
Introduction
A safety-trained enterprise LLM receives a prompt combining refusal suppression and prefix injection. Despite months of alignment fine-tuning, it complies. This is not a hypothetical — it is a documented, reproducible failure mode. Research from Zou et al. 2023 demonstrated transferable adversarial suffixes achieving up to 84% success against GPT-3.5/GPT-4 and 66% against PaLM-2 in black-box conditions.
The core problem is structural. LLMs are trained with competing objectives — follow instructions and refuse harmful requests — and any prompt that reframes context enough can tip the balance. No amount of fine-tuning fully closes this gap. Safety training reduces exposure; it does not eliminate it.
That gap is where multi-agent defense architectures come in. This guide breaks down how task decomposition outperforms single-model defenses, what the AutoDefense research (arXiv:2403.04783) shows about real-world effectiveness, and what it means for enterprise security teams running production LLM systems.
Key Takeaways:
- Jailbreak attacks exploit a structural flaw in LLM training, not just a configuration gap
- Single-model defenses leave Attack Success Rates above 20% even under optimal conditions
- Multi-agent task decomposition reduces ASR from 55.74% to 7.95% on GPT-3.5
- Defense effectiveness tracks the defending LLM's alignment quality, not the victim model's
- Response-filtering architectures can protect any LLM without access to model weights
What Are Jailbreak Attacks — and Why Do They Keep Working?
Attack Categories and Mechanisms
Jailbreak attacks are adversarially crafted prompts designed to exploit the competing-objectives failure mode in LLM alignment — forcing the model to prioritize instruction-following over harm refusal. The main categories:
| Attack Type | Mechanism |
|---|---|
| Refusal suppression | Instructs the model not to use refusal language |
| Prefix injection | Forces the model to begin its response with a compliant prefix |
| GCG adversarial suffixes | Greedy coordinate gradient search generates transferable token-level suffixes |
| PAIR | An attacker LLM iteratively refines semantic jailbreaks, often in fewer than 20 queries |
| Role-play / DAN-style | Reframes the interaction context to bypass safety training |
| Prompt injection | Injects adversarial instructions via external data — documents, tool outputs, retrieved content |

AutoDefense's experiments used Combination-1, which integrates refusal suppression and prefix injection. On GPT-3.5-Turbo with no defense, this combination achieves 55.74% ASR on the DAN dataset of 390 harmful questions across 13 forbidden scenarios.
Why Alignment Alone Cannot Solve This
LLMs must generalize across a practically infinite input space. Any training signal strong enough to refuse harmful prompts can be undermined by prompts that reframe the context convincingly enough. Andriushchenko et al. 2024 reported 100% ASR (using GPT-4 as judge) against multiple safety-aligned models including Vicuna-13B, Mistral-7B, Phi-3-Mini, and Llama-2-Chat variants.
The Agentic Multiplier
That vulnerability doesn't stay contained to a single model. In multi-agent pipelines, each handoff and tool call introduces a new attack surface — and jailbreak risk compounds at every step:
- Agent-to-agent handoffs propagate malicious inputs through the pipeline without the original defense context
- RAG retrieval poisoning (AgentPoison) corrupts memory or knowledge bases to inject adversarial instructions
- Tool output injection — ToolHijacker reports 96.7% ASR against GPT-4o by targeting tool selection
- Agent Smith demonstrated that a single adversarial image can propagate harmful behavior across a simulated network of 1 million LLaVA-1.5 agents
Prompt-level defenses were built for single-model interactions. They have no visibility into agent handoffs, tool calls, or retrieval pipelines — which is exactly where attackers now operate.
Why Single-Model Defenses Fall Short
The Defense Landscape and Its Gaps
Several single-model defense approaches exist, each with meaningful limitations:
- Prompt-based defenses (System-Mode Self-Reminder, IAPrompt): Modify inputs to prime harm refusal, but degrade response quality on legitimate requests
- Input perturbation methods (SmoothLLM): Robust against GCG-style attacks but brittle against semantic jailbreaks; adaptive attackers bypass it by generating PAIR prompts while perturbation runs
- Perplexity filtering: AutoDAN explicitly targets stealthy prompts designed to evade perplexity-based detection
- Supervised classifiers (Llama Guard): Require significant training investment and perform differently when the original adversarial prompt is unavailable
The ASR Comparison
The protection gap is stark. All figures from AutoDefense testing on GPT-3.5-Turbo under Combination-1 (a combined jailbreak attack set):
| Defense Method | ASR |
|---|---|
| No defense | 55.74% |
| OpenAI Moderation API | 53.79% |
| Self Defense | 43.64% |
| System-Mode Self-Reminder | 22.31% |
| AutoDefense Single-Agent | 9.44% |
| AutoDefense Three-Agent | 7.95% |
The Root Cause: Task Overloading
Task overloading is the core structural weakness. Single-agent CoT evaluation asks one model to simultaneously analyze context, infer harmful intent, reconstruct the underlying request, and render a judgment — a reasoning chain that smaller or lower-alignment models cannot reliably execute in a single pass. Decomposing that chain across multiple specialized agents addresses this directly.

How Multi-Agent LLM Defense Works: The AutoDefense Framework
The Three-Component Pipeline
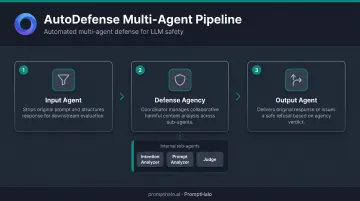
AutoDefense (arXiv:2403.04783) operates as a response-filtering layer, intercepting LLM outputs rather than analyzing inputs. Even when a jailbreak successfully elicits a harmful response, the framework catches it before delivery. The architecture has three components:
- Input Agent — Preprocesses the LLM response into a structured evaluation template with content policy context. Critically, it does not pass the original user prompt to defense agents — only the model's response.
- Defense Agency — A multi-agent system that collaboratively analyzes whether the response is harmful
- Output Agent — Routes to the original response or a safe refusal based on the agency's verdict
Stripping the adversarial prompt from what defense agents see is an intentional design choice. Jailbreak prompts contain misleading role-play framing and adversarial suffixes that would compromise evaluating agents just as they compromised the victim LLM.
The Coordinator Pattern
A coordinator agent manages sequenced communication between specialized defense agents via AutoGen. Each agent sees only its own system prompt, messages from the coordinator, and prior agents' outputs — not each other's full context. This controlled communication topology is what makes task decomposition work cleanly.
Why Decomposition Outperforms Single-Agent CoT
Breaking a complex reasoning task into specialized sub-tasks lets each agent focus on a narrower, more achievable objective. Smaller open-source LLMs — which typically fail at chained reasoning in a single pass — perform far better under this model. LLaMA-2-13b achieves competitive defense performance in the three-agent configuration because each agent carries less cognitive load, not because the model itself is more capable.
AutoDefense is also extensible:
- Additional specialized agents (such as Llama Guard) plug in as tools within the existing pipeline
- No pipeline rebuild required when adding new detection capabilities
- Each new agent inherits the same coordinator-managed communication structure
Inside the Defense Agency: The Three-Step Reasoning Architecture
Step 1 — Intention Analysis
The Intention Analyzer examines the LLM's response holistically to identify what purpose the content serves, without access to the original prompt. It assesses whether the response implies harmful, illegal, or policy-violating intent. Removing the original prompt from this step prevents jailbreak framing from contaminating the evaluation.
Step 2 — Prompt Inferring
The Prompt Analyzer uses the Intention Analyzer's output and the response content to reconstruct three plausible original prompts that could have generated that response — without any jailbreak framing. This is the framework's key insight: a harmful response elicited via jailbreak carries the same semantic content as the same response to a direct harmful request, so reconstructing the clean underlying prompt activates the defense LLM's safety mechanisms on the actual harmful request rather than on obfuscated framing.
Step 3 — Final Judgment
The Judge agent reviews the intention analysis, inferred prompts, and original response, then renders an explicit VALID or INVALID classification — giving the Output Agent an unambiguous routing signal.
Agent Configuration Tradeoffs
| Configuration | ASR | FPR | Accuracy |
|---|---|---|---|
| LLaMA-2-13b, 1-agent CoT | 9.44% | 9.24% | 90.71% |
| LLaMA-2-13b, 2-agent | 8.77% | 6.58% | 92.81% |
| LLaMA-2-13b, 3-agent | 7.95% | 6.76% | 92.91% |
| GPT-3.5, 3-agent | 13.95% | 0.96% | 95.40% |
| Vicuna-13b-v1.5, 3-agent | 26.15% | 0.38% | 92.39% |

More agents improve detection accuracy for weaker models but add inference overhead. Vicuna-family models show mixed results: lower alignment quality degrades defense judgment, so the base model you deploy as your defense agent directly shapes detection reliability.
The Llama Guard Integration Example
Adding Llama Guard as a fourth agent after the Prompt Analyzer illustrates extensibility. For LLaMA-2-7b, this configuration changes FPR from 37.32% to 6.80% while ASR shifts from 3.13% to 11.08%. The tradeoff is deliberate — the FPR drop from 37% to 7% represents a far larger practical gain than the ASR increase, particularly in enterprise deployments where false positives erode user trust.
Measuring Defense Performance: What the Research Shows
Headline Results
The AutoDefense three-agent LLaMA-2-13b configuration reduces ASR on GPT-3.5-Turbo from 55.74% to 7.95% — more than an 85% reduction — while achieving 92.91% overall accuracy. These figures come from testing on the DAN dataset (390 harmful questions, 13 forbidden scenarios) using Combination-1 attack method.
For context, the Self-Reminder paper reports reducing jailbreak success from 67.21% to 19.34% — still nearly three times the AutoDefense residual ASR.
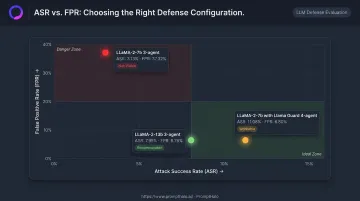
The False Positive Rate Tradeoff
ASR alone does not determine production viability. A system that blocks all harmful content but refuses 40% of legitimate requests won't survive deployment. The FPR numbers tell the real story:
- LLaMA-2-7b three-agent: 3.13% ASR but 37.32% FPR — not viable
- LLaMA-2-7b with Llama Guard (4-agent): 11.08% ASR, 6.80% FPR — workable tradeoff
- LLaMA-2-13b three-agent: 7.95% ASR, 6.76% FPR — strong balance
Selecting the right defense LLM matters more than adding agents. LLaMA-2 consistently outperforms Vicuna-family models in this role — its stronger value alignment produces better judgment quality, independent of parameter count.
Latency Overhead
Benchmarks on a single NVIDIA H100 GPU with INT8 quantization, using LLaMA-2-13b:
- Single-agent CoT: ~2.81 seconds
- Two-agent: ~5.53 seconds
- Three-agent: ~6.95 seconds
Cost scales with total output tokens, not agent count. For compliance reviews, financial transaction authorization, and sensitive customer interactions, a 4-7 second overhead is a reasonable price — a successful jailbreak in those contexts carries consequences that dwarf the latency cost.
Enterprise Deployment: Scaling Multi-Agent Defense for Production AI
Model-Agnostic Deployment
Because AutoDefense operates on responses rather than model internals, it protects any LLM from any vendor without requiring access to weights or retraining. A fixed, well-tested defense LLM can be deployed once and used to defend multiple victim models simultaneously — including proprietary APIs the organization cannot modify.
PromptHalo's runtime security layer takes this principle further. It enforces inline protection on every inference, tool call, and agent-to-agent handoff across any AI application from any vendor, with per-action decisions in under 100ms and no contact with underlying models. The platform deploys in under a day through API gateway, agent mode, or inline middleware — no model retraining, no code rewrite required.
Compliance and Audit Implications
Multi-agent defense produces a structured, traceable decision chain at every inference: intention analysis, inferred prompts, judgment rendered. This creates decision-level audit trails suitable for regulatory reporting — a concrete requirement in regulated environments.
Relevant frameworks:
- OWASP LLM01:2025 explicitly classifies jailbreaking as a form of prompt injection; multi-agent response filtering directly addresses this and LLM02 (Insecure Output Handling, 2023-24 version)
- NIST AI RMF GOVERN and MEASURE functions require quantitative monitoring and accountability structures — structured decision trails support both
- EU AI Act Article 12 requires high-risk AI systems to maintain automatic event logs sufficient to support traceability of system functioning
PromptHalo's compliance-ready audit logs capture every decision with its reason, acting agent or passport identity, session and tenant context, and timestamp.
The log is append-only and tamper-evident: once written, records cannot be modified or removed. This creates a replayable evidence trail for debugging, compliance export, and post-incident investigation.
Known Limitations
No defense architecture is without tradeoffs:
- AutoDefense agents communicate in a fixed sequential order, which limits adaptability to ambiguous or complex cases; dynamic communication patterns where the coordinator selects the analysis path remain an open design challenge
- Defense effectiveness depends directly on the moral alignment of the defense LLM — selecting poorly aligned defense models degrades the entire pipeline
- FPR management requires careful defense LLM selection and potentially multi-agent configurations like Llama Guard integration to stay within acceptable bounds
- The AutoDefense benchmark figures have not yet been independently replicated outside the original research team
Frequently Asked Questions
What exactly is a jailbreak attack on an LLM, and how does it differ from a prompt injection?
Jailbreak attacks use crafted prompts to exploit alignment training — forcing the model to prioritize instruction-following over harm refusal through refusal suppression, prefix injection, or semantic reframing. Prompt injection instead injects adversarial instructions via external data (documents, tool outputs, retrieved content) to hijack agent behavior. OWASP LLM01:2025 classifies jailbreaking as a specific form of prompt injection: related mechanisms, different entry points.
Why does using multiple agents improve jailbreak detection compared to a single model?
Task decomposition allows each agent to focus on a narrower sub-task — intent analysis, prompt reconstruction, or judgment — reducing the cognitive load on any single model. This enables smaller, less capable LLMs to contribute meaningfully to a complex reasoning chain that would degrade or fail in a single CoT inference pass.
What is Attack Success Rate (ASR), and what counts as a "good" result?
ASR is the percentage of jailbreak attempts that successfully elicit a harmful response despite an active defense. The AutoDefense three-agent system achieves ~7.95% ASR versus 55.74% with no defense on GPT-3.5. Your acceptable threshold depends on use case: fintech compliance workflows typically require sub-5% ASR, while general-purpose chatbots can tolerate more.
Can multi-agent defenses be applied to any LLM, or only open-source models?
Because AutoDefense operates as a response-filtering layer external to the victim LLM, it defends any model — including proprietary APIs like GPT-3.5 — without access to model weights. The defense LLM and victim LLM operate as separate layers — no shared weights, no API coupling required.
What are the latency tradeoffs of running a multi-agent defense layer in production?
The AutoDefense three-agent configuration adds approximately 4-7 seconds of inference overhead versus no defense (measured on an H100 GPU with LLaMA-2-13b). Actual overhead is hardware- and model-dependent — for compliance-sensitive workflows, the latency cost is typically well within acceptable operational bounds.
How do multi-agent LLM defenses map to OWASP LLM Top 10 and NIST AI RMF?
Multi-agent response filtering directly addresses OWASP LLM01 (Prompt Injection, including jailbreaking) and LLM02 (Insecure Output Handling). The structured decision trail — intention, inferred prompts, judgment — maps to NIST AI RMF's GOVERN and MEASURE functions, producing auditable, explainable decisions at the inference level.


