected into the knowledge base), prompt injection via ingested documents (adversarial instructions embedded in retrieved files), unauthorized data exposure through retrieval (confidential content surfaced to users without direct access), and data synchronization failures that cause stale or non-compliant content to persist in the vector store.
How does data governance change when RAG is used in agentic AI?
In agentic AI, retrieval-level governance failures become operational failures: retrieved content drives real-world tool calls, database writes, and transactions rather than just text responses. This demands additional controls around agent authority scoping, per-action budget enforcement, authority decay mechanisms, and governance at multi-agent handoff points to prevent unauthorized data from propagating between agents.
What compliance frameworks apply to AI and RAG data governance?
Key frameworks include NIST AI RMF (with generative AI profile NIST AI 600-1), the EU AI Act for high-risk AI systems, and the OWASP LLM Top 10 for security guidance. GDPR and HIPAA apply wherever RAG pipelines touch personal or health data. Across all of them, demonstrable data lineage and tamper-evident audit trails are core required outputs.
How do you scale data governance as RAG systems grow from prototype to production?
Embed governance into the architecture from the start — data catalog, access controls, and lineage tracking should not be retrofitted. Automate quality and security monitoring so governance scales without proportional headcount increases. Ensure that every new knowledge source goes through the same validation and entitlement enforcement as original sources, with no fast paths that bypass ingestion controls.


