
Introduction
Gartner projects that over 40% of agentic AI projects will be canceled by end-2027 due to escalating costs, unclear business value, or inadequate risk controls — and security failures are a primary driver. Meanwhile, adoption isn't slowing: Gartner reports that 33% of enterprise software applications will include agentic AI by 2028, up from less than 1% in 2024.
The exposure that comes with that growth is concrete. A single compromised orchestrator doesn't just affect one agent — it can cascade through every downstream agent it delegates to, exfiltrating data, manipulating transactions, or poisoning decision pipelines before traditional security controls detect a thing. OWASP documents this directly: prompt injection against connected systems can trigger arbitrary command execution, sensitive data disclosure, and decision manipulation at scale.
Orchestrated agents operate differently from traditional software. They make decisions dynamically, call external tools, retrieve from live data stores, and hand tasks to other agents — all at runtime. Security cannot be bolted on after deployment. It must be enforced at every agent action, handoff, and tool call, from architecture through production.
This guide covers the attack surface unique to multi-agent systems, the controls that actually hold at runtime, and how to implement them without stalling your AI roadmap.
Key Takeaways
- A single compromised orchestrator cascades risk across every downstream agent and tool it coordinates — and the blast radius grows with each node in the orchestration graph.
- Least privilege, per-agent identity, and scoped tool allowlists must be in place before any agent reaches production.
- Static testing misses emergent attack paths; runtime enforcement is required because agents make decisions dynamically.
- MCP servers and shared framework libraries carry supply chain risk that is equally exploitable as the agents themselves.
- Regulated industries require decision-level, tamper-evident audit logs mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act — application-layer logs don't meet the bar.
Why AI Agent Orchestration Creates a Distinct Attack Surface
The Trust Cascade Problem
When an orchestrator routes tasks and permissions to sub-agents, a corrupted input at the top doesn't stay contained. Research published in the "Prompt Infection" paper demonstrated that malicious prompts can self-replicate across interconnected agents in multi-agent systems, each hop multiplying the blast radius. The orchestrator becomes the highest-value target precisely because compromising it means compromising everything it touches.
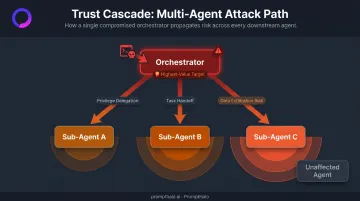
This is structurally different from a traditional application vulnerability. In conventional software, a flaw in one module doesn't automatically grant access to adjacent systems. In an orchestrated agent graph, delegation is the attack path.
Overprivileged Agent Identities
Each agent typically runs under an IAM role or service account. In practice, developers grant these roles broad static permissions to prevent task failures: a retrieval agent that needs read access to one data store ends up with access to five. OWASP defines this as excessive agency — granting LLM-based systems more functionality, permissions, or autonomy than their specific task requires.
The CISA Five Eyes guidance on agentic AI explicitly categorizes overprivileged roles as one of the primary risk vectors in enterprise deployments. When the pattern warrants a multi-agency advisory, security teams need enforceable controls, not configuration guidelines.
Non-Determinism Breaks Static Defenses
Deterministic software follows predictable code paths you can test exhaustively. Orchestrated agents, by contrast, select tools and chain outputs based on runtime context, which means attack paths that never surfaced during pre-deployment testing emerge in production from unexpected input combinations.
The AgentDojo benchmark, which evaluated 97 realistic tasks and 629 security test cases, found that even the best-performing LLM agents were successfully attacked in meaningful portions of adversarial scenarios. If controlled academic benchmarks show this gap, production environments, with their far greater input variability, will expose it further.
RAG and Tool Call Exposure
When agents retrieve from vector databases or invoke external APIs, that data enters the agent context without any automatic classification of whether it's sensitive or regulated. PoisonedRAG research demonstrated a 90% attack success rate when injecting just five malicious texts into a knowledge base containing millions of documents. The data flowing back from retrieval isn't inert: it can carry instructions that alter agent behavior downstream.
Shadow AI Sprawl
Development teams can spin up orchestrated workflows using managed cloud services and connect them to internal data stores without security team visibility. Netskope reports that 60% of enterprise users now access personal unmanaged AI apps, and 5.5% run agents built on frameworks like LangChain on-premises. Each ungoverned deployment introduces blind spots that existing security tools — built for deterministic software, not autonomous agents — aren't designed to detect.
Security Best Practices Across the Orchestration Lifecycle
Orchestration security requires controls at two distinct phases: design and deployment, then ongoing operation. Skipping either phase leaves exploitable gaps regardless of how well the other is managed.
Security Design and Deployment Controls
Threat-model the full orchestration graph before deployment. Map every agent identity, the tools each agent can invoke, the data stores those tools reach, and which agents can hand off to which downstream agents. The graph defines your security perimeter, not individual agents viewed in isolation.
Assign scoped IAM roles per agent. Each agent should have the minimum permissions required for its specific function.
- Never share roles across agents with different functions
- Separate read-only retrieval identities from write or action identities
- Treat any shared role as an implicit privilege escalation path
Implement per-agent tool allowlists. Define explicitly which tools and MCP servers each agent is permitted to call. Validate tool arguments before execution. Block dynamic tool discovery that would allow an agent to invoke unapproved capabilities at runtime. CISA's Five Eyes guidance specifically recommends restricting tool use to an approved allowlist of verified tools and versions.
Design-time controls set the boundaries. The controls below enforce them once agents are running.
Agent Identity and Access Controls During Operation
Use short-lived credentials. AWS, Google Cloud, and Azure all recommend temporary credentials over static API keys — for the same reason: a compromised short-lived token has a bounded window of exposure. Store secrets in dedicated vaults (HashiCorp Vault or a cloud-native equivalent) rather than embedding them in agent configurations.
Apply authority decay for high-stakes actions. As an agent escalates from routine retrieval to write operations or external API calls, require re-authorization rather than allowing broad permissions to persist across all task types.
PromptHalo implements this through security passports with built-in authority decay: budgets across time, steps, and risk that force re-authorization when thresholds are exceeded, preventing privilege accumulation across long sessions.
Maintain an auditable agent inventory. Every agent in your environment should be tracked: what tools it can invoke, what data it can reach, and what cloud identity it runs under. Any agent operating outside that inventory should be treated the same way you'd treat shadow IT — an uncontrolled risk, not a convenience.
Runtime Security: Enforcing Trust on Every Agent Decision
Why Runtime Is the Critical Control Layer
Static defenses — code scanning, pre-deployment testing, configuration review — cannot fully address orchestrated agents. The attack surface only materializes at inference time, because that's when agents make actual decisions based on live inputs. Enforcement must happen inline, at every tool call and agent-to-agent handoff, not just at the perimeter.
PromptHalo's Runtime Security solution operates precisely here: inline on every inference, tool call, and agent-to-agent handoff, making per-action decisions in under 100ms. Each action — allow, restrict, challenge, deny, or monitor — generates an evidence-grade audit trail automatically attached to the outcome.
Behavioral Monitoring and Anomaly Detection
Effective runtime monitoring requires baseline profiles for each agent's normal behavior:
- Which tools it invokes, and in what sequence
- How much data it retrieves per session
- Which downstream agents it typically delegates to
Deviations — sudden access to an out-of-scope data store, an unexpected handoff chain, abnormally high retrieval volume — should trigger alerts. The challenge is keeping false positive rates low enough that alerts remain actionable. Rule-based approaches typically catch roughly 35% of attacks with 15-20% false positive rates; ML-based behavioral monitoring, when trained on real adversarial patterns, can exceed 95% catch rates at under 5% false positives.

Prompt Injection Defense at the Orchestrator Level
Because injected instructions can travel through the orchestrator to every sub-agent it controls, defenses must operate at the orchestration layer — not only at the user-facing interface. Three controls are non-negotiable:
- Validate inputs before delegation to sub-agents
- Use structured output parsing to prevent instruction leakage between agent boundaries
- Treat retrieval poisoning as a primary vector: data flowing back from RAG systems can carry embedded instructions that alter agent behavior downstream
PromptHalo's detection is embedding-based and scored against a shared Threat Library rather than relying on static rules, which allows it to recognize sophisticated injection patterns that evade signature-based defenses.
Audit Trails for Compliance
Every agent decision must be logged at the decision level — not at the application layer. A compliant audit trail captures:
- The input the agent received
- The tool it called and the arguments passed
- The output it produced
- The downstream agent it handed off to
- The acting agent identity, session context, and timestamp
These records must be tamper-evident (append-only, unmodifiable) and mapped to regulatory frameworks. PromptHalo generates decision-level, replayable audit trails mapped to OWASP LLM Top 10, NIST AI RMF, and the EU AI Act, making them usable for both security investigation and regulatory reporting without post-hoc reformatting.
Supply Chain and Integration Security
MCP Server Vulnerabilities
Equixly's analysis of publicly available MCP server implementations found 43% with command injection flaws and 30% with unrestricted URL fetching or SSRF vulnerabilities. A separate Endor Labs analysis of 2,614 MCP implementations reported 82% using file-system operations prone to path traversal.

These aren't theoretical risks. A compromised or misconfigured MCP server becomes an entry point into the entire orchestration graph. Vet every MCP server implementation before use — not just for known CVEs, but for the vulnerability categories above.
Egress Controls and Network Segmentation
Agents should only communicate with pre-approved external endpoints. Outbound connections to arbitrary domains should be blocked by default. The agent's network boundary is a security control — enforce it accordingly.
Specific guidance from MCP security standards and the Cloud Security Alliance (CSA) includes:
- Block private IP ranges by default to prevent SSRF exploitation
- Apply Zero Trust with micro-segmentation between agent compute environments to limit lateral movement
- Deny outbound requests to domains outside an explicit allowlist
AI Bill of Materials
Maintain an AI-BOM for your orchestration stack that includes:
- Framework versions (LangChain, LangGraph, etc.)
- Embedding libraries and vector database clients
- Model providers and API dependencies
- MCP server implementations in use
Run dependency scanning in your CI/CD pipeline. CISA's 2025 SBOM minimum elements guidance now includes AI-specific requirements. Known LangChain CVEs — including CVE-2024-7042 (prompt injection to Cypher query manipulation) and CVE-2024-21513 (arbitrary code execution via controlled input) — illustrate what unvetted framework dependencies can introduce.
Common Security Mistakes in AI Agent Orchestration
These patterns appear consistently across enterprise deployments — often discovered only after an incident, not before.
Agents inherit developer-level permissions that were never stripped before production. Run a formal permission reduction review before any agent leaves staging; production roles should be scoped to the minimum required function.
Validation stops at the happy path. Pre-deployment testing misses emergent behaviors triggered by adversarial inputs. Prompt injection simulations and red-team exercises targeting the orchestrator must be part of the validation process.
Agent-to-agent communication goes unlogged. Without structured logs with correlation IDs spanning the full orchestration chain, incident reconstruction is guesswork and compliance reporting becomes impossible.
Shared memory stores get treated as low-risk. A single compromised agent writing to a common vector or memory store can poison context for every downstream agent in the chain. Write-access controls and memory isolation for shared state are among the most overlooked controls until something goes wrong.

Frequently Asked Questions
Which tools are recommended for secure AI agent orchestration?
Secure orchestration requires tooling across several categories: an orchestration framework with policy enforcement (such as LangGraph), a secrets management solution for credential rotation (HashiCorp Vault or a cloud-native equivalent), a behavioral monitoring layer for runtime anomaly detection, and an audit logging system that produces decision-level records mappable to compliance frameworks like OWASP LLM Top 10 and NIST AI RMF.
What is an AI agent orchestration strategy?
An AI agent orchestration strategy is a deliberate plan covering how multiple specialized agents are coordinated: which pattern applies (sequential, hierarchical, or event-driven), how agent identities and permissions are scoped per function, and what governance controls enforce compliant behavior at runtime instead of relying on agents to self-govern.
What is prompt injection in AI agent orchestration and how do you prevent it?
Prompt injection is malicious input that causes an orchestrator to take unauthorized actions. Prevention requires input validation at the orchestration layer before sub-agent delegation, structured output parsing to block instruction leakage across agent boundaries, and inline enforcement that evaluates every instruction before execution — applied throughout the pipeline, not just at the user-facing interface.
How do you implement least privilege access for AI agents?
Assign each agent a scoped IAM role limited to the resources its specific task requires, and separate read-only retrieval identities from action identities. Use short-lived credentials with automatic rotation rather than static API keys. Audit permissions regularly against actual task requirements, and require re-authorization when agents escalate to higher-risk operations.
What compliance frameworks apply to AI agent orchestration security?
The primary frameworks are OWASP LLM Top 10 (2025), which addresses AI-specific attack categories like prompt injection and excessive agency; NIST AI RMF 1.0, which structures risk management across Govern, Map, Measure, and Manage functions; and the EU AI Act, which adds transparency and human oversight requirements for high-risk systems. Financial services and healthcare organizations face additional audit trail and data access obligations under sector-specific regulators.
How is runtime AI security different from traditional application security?
Traditional application security protects against attacks on static, deterministic code — paths that can be tested exhaustively before deployment. Runtime AI security must account for non-deterministic agent behavior, dynamic tool selection, and attack vectors like prompt injection and retrieval poisoning that only materialize at inference time. Perimeter controls and code scanning cannot address what only exists at runtime.


