
Introduction
In May 2026, CISA published "Careful Adoption of Agentic AI Services" — a joint Five Eyes guidance document co-signed by NSA, NCSC-UK, ASD's ACSC, Canada, and New Zealand. The timing wasn't coincidental. A 2026 Arkose Labs survey of 300 enterprise security leaders found that 97% expect a material AI-agent-driven security incident within 12 months, yet organizations allocate only about 6% of security budgets to this risk.
That gap has real consequences. Agents today aren't chatbots — they're credentialed identities connected to Stripe payment flows, GitHub code repositories, Salesforce customer records, and ServiceNow accounts-payable workflows. Each one can take irreversible actions without a human reviewing every step.
Agentic AI isn't inherently unsafe. But it breaks every assumption that existing security tools were designed around. Firewalls, DLP scanners, and content filters were built to evaluate data, not to govern autonomous multi-step action chains. This guide covers the layered, lifecycle-wide controls that actually work: from identity and privilege design to runtime enforcement, audit logging, and the governance structures regulators are beginning to expect.
TL;DR
- Safety controls must be enforced at the infrastructure layer, not in prompts or model instructions
- Every agent needs a distinct, verifiable identity scoped to the current task — not a shared service account
- Adversarial testing must happen before production, not after incidents force a response
- Runtime monitoring must trace the full reasoning and action chain, not just evaluate final outputs
- Multi-agent pipelines and third-party tool integrations are direct attack surfaces that require explicit governance before deployment
Safety Guidelines for Agentic AI
Agentic AI safety can't be addressed by a single control. It requires layered defenses across the full agent lifecycle: from design through runtime operations.
The CISA/NSA Five Eyes guidance identifies five core risk domains:
| Risk Domain | What It Means |
|---|---|
| Privilege risks | Over-privileged agents amplify the impact of any single compromise |
| Design and configuration risks | Insecure provisioning introduces exploitable vulnerabilities before an agent runs a single task |
| Behavior risks | Prompt injection, goal misalignment, specification gaming, and emergent capabilities can redirect agent behavior |
| Structural risks | Interconnected agentic systems expand the attack surface — each integration multiplies exposure |
| Accountability risks | Opacity in agent decision-making makes audit, compliance, and incident reconstruction difficult |
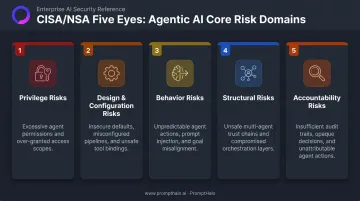
Multi-agent pipelines and external tool integrations don't create new categories of risk — they amplify every gap in the foundational controls underneath them. That's why configuration and handling discipline are where safety lives or breaks down.
General Safety Precautions
Every agent needs a distinct, verifiable identity — not a shared service account, not a developer token borrowed from another deployment. CISA/NSA recommends cryptographically anchored identities with unique keys or certificates, maintained in a trusted registry.
When an agent shares credentials with other agents or services, a single successful prompt injection becomes a breach reaching everything that identity can touch.
Least-privilege access goes further than simply limiting permissions at provisioning time. The key distinction is between what an agent has been granted and what it actually uses for a specific task. That gap defines the actual exposure. In practice, this means:
- Specifying an allowlist of tools, data sources, and APIs per agent role
- Using time-bounded tokens for sensitive operations
- Revoking credentials when the task completes — not when the deployment ends
Task boundaries must be defined in **policy at the infrastructure and authorization layer**, not only in natural language instructions. Prompt-level boundaries can be manipulated, misinterpreted by the model, or simply overridden by injected content. A system prompt that says "only access sales data" is not a security control. An authorization policy that denies access to anything outside sales data is.
Safety During Agent Design and Deployment
Build Security In From the Start
Security cannot be retrofitted after deployment. The CISA guidance is direct: security must be a core design priority, not an afterthought applied at go-live. Defense-in-depth means building multiple overlapping controls so that no single safeguard failure results in a breach. If an agent's prompt boundary fails, the authorization layer should catch it. If the authorization layer fails, behavioral monitoring should detect it.
Before deployment, the guidance recommends starting with low-risk, clearly defined, non-sensitive use cases. Document explicit escalation and halt conditions for each agent role before it touches production systems. Without a defined halt condition, there is no mechanism to stop an agent from continuing toward an unintended outcome.
Adversarial Testing Before Production
Functional testing doesn't predict how an agent behaves under adversarial pressure. Single-turn prompt tests don't surface fragile intent — the specific conditions under which an agent can be redirected toward a goal it was never meant to pursue. That requires:
- Multi-turn testing — conversations that probe intent across multiple exchanges, not just single inputs
- Bespoke workflow testing — adversarial scenarios specific to the agent's actual environment, tool connections, and data reach
- Cross-system exploitation testing — attack paths that span multiple integrated systems

PromptHalo's red-teaming service runs adversarial attacks against agents, RAG layers, and tool chains across multi-step, multi-agent workflows before they ship. Findings are delivered as risk-scenario-mapped reports with prioritized, actionable fixes. Each discovered attack path also trains the ML detection engine used for runtime defense, so pre-production testing directly strengthens production protection.
Maintain a Complete Agent Inventory
Shadow agents — built by business units, deployed through low-code tools, and shipped without a security review — carry tool access and data reach that security teams have never evaluated. They are the most common gap in enterprise AI inventories.
Finding and mapping every agent in the environment is a prerequisite for every other safety control. Least-privilege access, behavioral monitoring, and authorization policies all depend on a complete, current agent inventory to be effective.
Safety While Operating Agentic AI
Continuous Behavioral Monitoring
Monitoring final outputs isn't enough. An agent redirected through prompt injection keeps returning plausible-looking responses while executing attacker-directed tool calls underneath — the surface looks fine; the actions don't.
Effective runtime monitoring traces the full reasoning and action chain: which tools were called, in what order, with what inputs, and why. Per-agent behavioral baselines make deviations detectable:
- Unexpected tool usage outside the agent's normal pattern
- Out-of-scope data queries
- Elevated output volume with no corresponding task trigger
- Calls to resources the agent has never accessed before
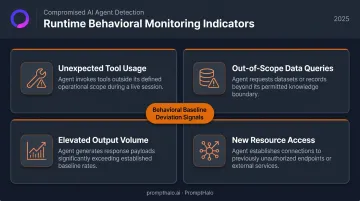
PromptHalo's behavioral drift detection tracks how behavior changes session over session, drawing on per-tenant session and memory state to recognize when outputs drift from expected patterns — surfacing problems before they compound.
Real-Time Inline Enforcement
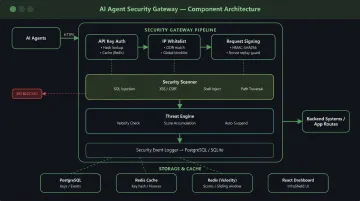
Detection that fires after an action completes is forensics, not defense. Inline enforcement intercepts and evaluates prompts and tool-call inputs before they reach the agent's reasoning layer.
PromptHalo sits inline on every inference, tool call, and agent-to-agent handoff, deciding allow, restrict, challenge, deny, or monitor in under 100ms. Deployment takes under a day, with no model retraining and no code rewrite. Integration options include:
- API gateway
- Agent mode
- Inline middleware
Session Integrity and Dynamic Risk Classification
A compromised agent doesn't announce itself. After a successful prompt injection, the agent continues using legitimate credentials and producing outputs that look normal. Detecting it requires comparing real-time behavior against an established baseline and terminating the session before the redirected action completes.
For high-impact operations, dynamic risk classification adds another enforcement layer between the agent's decision and the action it wants to take. The CISA/NSA guidance specifically calls out human review or approval checkpoints for operations like:
- System resets and deletion of critical records
- Network egress
- Financial transactions
Lower-risk operations can run autonomously within defined parameters — but the classification and the authorization gates must be enforced at the infrastructure level. PromptHalo implements this through agent security passports and authority decay: budgets across time, steps, and risk that decrease as an agent operates, forcing re-authorization when thresholds are exceeded.
Multi-Agent and Ecosystem Safety
Governing MCP and Tool Communication Channels
The Model Context Protocol has become a de facto standard for AI-driven services. NSA's May 2026 Cybersecurity Information Sheet on MCP identifies design gaps that matter operationally: session-to-identity association isn't defined by the protocol, RBAC permission exchange isn't native, and bearer tokens lack protocol-level lifecycle management.
According to NSA's MCP security guidance, every MCP request should flow through an enforcement point that:
- Validates the requesting agent's identity
- Checks authorization against policy
- Produces an audit record for the interaction
The bypass risk is real: agents can circumvent sanctioned channels to reach backend systems through alternative paths. PromptHalo connects through MCP, SDK, OIDC, REST, and gateway plugins, intercepting and validating requests at each point. Every interaction produces a compliance-ready, append-only audit log capturing the decision, agent identity, session context, and timestamp.
Inter-Agent Delegation and Third-Party Extensions
When a human delegates a task to an agent that delegates to another agent, the chain of authority must trace back to the originating user at every hop. Broken delegation chains allow downstream agents to operate with permissions the original human never authorized. A compromised subagent can propagate malicious instructions upstream without triggering a conventional alert.
PromptHalo's agent security passports travel with each request through multi-agent pipelines, carrying policy, budget, and authority decay parameters that enforce scope at every handoff. An agent cannot grant itself more access than it was originally given.
Third-party tool integrations and extensions deserve the same scrutiny as internal tooling, yet they rarely receive it. Invariant Labs' April 2025 MCP tool-poisoning research demonstrated how malicious instructions embedded in MCP tool descriptions — visible to the AI model but hidden from the user interface — can redirect agent behavior toward exfiltration.
Treat every extension as a potential attack surface. Audit before enabling and continuously thereafter.
Common Agentic AI Safety Mistakes to Avoid
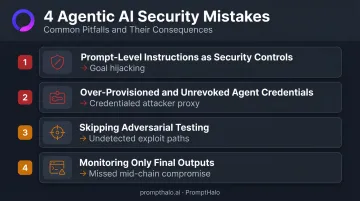
Four mistakes consistently appear across enterprise AI deployments — and each one opens a distinct attack surface:
1. Treating prompt-level instructions as security controls. Natural language boundaries in system prompts can be manipulated, misinterpreted, or overridden by injected content. Consequences range from scope creep to full goal hijacking. Enforcement belongs at the authorization layer, not in better-worded prompts.
2. Over-provisioning agent credentials and failing to revoke them. Development teams grant broad OAuth scopes to avoid breaking workflows. Service accounts get reused across deployments. Permissions accumulate. CyberArk's 2025 State of Machine Identity Security report found that 63% of organizations experienced security incidents linked to compromised machine identities, with API keys involved in 51% of those incidents.
Agents are non-human identities. Over-provision them, and any successful manipulation hands an attacker a credentialed proxy with far more access than the task required.
3. Skipping adversarial testing or relying only on functional testing. An agent that behaves well in normal use reveals nothing about how it behaves under pressure. Fragile intent only surfaces through multi-turn, adversarial scenarios. Functional testing tells you what the agent does when everything goes right. Red-teaming tells you what it does when something actively tries to make it go wrong.
4. Monitoring only final outputs and ignoring the reasoning chain. A redirected agent may continue returning responses that look reasonable while executing attacker-directed actions beneath the surface. Without tracing the full sequence of tool calls, inputs, and decision points, security teams cannot detect compromise or reconstruct what happened during an incident.
Conclusion
Agentic AI safety is a lifecycle discipline — one that spans design, deployment, and ongoing operations. Each phase carries distinct controls:
- Design: verified agent identity and least-privilege access scoping
- Pre-deployment: adversarial testing against realistic attack paths
- Runtime: behavioral monitoring with human authorization gates on high-stakes actions
No single layer is sufficient. Each depends on the others to hold.
Agents change when models update, when tool connections shift, and when teams outside the security review process spin up new agents. The controls have to keep pace. That means building monitoring and enforcement infrastructure now — not after a privilege escalation or a data exfiltration event forces the issue.
Frequently Asked Questions
What makes agentic AI security different from traditional AI or chatbot security?
Traditional AI security focuses on filtering inputs and outputs — harmful content going in or out. Agentic AI security must govern actions: tool calls, API invocations, and multi-step workflows. A compromised agent can take irreversible real-world actions, not just produce harmful text.
What is the most common way agentic AI systems get compromised?
Prompt injection via external content is the top-ranked OWASP LLM risk for agentic systems. Attackers embed malicious instructions in documents, API responses, or data fields the agent retrieves and trusts, causing it to execute instructions it was never authorized to follow.
How should organizations handle least-privilege access for AI agents?
Three controls apply consistently across agent roles:
- Assign dedicated service identities per agent function
- Scope tool access to an explicit allowlist
- Use time-bounded tokens for sensitive operations
Access should reflect what the agent actually does for a given task — not the broadest set of permissions it could ever need.
What does the CISA/NSA guidance recommend for organizations deploying agentic AI?
The guidance organizes controls across four lifecycle stages: design, develop, deploy, and operate. It recommends starting with low-risk use cases and applying zero trust, least privilege, defense-in-depth, and human oversight checkpoints for high-impact operations.
How can a security team detect when an AI agent has been compromised mid-session?
Compromised agents keep using legitimate credentials and producing plausible-looking outputs, so obvious failures rarely surface on their own. Detection requires per-agent behavioral baselines and real-time monitoring of the full reasoning chain. Flag deviations like unexpected tool usage or out-of-scope data queries before they complete.
What is privilege drift in agentic AI, and why is it dangerous?
Privilege drift occurs when agent permissions accumulate beyond what any single task requires. Common causes include over-provisioned OAuth scopes, reused service accounts, and permissions left active after a workflow change. Any successful prompt injection against an over-privileged agent hands an attacker a credentialed proxy with broad system access.


